即使你不是工程師,也必須現在開始學習 Claude Code 的八個理由
第 1 篇,共 21 篇前陣子,我教會一位朋友使用 Claude Code。他完全不會寫程式,連 Terminal 是什麼都沒聽過。但他有一個很清楚的產品想法,一直找不到工程師幫他做。
兩週後,他把那個產品完整地實作出來了。
不是原型、不是 wireframe,是一個可以實際運作的產品。他全程沒有寫過任何一行程式碼——他只是用中文描述他要什麼功能,Claude Code 就幫他把程式寫出來、跑起來、除完錯。
你可能會想:那它跟 ChatGPT 到底差在哪?
一、你說中文,它寫程式
大部分人聽到「Claude Code」就先退了一步。Code,程式碼,那不是工程師的事嗎?
試試看跟它說這句話:「幫我把這個資料夾裡所有 PDF 的檔名,整理成一份清單。」
它會自己寫一段程式碼、跑完、把清單生出來。你完全不需要看懂那段程式碼。同樣的事在 ChatGPT 上做,它會把程式碼貼給你看,然後你得自己想辦法找地方執行。
你需要學的不是程式語言,而是怎麼把需求講清楚。但光是能下指令還不夠——如果它每次只能做一件事就停下來等你,那跟比較聰明的 Siri 也沒什麼兩樣。
二、它不是聊天機器人,它是 Agent
用過 ChatGPT 或 Gemini 的人對 AI 的印象通常是:問一個問題,得到一個答案。一來一回,像在傳訊息。
跟 Claude Code 說「幫我把這 20 張圖片都縮小到寬度 800px,轉成 WebP 格式,存到 output 資料夾」,看看會發生什麼。
ChatGPT 會給你一段教學。Claude Code 直接幫你做完,output 資料夾裡已經躺著 20 張處理好的圖片。中間如果某張圖片格式有問題,它會自己發現錯誤、換個方式處理、繼續往下跑。
聊天機器人給你資訊。Agent 幫你完成工作。
不過,這裡有一個問題。它能做事、能跑程式,但它做事的地方在哪裡?
三、它能直接操作你的電腦
一般的 AI 聊天活在瀏覽器的分頁裡,跟你的電腦之間隔著一道牆。它摸不到你的檔案、打不開你的資料夾、跑不了你的程式。
Claude Code 不一樣。它跑在你的終端機裡,你的整台電腦就是它的工作空間。
你跟它說「把桌面上那份報告裡的表格抓出來,轉成 Excel」。它真的去讀那份報告、解析內容、生成一個 .xlsx 檔案放在你指定的位置。不是給你教學叫你自己做——是它做完了,你打開檔案確認就好。
聽起來很強。但如果每次開啟它都要重新自我介紹、重新解釋你的工作背景和偏好,那你大概用三天就煩了。
四、它記得你是誰
跟 ChatGPT 聊天,每次開新對話都要重新說一遍:「我是做行銷的」「報告格式要用繁體中文」「我們公司用 HubSpot」。每次都要講,它每次都忘。
Claude Code 有一個叫 CLAUDE.md 的設定檔。你把工作背景、偏好、常用格式、公司的內部規範寫進去,每次啟動它都會先讀這份檔案。
你可以根據不同的專案類型,設計不同的 CLAUDE.md。寫部落格的專案有一份,管理客戶資料的專案有另一份,做產品開發的專案又是另一份。每份都帶著不同的背景知識和工作規範。
同一個工具,在不同的專案裡表現出完全不同的行為。它不是一個通用的 AI,它是你針對每一種工作量身定做的 AI。你甚至可以隨時告訴它「記住這件事」,下次開新對話,這些記憶還在。
但「認識你」只是第一步。你的工作領域有大量的專業知識——格式規範、品質標準、判斷邏輯——光靠一份設定檔裝不下。
五、它能學會你的專業領域
這就是 Skill 的用途。
Skill 是一份結構化的知識文件,告訴 Claude Code 在特定任務上應該怎麼做。我們團隊有一個「寫部落格文章」的 Skill,裡面定義了文章格式、語氣標準、該避免的用詞、品質評分方式。每次寫文章,Claude Code 就按照這份 Skill 的標準來執行。
把它想像成一本操作手冊。你把你最擅長的工作方法寫成 Skill,Claude Code 就能用你的標準幫你做事。
一個會計可以寫一份「月結報表」的 Skill。一個設計師可以寫一份「設計稿命名規範」的 Skill。一個業務可以寫一份「客戶提案信」的 Skill。這些 Skill 可以分享給同事,也可以跨專案使用。你的專業知識不再只存在你的腦袋裡。
到這裡,你有了一個認識你、懂你專業的 AI。但你每天的工作不只在一個工具裡完成——你要收 Email、更新 Notion、在 Slack 回報進度、到 Google Sheets 整理資料。這些工具之間,還是得靠你自己搬資料。
六、它能連接你用的所有工具
Claude Code 能透過 API、CLI 和 MCP 連接其他服務。
MCP(Model Context Protocol)聽起來很技術,概念卻很簡單——它是一個標準化的方式,讓 AI 可以直接跟其他軟體對話。裝了對應的 MCP 之後,你可以跟 Claude Code 說「把這份報告的摘要貼到 Slack 的 #marketing 頻道」,它就直接發出去了。
不用切換視窗、不用複製貼上、不用開 Zapier 設定自動化流程。一句話,串起原本要在三個工具之間跳來跳去的動作。
現在想像一下:你有一個理解你工作方式的 AI、它懂你的專業知識、還能操作你所有的工具。但如果你教會它的東西,每次都會消失呢?
七、一次教會,反覆使用
前面提到的記憶、Skill、MCP 連接,有一個共同的特性:它們是累積的。
你今天花 30 分鐘教會 Claude Code 怎麼處理月報,下個月只要說一句「跑月報」就好。你花一個小時把客戶分類的邏輯寫成 Skill,之後每次新客戶進來,它自動按照你的邏輯分類。
ChatGPT 的對話是一次性的,下次還是要從頭教。Claude Code 的設定是持久的,你投入的每一分鐘都在為未來節省時間。
三個月後回頭看,你會發現它已經知道你的工作方式、品質標準、常用格式和偏好工具。你投入的時間是線性的,但它帶來的時間節省是指數型的。
這就引出了最後一個問題:既然這些能力這麼強,為什麼是「現在」開始?
八、這是下一個必備技能
還記得 2000 年代初期,有人說「我的工作不需要用電腦」嗎?還記得 2010 年代,有人說「我不需要學 Excel」嗎?
我認為,「會不會用 AI 工具」正在成為跟「會不會用 Office」一樣基本的職場技能。差別在於,這次的轉變速度快得多。
現在學 Claude Code 的門檻,是它誕生以來最低的時候。社群資源在快速成長、操作介面越來越友善、Anthropic 持續在降低入門的摩擦。但工具的能力每週都在增加。
早一天開始,你就多累積一天的記憶、Skill 和工作流。等到身邊的人都開始用的時候,你已經有了三個月甚至半年的領先優勢。
這個優勢不是「我比你多認識一個工具」,而是「我的 AI 已經理解我的工作方式,而你的還在從零開始」。
從哪裡開始?
不需要一次學完所有功能。
第一步:安裝 Claude Code,用中文跟它說一件你今天本來要手動做的事。整理檔案、改檔名、合併資料——任何重複性的工作都行。
就這樣。從一件具體的小事開始。
當你第一次看到它在 15 秒內完成你原本要花 30 分鐘的工作,你就不需要任何人再說服你了。
我為什麼選擇 Claude Code
第 2 篇,共 21 篇為什麼不是 Codex?為什麼不是 Gemini CLI?為什麼不是 OpenClaw?
每隔幾天就有人問我這些問題。或者換個問法:「你怎麼不用 XXX?大家都在用欸。」
我的答案一直沒變過。但要解釋清楚為什麼,得從頭說起。
用了一年多,我對模型能力的判斷
我是 WordPress 工程師,寫了十幾年的 PHP。當 AI 開始能輔助寫程式的時候,我第一個反應不是興奮,是懷疑。畢竟 WordPress 的生態系有它自己的一套規則和慣例,這些不是通用的程式知識,而是你要在這個生態待過才會知道的細節。
各家模型我都試過。老實說,每一家都有各自擅長的領域,寫程式的能力也都在快速進步。但就我個人的使用情境——WordPress 外掛開發、WooCommerce 客製化、LINE 串接——Claude 的模型在這些場景中的表現,一直是最讓我順手的。
真正讓我做出判斷的,不是某一次的驚艷體驗,而是持續使用超過一年的累積。這一年多來,我用它跑過多個客戶專案,也拿它開發自己的產品。從最早期的版本到現在,我能明顯感受到它的進步——對 WordPress 生態系的理解越來越深,給出的方案也越來越貼近實務。它不只是語法正確,而是真的理解 WordPress 的開發慣例和設計邏輯,給出的方案越來越貼近有經驗的工程師會做的選擇。這不是靠「會寫程式」就能做到的,是長期迭代後才有的理解深度。
這不代表其他模型不好。只是當你在一個工具上投入了足夠的時間、建立了足夠的工作流程和信任感之後,除非有明確的理由讓你搬家,否則留下來是最合理的選擇。
這跟我一直選擇 WordPress 是同一個道理。十幾年來,每隔一陣子就有人問我:「為什麼不換框架?」Laravel、Next.js、各種新東西輪番出現,每個都有它的優勢。但我在 WordPress 上累積的理解、踩過的坑、建立起來的開發效率,不是換一個框架就能帶走的。工具的價值不只在功能本身,還在你跟它之間磨合出來的默契。
Claude 也是一樣。一直沒有給我搬家的理由。反而是每次更新,都讓我更確定留在這裡是對的。
但模型好只是第一步。接下來的問題是:你要怎麼用它?
工具越包越多層,體驗反而越來越差
既然 Claude 的模型寫程式最好,那用整合了 Claude API 的開發工具應該不錯吧?我也是這樣想的。
Cursor 我用了一陣子。體驗確實不錯,自動補全的速度快、上下文理解也到位。但它的訂閱費用對我來說是個問題——每個月的開銷加上去,對一個小團隊的荷包不太友善。當我發現 Claude Code 能做到同樣的事,甚至做得更多,而且計費方式更透明的時候,就沒有繼續留在 Cursor 的理由了。
Antigravity 我也試過。介面設計得漂亮,操作體驗流暢。但核心問題沒變:中間隔了一層,你不確定它到底是把你的需求原封不動傳給了模型,還是做了什麼改寫或截斷。
後來我直接用 Claude Code。
沒有華麗的 GUI,就是一個終端機介面。但第一次用完一整天的感受是:終於沒有東西擋在中間了。
我描述需求,它理解。它改了什麼檔案、改了哪幾行,全部攤在你面前。不用猜它在背後做了什麼。出問題的時候,你知道是你的需求沒描述清楚,還是它的判斷有誤——這個透明度,在其他工具上得不到。
我沒有客觀數據證明它「更快」或「更準」。這純粹是主觀體驗。但這個主觀體驗夠強烈,讓我再也沒打開過其他工具。
功能迭代的速度,其他工具追不上
選定 Claude Code 之後,這幾個月的觀察更讓我確信這個選擇是對的。
Claude Code 的開發團隊顯然有在看社群。一個功能需求在 GitHub Discussions 或 X 上被討論幾天,很可能下個版本就出現了。不是那種「我們聽到了,會排進路線圖」的官方回覆,是真的直接做出來。
Hooks 機制就是一個例子。社群裡有人想在每次 commit 前自動跑 lint,有人想在檔案修改後觸發自訂腳本。Claude Code 直接做了一套 hooks 系統,讓你可以在特定事件觸發時執行任意 shell 指令。這個機制後來被好幾個 AI 開發工具借鑑。
CLAUDE.md 也是。一個純文字檔案,放在專案根目錄,告訴 AI 這個專案的架構、慣例、偏好。這個概念簡單到不行,但它解決了一個所有 AI 工具都在頭痛的問題:怎麼讓 AI 理解「這個專案」的脈絡,而不只是「這個語言」的語法。類似的做法在其他工具上也有,像 Cursor 的 .cursorrules 甚至更早就出現了。但 Claude Code 在這個基礎上做得更完整——支援全域、專案、子目錄三層載入,加上自動記憶系統,讓專案脈絡的管理更有彈性。
還有 MCP(Model Context Protocol)、自訂 Skill、記憶系統、子代理人(Sub-agent)、背景任務⋯⋯這些功能一個接一個地推出,而且每個都不是花拳繡腿,是解決真實開發場景的問題。
一個工具的迭代速度能維持這麼快,代表它背後的團隊真的在用自己的產品。這件事聽起來理所當然,但在軟體業,做到的人比你想的少。
選工具,就是要選最底層的那一個
回到最初的問題:為什麼不用其他工具?
我的核心觀點是:Claude Code 目前是這個市場的規則制定者。
它不只是一個好用的工具。它在定義「AI 輔助開發應該長什麼樣子」這件事上,走在最前面。其他工具在追它的功能、參考它的設計模式、借用它的概念。
在這個前提下,我認為選擇 AI 工具的原則很簡單:選最底層的。
什麼叫最底層?就是它能做到的事情,是其他工具的功能來源。用 Claude Code 你可以做到那些「套殼」工具做得到的所有事情,甚至做到它們做不到的事情。反過來就不行了。
那些包了一層 GUI、加了一些限制、重新包裝過的工具,本質上都是在 Claude 的能力之上做篩選和呈現。篩選的過程中,一定會有東西被擋掉。有些是刻意的設計選擇,有些是能力上的限制。不管是哪種,你能用的,都只是模型完整能力的一部分。
我不想只用一部分。我想要完整的能力。
當然,Claude Code 的學習門檻比其他 AI 開發工具高。你得會用終端機,得理解基本的命令列操作,得學會怎麼寫 CLAUDE.md、怎麼設定 hooks、怎麼用 MCP 連接外部工具。這些東西第一次接觸確實需要花時間。
但這個投資是值得的。因為你學會的是最底層的操作方式,往上的工具你隨時都能理解、隨時都能切換。反過來,如果你只會用上層工具,一旦它們的限制卡住你,你就得從頭學起。
不是信仰,是工程判斷
我不是 Anthropic 的粉絲,這個選擇跟品牌忠誠沒有關係。如果明天有另一家公司做出了更強的模型和更好的開發工具,我會毫不猶豫地換過去。
但以 2026 年 3 月的時間點來看,Claude Code 就是目前最好的選項。模型能力最強、工具迭代最快、社群最活躍、對開發者的理解最深。
選工具不是選信仰。它是一個工程判斷——在你手邊可選的方案裡,哪個能讓你用最少的時間、做出品質最高的成果。
就我個人來說,目前這個答案是 Claude Code。就這麼簡單。
Claude Code x 技術小白第一次安裝就上手
第 3 篇,共 21 篇你聽說 Claude Code 很厲害,能用中文下指令就幫你寫程式、整理檔案、自動化重複工作。但打開教學文章,第一步就叫你「打開終端機輸入 npm install」——然後你就默默關掉教學分頁了…
這篇文章就是寫給你的。我們會介紹兩種安裝 Claude Code 的方式,從最簡單到稍微進階,讓你根據自己的需求選擇。
方法一:下載 Claude Desktop App(最簡單)
如果你只是想趕快開始用,這個方法三分鐘就能搞定。
第一步:下載安裝
到 claude.ai/download 下載 Claude Desktop App。Mac 和 Windows 都有,跟你平常安裝 LINE 電腦版或 Spotify 一樣——下載、打開、拖進應用程式資料夾,結束。
第二步:登入帳號
打開 App 之後用你的 Anthropic 帳號登入。如果還沒有帳號,在這一步就能註冊。
第三步:升級到 Pro 方案
免費帳號無法使用 Claude Code。登入後到帳號設定頁面,訂閱 Pro 方案(每月 20 美元)。這是使用 Claude Code 的最低門檻——付完之後,Code 分頁才會開放。
第四步:切換到 Code 模式
登入之後你會看到一般的聊天介面,跟網頁版 Claude 一樣。但注意上方——有一個 「Code」 分頁。點下去。
這就是 Claude Code。
第四步:選擇工作資料夾
進入 Code 分頁後,它會請你選擇一個「目的地資料夾」。這個資料夾就是 Claude Code 工作的地方——所有你要餵給它的檔案,或是它幫你產生的檔案,都會放在這裡。
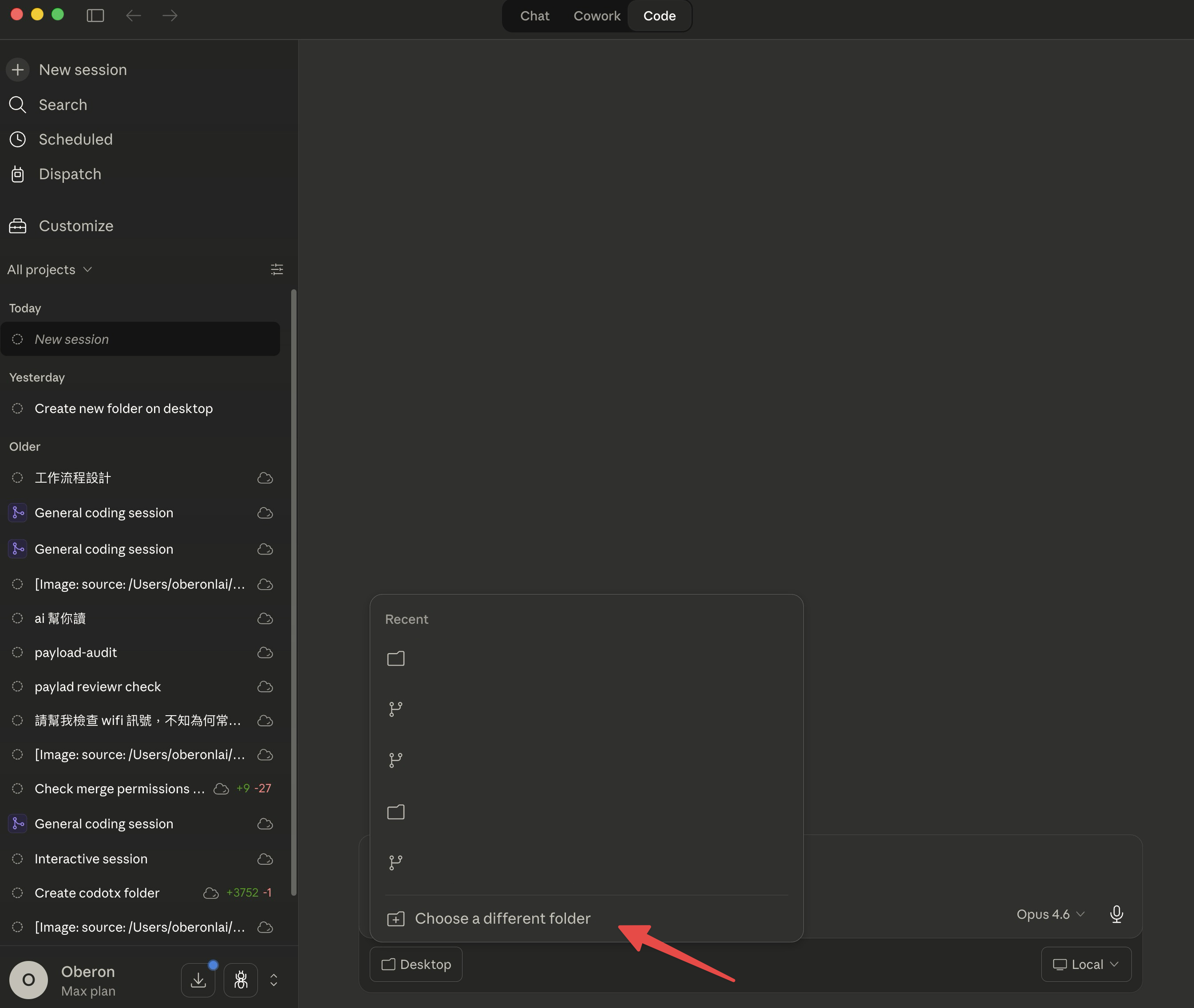
你可以從最近使用過的資料夾裡選,也可以點「Choose a different folder」自己指定。如果你還不確定要用哪個資料夾,先在桌面建一個新的空資料夾就好,之後隨時可以換。
選好之後,你就能開始在對話框裡打字,告訴 Claude Code 你想做什麼了。
想像你打開 Word 之後,上面有「文件」和「簡報」兩個分頁。Claude Desktop App 的概念類似——「Chat」是一般聊天,「Code」是讓 AI 幫你處理電腦上的工作。
這個方法適合誰?
- 第一次接觸 Claude Code,想先試試看能幹嘛
- 不想碰任何技術設定
- 主要用來做簡單的任務,例如整理文件、產生報表、轉換格式
方法二:用終端機安裝(進階但更靈活)
Desktop App 用起來很順手,但用一陣子之後你可能會碰到一些限制。比方說:
- 有些指令需要你回答問題。 安裝軟體或跑自動化工具的時候,它會問你「要選哪個選項?」「確定要繼續嗎?」這類互動在終端機裡才能直接處理。
- 有些工作本來就要在終端機裡做。 例如啟動某個程式、跑資料處理腳本等等。如果你已經在終端機裡用 Claude Code,它可以直接幫你執行,不用再另外開視窗。用 Desktop App 的話,碰到這類需求還得自己切過去終端機處理。
終端機是什麼?
你每天都在用圖形介面操作電腦:用滑鼠點資料夾、拖拉檔案、按按鈕。終端機是另一種操作電腦的方式——用打字代替點滑鼠。
打個比方:圖形介面像觸控螢幕的點餐機,你看到什麼就點什麼。終端機像直接跟店員說「一杯中杯拿鐵、去冰、加燕麥奶」——你得知道怎麼說,但說出來之後更快、更精確,還能一口氣講完複雜的要求。
你不需要記住什麼指令。Claude Code 的強大之處就在於——你只要用中文告訴它你想做什麼,它會自己跑對應的指令。終端機只是它工作的地方。
第一步:下載 Warp 終端機
Mac 和 Windows 都有內建的終端機程式,但老實說,預設的終端機介面不太友善。我們推薦用 Warp——它是專門為現代使用設計的終端機軟體,介面乾淨、操作直覺,打字的時候有自動完成,還能把輸入和輸出分成清楚的區塊。
到 warp.dev 下載安裝就好,Mac 和 Windows 都有,流程跟裝一般軟體一樣。
第二步:安裝 Claude Code
開啟 Warp 之後,在可以輸入指令的地方,複製以下的安裝指令並按下 Enter。它會自動幫你安裝 Node.js、Git 和 Claude Code。
安全提醒: 在網路上看到任何「貼上一行指令就能安裝」的做法時,請養成一個好習慣——先把指令貼給 ChatGPT 或 Gemini,請它幫你檢查這段指令在做什麼、有沒有危險性。有些惡意人士會利用這種方式在你的電腦安裝後門程式。以下這兩行指令你也可以先檢查,我們完全公開原始碼:Mac 版 / Windows 版。
Mac:
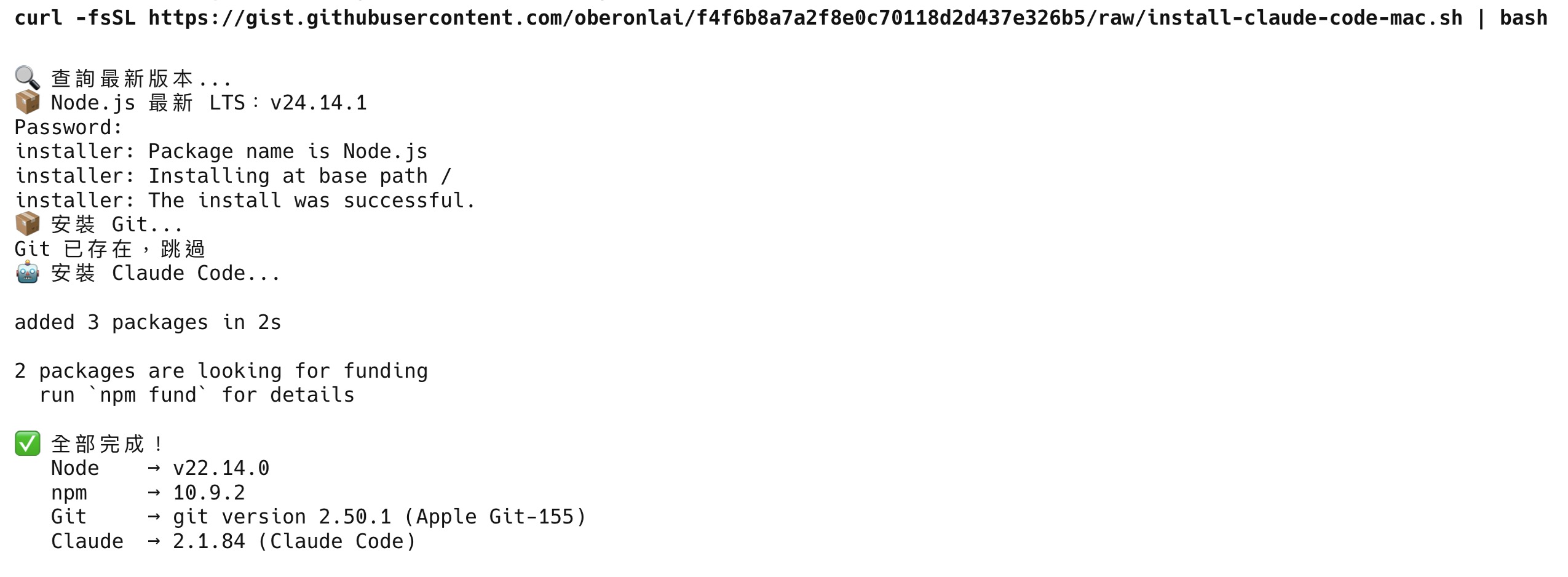
curl -fsSL https://gist.githubusercontent.com/oberonlai/f4f6b8a7a2f8e0c70118d2d437e326b5/raw/install-claude-code-mac.sh | bash過程中會跳出密碼輸入框(安裝 Node.js 需要系統權限),輸入你的 Mac 登入密碼後按 Enter。密碼不會顯示在畫面上,這是正常的。安裝 Git 時會彈出一個視窗,點「安裝」就好。
執行完成後,你會看到類似這樣的畫面,代表全部安裝成功:
Windows: 在工作列搜尋「Warp」,右鍵選「以系統管理員身分執行」,貼上這行指令後按 Enter:
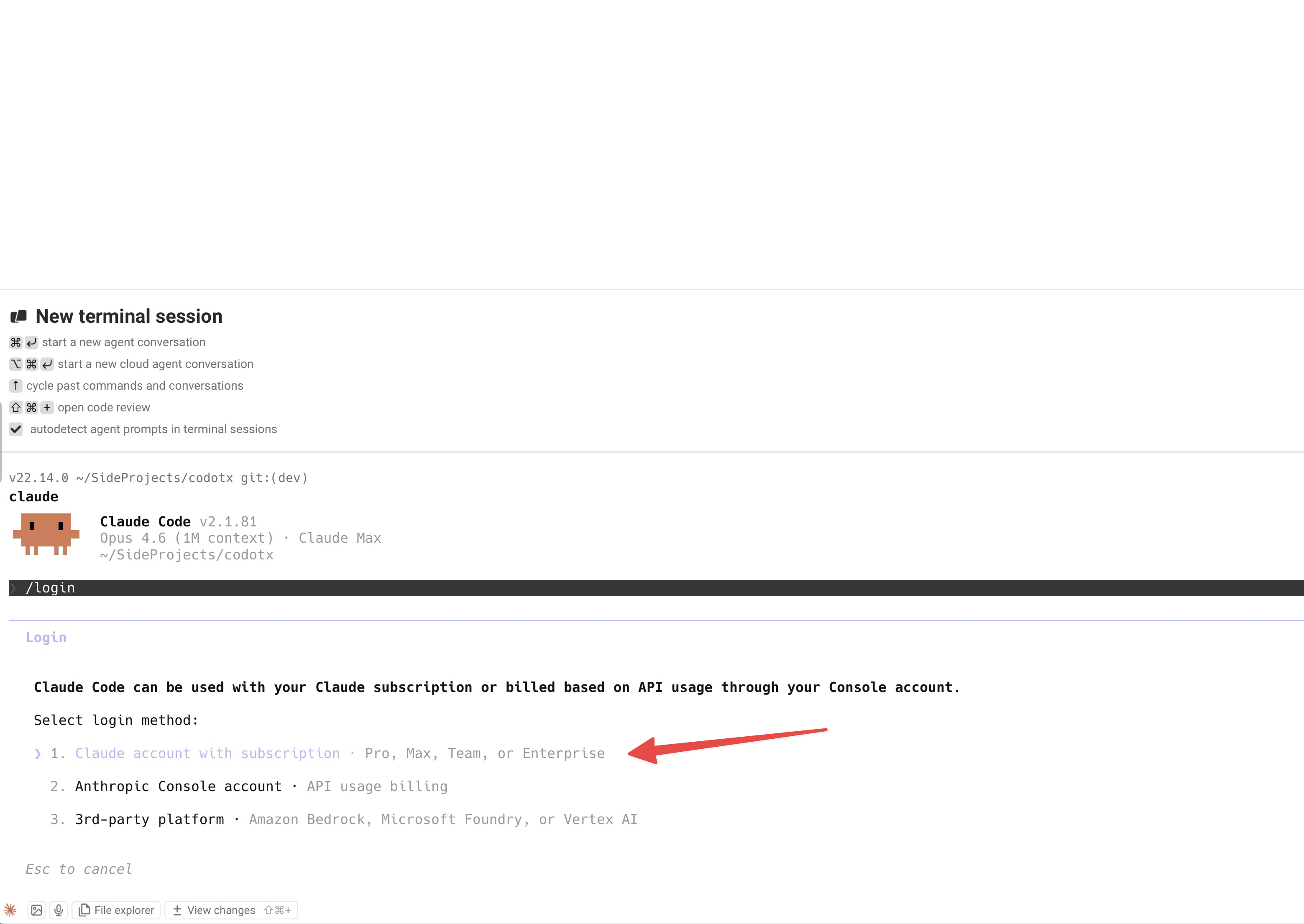
irm https://gist.githubusercontent.com/oberonlai/61ef05497999adc560600fceaabfe2b8/raw/install-claude-code-windows.ps1 | iex安裝完成後,輸入:
claude第一次執行會請你登入 Anthropic 帳號。畫面會出現三個選項,選第一個「Claude account with subscription」就對了。
登入完成後,就可以開始用自然語言跟 Claude Code 聊天了。直接打中文告訴它你想做什麼,它就會幫你處理。
為什麼要多費這個工夫?
Desktop App 很方便,但終端機版本有幾個優勢:
跑互動式指令。 有些工具會在過程中問你問題——「要選哪個選項?」「確定要繼續嗎?」——這類互動在終端機裡可以直接處理,Desktop App 目前還不支援。
不用在 App 和終端機之間來回切換。 有些工作本來就需要在終端機裡執行,例如啟動程式或跑腳本。如果你已經在終端機裡用 Claude Code,它可以直接幫你處理,不用另外開視窗。
簡單來說,Desktop App 像是在餐廳用平板點餐,終端機版本像是直接走進廚房。大部分時候平板就夠了,但如果你想做更細緻的事,廚房讓你有更多可能。
該選哪一種?
| Desktop App | 終端機版本 | |
|---|---|---|
| 安裝難度 | 下載就能用 | 貼上一行指令自動安裝 |
| 上手速度 | 馬上 | 需要 1 分鐘設定 |
| 適合用途 | 簡單任務、初次體驗 | 專案開發、檔案操作、進階自動化 |
| 彈性 | 基本 | 完整 |
我們的建議:先從 Desktop App 開始。等你用出心得、發現有些事情它做不到的時候,再來裝終端機版本。兩個可以同時存在,不衝突。
常見問題
Claude Code 要付費嗎?
要。Claude Code 需要至少 Pro 方案才能使用,免費帳號無法開啟。最入門的 Pro 方案是每月 20 美元,適合偶爾使用的人。如果用量比較大,Max 方案有每月 100 美元和 200 美元兩種選擇,額度更多。建議先從 Pro 開始,不夠再升級。
我用 Windows 可以嗎?
可以。Desktop App 有 Windows 版,直接下載安裝就能用。終端機版本也支援——上面的安裝步驟 Mac 和 Windows 都有,照著做就行。
Claude Code 和網頁版 Claude 有什麼不同?
網頁版 Claude 是聊天機器人——你問它問題,它回答你。Claude Code 是工作助手——它能直接操作你電腦上的檔案、執行指令、建立專案。差別在於,聊天機器人只能給你建議,Claude Code 能幫你動手做。
我完全不懂程式,真的能用嗎?
能。你不需要看懂它寫的程式碼,就像你不需要知道微波爐的電路設計才能加熱便當。你只要用中文描述你想做的事:「幫我把這 50 個 Excel 檔合併成一個」「把這個資料夾裡的照片按日期重新命名」——它會自己處理。
安裝到一半出問題怎麼辦?
一鍵安裝指令會在最後顯示 Node.js、Git 和 Claude Code 的版本號碼。如果其中任何一個沒有出現,可以個別檢查:
- 打開終端機,輸入
node --version,有出現版本號碼就是裝好了 - 輸入
git --version,同上 - 輸入
claude --version,同上
如果某個工具顯示「command not found」,關掉終端機重新打開再試一次——有些安裝需要重啟終端機才會生效。
Mac 用戶: 如果安裝過程中沒有跳出密碼輸入框就直接出現錯誤,重新執行一次指令,這次留意密碼提示。
Windows 用戶: 如果出現紅字錯誤訊息,最常見的原因是沒有用系統管理員身分執行 Warp。關掉目前的視窗,重新在工作列搜尋「Warp」,右鍵選「以系統管理員身分執行」,再貼上指令。
Desktop App 的 Code 模式和終端機版本是同一個東西嗎?
核心功能相同,都是 Claude Code。差別在於運作環境——Desktop App 把它包在一個圖形介面裡,終端機版本直接在你的電腦環境中執行,能做的事情更多。
Claude Code 教學:用 CLAUDE.md 讓 AI 不再失憶
第 4 篇,共 21 篇你有沒有過這種經驗——跟 AI 聊了半天,好不容易讓它理解你的需求,結果下次開新對話,它又把一切忘光了?
我們用 Claude Code 幫客戶開發專案時也遇過一樣的問題。每次開新對話,都要重新交代一次:「我們的網站是用哪個工具做的」「存檔的時候備註要寫中文」「文章裡的連結點了要開新分頁」。說了十次,第十一次它還是會忘。
後來我們發現,Claude Code 其實有一套「記憶系統」,能讓它跨對話記住你的指令和偏好。關鍵就在一個叫 CLAUDE.md 的檔案。
但在講這個檔案之前,得先解釋一個東西——.md 到底是什麼。
先搞懂 .md:一種讓文字有結構的寫法
你應該用過 Word,知道怎麼把標題加粗、列出項目清單、插入連結。.md 檔案做的事情差不多,只不過它不需要打開 Word,用最普通的文字編輯器就能寫。
.md 是 Markdown 的縮寫,一種用符號來標記文字格式的寫法。舉個例子:
# 這是大標題
## 這是小標題
- 第一點
- 第二點
**這段文字會加粗**寫出來的效果跟你在網頁上看到的標題、清單、粗體字一模一樣。
為什麼要用這種格式?因為它夠簡單。不需要安裝特別的軟體,任何地方都能打開、編輯。更重要的是——AI 讀得懂。Claude Code 就是用這種格式來讀取你給它的指令。
所以 CLAUDE.md 就是一個用 Markdown 格式寫給 Claude Code 看的指令檔。
CLAUDE.md:你交代給新人的工作備忘錄
當主管帶新人,第一天通常不會丟一本公司制度手冊給他看。你會寫一張備忘錄,把那些「制度裡沒寫但一定要知道」的事列出來:「寄信給客戶一律用敬語」「每週五下班前更新進度表」「王總的案子任何變動都要先跟我確認」。
CLAUDE.md 就是這張備忘錄,只不過你帶的新人是 AI。
每次你跟 Claude Code 開始新對話,它做的第一件事就是看這張備忘錄,把上面的規矩讀一遍。所以不管對話換了幾輪,只要寫在備忘錄上的交代,Claude Code 都會照做。
這份文件可以放什麼?
任何你希望 AI 每次都遵守的規則。我們自己的 CLAUDE.md 裡寫了這些:
專案基本資訊:
## 專案簡介
公司官網,使用 Astro 5 框架,支援繁體中文和英文。這就像告訴新同事「我們公司是做什麼的」。Claude Code 知道了專案的背景,回答問題時就不會牛頭不對馬嘴。
常用指令速查:
## 常用指令
| 指令 | 用途 |
|------|------|
| `npm run dev` | 啟動開發環境 |
| `npm run build` | 打包上線版本 |這就像辦公桌上貼的便利貼。Claude Code 需要跑指令時,不用猜,直接照做。
程式碼撰寫規範:
## Commit Message 規範
格式:`<類型>(<範圍>): <簡述>`,使用繁體中文。
範例:
- feat(news): 新增延伸閱讀功能
- fix(WorkCard): 修正圖片邊框問題這是最實用的部分。我們把 commit message 的格式寫進去之後,Claude Code 每次提交程式碼都會自動遵守這個格式,不用每次都提醒。
檔案要放在哪裡?
CLAUDE.md 可以放在不同的位置,作用範圍也不一樣:
| 放在哪裡 | 影響範圍 | 適合放什麼 |
|---|---|---|
專案根目錄 ./CLAUDE.md | 這個專案 | 專案架構、程式碼風格、常用指令 |
電腦根目錄 ~/.claude/CLAUDE.md | 你電腦上的所有專案 | 個人偏好,例如「回覆用繁體中文」 |
用生活化的方式理解:專案的 CLAUDE.md 像是「這間辦公室的規定」,電腦根目錄的 CLAUDE.md 像是「你個人的工作習慣」。不管你換到哪個專案,個人偏好都會跟著你。
快速產生 CLAUDE.md
如果你不知道該從何寫起,Claude Code 提供了一個快速鍵:在對話中輸入 /init,它會自動掃描你的專案結構,幫你產生一份 CLAUDE.md 初稿。裡面會包含它從程式碼中發現的框架、指令和專案慣例。
你再根據實際需求修改就好,不需要從零開始。
自動記憶:AI 自己做的筆記
CLAUDE.md 是你寫給 AI 看的。但 Claude Code 還有另一套機制——自動記憶,是 AI 自己寫給自己看的筆記。
這就像你跟同事合作久了,他會記住「這個人不喜歡太長的變數名稱」「每次改完程式碼要先跑測試」。你沒有明確說過這些規則,但他從你的反應中學會了。
Claude Code 也一樣。當你在對話中糾正它——「不要用這個格式」「連結要另開分頁」——它會把這些修正記下來,存成筆記。下次開新對話,它會先翻這些筆記,避免犯同樣的錯。
來看看實際的記憶長什麼樣子
我們專案裡有一筆自動記憶是這樣的:
---
name: 外連連結另開分頁
type: feedback
---
文章內的外部連結一律另開瀏覽器分頁。
Why: 避免讀者點擊外連後離開文章頁面,影響閱讀體驗。這筆記憶的起源是:我們有一次發現 Claude Code 寫文章時,外部連結沒有設定另開分頁,讀者點了就直接跳走。我們糾正了一次,它就記住了。之後每篇文章,它都會自動把外部連結設成另開分頁。
另一筆更複雜的記憶是關於簡報製作流程:
---
name: 簡報製作流程
type: feedback
---
當使用者說要「做簡報」時,使用 Marp 工具將文章轉為簡報格式。
流程:
1. 讀取文章內容,整理出簡報大綱
2. 使用公司設計好的簡報主題
3. 最後一頁加上 QR Code
4. 在文章中嵌入簡報我們只教過它一次完整的簡報製作流程,它就把每個步驟都記下來了。現在我們只要說「幫這篇文章做簡報」,它就知道該怎麼做,不用再從頭教一遍。
你也可以主動叫它記住
除了被動學習,你也可以直接告訴 Claude Code:「記住,我們的網域是 codotx.com,不要用其他網址。」
它會把這條規則存進自動記憶裡。下次遇到需要填入網址的情境,它就會自動用正確的網域。
記憶存在哪裡?
自動記憶存在你電腦的 ~/.claude/projects/ 資料夾底下,每個專案有自己的記憶區。裡面是一般的文字檔,你隨時可以打開來看、修改,甚至刪除不需要的記憶。
記憶的入口是一個叫 MEMORY.md 的索引檔,Claude Code 每次開對話都會讀它的前 200 行。這個索引檔會連結到其他更細節的筆記。如果某條記憶過時了或寫錯了,你直接改掉就好。
除了記憶之外,Claude Code 還有一個叫 .claude/rules/ 的資料夾,可以放更細緻的規則檔案。
用主管的角度來理解:CLAUDE.md 像是你在新人第一天交代的通用規矩,而 rules 像是你針對不同業務線寫的 SOP。每份 SOP 各自獨立一個檔案,一個主題寫一份,檔名就用主題來命名。整個資料夾結構大概長這樣:
你的專案/
├── .claude/
│ ├── CLAUDE.md # 通用規矩
│ └── rules/
│ ├── 寫作風格.md # 文章怎麼寫
│ ├── 客戶溝通.md # 跟客戶互動的規範
│ └── 報表格式.md # 報表該長什麼樣子Rules 分成兩種。通用型的沒有指定適用範圍,每次開對話就會自動載入,跟 CLAUDE.md 一樣——就像貼在公佈欄上的公告,所有人都會看到。
指定範圍型的則只在 AI 碰到相關工作時才會載入。你可以在規則檔案的開頭標註「這份 SOP 只在處理某類工作時適用」,AI 平常不會去翻它,碰到那類工作時才會自動拿出來看。就像你告訴新人:「處理 A 客戶的案子,去第三層櫃子拿那份 SOP 來照著做。」
如果你有多個專案都要遵守同一套規則,也不用每個專案都複製一份。你可以用「捷徑」的方式,讓不同專案的 rules 資料夾都指向同一組規則檔案。改了一個地方,所有專案就會同步更新。
這樣做的好處是節省空間。CLAUDE.md 建議控制在 200 行以內,把所有規則都塞進去很快就滿了。拆到 rules 資料夾之後,AI 只在需要的時候才會去讀對應的規則,既不浪費空間,遵守率也更高。
想快速查看目前有哪些記憶?在對話中輸入 /memory,Claude Code 會列出所有已載入的指令檔和記憶檔,你可以直接點開編輯。
CLAUDE.md 跟自動記憶的差別
兩套系統聽起來很像,實際上分工很清楚:
| CLAUDE.md | 自動記憶 | |
|---|---|---|
| 誰來寫 | 你自己寫 | Claude Code 自動寫 |
| 內容是什麼 | 明確的規則和指令 | 它從你的回饋中學到的習慣 |
| 什麼時候用 | 你一開始就知道的規矩 | 合作過程中慢慢累積的默契 |
| 怎麼改 | 直接編輯檔案 | 在對話中糾正,或手動改檔案 |
用個比喻:CLAUDE.md 是員工手冊,自動記憶是工作筆記。員工手冊是公司發的,寫的是正式規定;工作筆記是同事自己記的,寫的是「上次主管說不喜歡這樣做」之類的實戰經驗。
兩者配合起來,AI 就不只是一個「每次見面都像陌生人」的工具,而是一個越用越順手的工作夥伴。
寫好 CLAUDE.md 的幾個建議
根據我們的實際使用經驗,加上官方文件的建議,分享幾個讓 CLAUDE.md 更有效的做法:
只寫 AI 自己查不到的東西。 這是最重要的一點。專案裡有哪些檔案、用了什麼工具、程式碼的結構長怎樣——這些 AI 在工作的時候會自己去翻,不需要你事先告訴它。CLAUDE.md 應該放的是「它讀遍整個專案也讀不出來的東西」:你個人的工作習慣、團隊約定的格式規範、特殊的流程要求。
舉個例子:「存檔備註要用繁體中文」這件事,AI 看程式碼是看不出來的,所以要寫進去。但「這個專案有哪些頁面」這種資訊,它自己就能找到,寫了只是浪費空間。
控制在 200 行以內。 太長的話,AI 讀起來反而會抓不到重點。就像你不會給新人一本 500 頁的員工手冊——重點越精簡,遵守率越高。
寫得越具體越好。 「程式碼要寫好」這種指令沒有用。「縮排用 2 個空格」「變數名稱用英文」這種才有用。AI 跟人一樣,模糊的指令只會讓它自由發揮。
避免互相矛盾。 如果一個地方寫「用 Tab 縮排」,另一個地方寫「用空格縮排」,AI 會隨機挑一個照做。定期檢查一下,把過時或衝突的規則清掉。
善用標題和清單。 用 Markdown 的標題(##)和清單(-)把指令分組。有結構的文件比一大段文字容易被正確理解。
對話紀錄不會消失,但 AI 不會主動翻舊帳
你可能會擔心:「關掉 Claude Code 之後,之前的對話不就沒了?」
其實不會。Claude Code 會把每次對話的完整紀錄存在你的電腦裡。你隨時可以用 claude --continue 回到上一次對話繼續聊,或用 claude --resume 從清單裡挑一個過去的對話接著做。
但這裡有個容易誤會的地方:對話紀錄雖然還在,AI 卻不會主動去翻它。
每次開新對話,Claude Code 的工作記憶是全新的——就像同事昨天跟你開了三小時的會,但今天早上進辦公室,他不會自動記得昨天會議的每個細節。除非你提醒他「我們昨天討論過 X」,或者他自己有做會議紀錄。
這就是 CLAUDE.md 和自動記憶的價值所在。
對話紀錄是「可以查閱的會議錄音」,你想回去聽隨時可以。但 CLAUDE.md 是「貼在螢幕上的便利貼」,AI 每天上班第一件事就會看到。自動記憶則是它自己的筆記本,記錄著「上次老闆說不喜歡這樣做」之類的經驗。
所以,與其每次開新對話都重複同樣的話,不如花十分鐘把那些規則寫進 CLAUDE.md。讓 AI 幫你做筆記的同時,也幫它建立一份讀得懂的工作手冊。
你會發現,當 AI 不再失憶,工作效率的提升比你想像的明顯得多。
常見問題
Q:我不會寫程式,也能用 CLAUDE.md 嗎?
可以。CLAUDE.md 就是一個純文字檔,你用記事本就能打開編輯。裡面寫的是中文指令,不是程式碼。只要你會打字、會列清單,就能寫。
Q:CLAUDE.md 一定要自己寫嗎?
不用,你可以直接用講的。但要注意你怎麼說,會決定指令被存到哪裡:
- 說「記住,以後報表格式都要用這個樣式」→ 存進自動記憶
- 說「把這條加到 CLAUDE.md」→ 存進 CLAUDE.md
差別在哪?CLAUDE.md 每次開對話都會完整載入,遵守率比較高。自動記憶則是 AI 自己判斷什麼時候要翻出來看,偶爾可能會漏掉。所以如果是很重要、希望它每次都照做的規則,建議明確跟它說「加到 CLAUDE.md」。
Q:CLAUDE.md 寫錯了會不會搞壞專案?
不會。CLAUDE.md 只是給 AI 看的參考指令,不是系統設定檔。寫錯了頂多是 AI 照著錯誤的指令做事,你把內容改回來就好。
Q:自動記憶會不會記到奇怪的東西?
有可能。AI 根據它自己的判斷決定什麼值得記住,偶爾會記下不太準確或已經過時的內容。你可以在對話中輸入 /memory 查看所有記憶,看到不對的直接刪掉或修改。
Q:我寫了 CLAUDE.md,但 AI 有時候還是不照做?
這是正常的。CLAUDE.md 是「建議」而不是「強制」。根據官方說明,指令越具體、越簡短,AI 的遵守率越高。如果某條規則經常被忽略,試試把它寫得更明確,或檢查是不是跟其他規則互相矛盾了。
Q:CLAUDE.md 跟自動記憶衝突的話,AI 聽誰的?
兩者都會被載入,但 CLAUDE.md 的優先權比較高。如果你發現自動記憶裡存了跟 CLAUDE.md 矛盾的內容,直接把那筆記憶刪掉就好。
參考連結
- Claude Code 官方文件:記憶機制 — 完整說明 CLAUDE.md 和自動記憶的運作方式
- Markdown 基礎語法指南 — 學習 .md 檔案的寫法
裝好 Claude Code,然後呢?從改一個現成的 Skill 開始
第 5 篇,共 21 篇Claude Code 是 Anthropic 推出的 AI 程式助手,但它能做的事遠不只寫程式——你可以用它寫文章、整理資料、自動化日常工作。你已經知道它有多強大,也看過社群上有人用它做出各種成果。你甚至已經裝好了,對於想拿它來做什麼也有了初步的想法。
但你卡在「終端機」。
那個黑色的視窗、閃爍的游標、沒有按鈕可以點的介面——光是看到就讓人退縮。如果這是你的心聲,這篇 Claude Code 教學就是為你而寫的。
這篇文章不會提到任何程式碼。我想分享的是:怎麼用別人已經做好的「Skill」,讓 Claude Code 幫你完成具體的工作。
在開始之前,你需要什麼
要跟著這篇文章操作,你需要先準備好以下三件事:
- 一台 Mac 或 Windows 電腦
- 訂閱 Claude Pro 方案(每月 20 美元)
- 已經安裝好 Claude Code
如果你還沒安裝,請先參考我們之前寫的安裝教學,裡面有兩種安裝方式,最簡單的三分鐘就能搞定。
第一步:開啟 Warp 終端機
你的電腦裡內建了終端機(Mac 是 Terminal,Windows 是 PowerShell),但我推薦你用 Warp。
為什麼?因為 Warp 長得比較像你平常用的軟體。它有漂亮的介面、自動完成提示,還能用滑鼠操作。傳統終端機像是一張白紙,Warp 比較像是一個有工具列的筆記本。
下載安裝好之後,打開它。你會看到一個視窗,底部有一個輸入框。
就是這裡。接下來的所有操作,都在這個輸入框裡完成。
第二步:建立你的工作資料夾
在開始任何事情之前,我習慣先在電腦裡開一個跟這項工作相關的資料夾。
舉個例子:如果你想用 Claude Code 幫你寫文章,就在桌面或你習慣的位置,用 Finder(Mac)或檔案總管(Windows)建一個資料夾,取名叫 my-blog。
這個步驟跟你平常整理檔案一樣,沒有任何技術門檻。
第三步:讓 Claude Code 知道你的工作位置
這是很多人卡關的地方,但其實只有一個動作。
在 Warp 的輸入框裡,打上 cd (注意 cd 後面有一個空格),然後把你剛才建好的資料夾,從 Finder 直接拖進 Warp 視窗裡。
Warp 會自動幫你填上那個資料夾的完整路徑。按下 Enter。
這樣做的意義是什麼?你在告訴電腦:「我接下來要做的事,都跟這個資料夾有關。」Claude Code 啟動後,它會以這個資料夾為基準來工作。
接下來,輸入 claude 然後按 Enter,Claude Code 就會啟動了。
第四步:幫對話取一個名字
進入 Claude Code 之後,我建議你做的第一件事,是幫這次對話取名。
輸入:
/rename my-first-blog
為什麼要這樣做?因為你以後會開很多次 Claude Code 的對話。如果沒輸入的話,過幾天回頭找的時候,你完全不知道哪個對話在做什麼事。
取名的格式沒有硬性規定,但我的習慣是用英文加上連字號,像是 write-product-intro 或 organize-meeting-notes。簡短,一看就知道在做什麼。
之後想回到某次對話的時候,輸入 /resume 就會列出所有過去的對話紀錄。有取名字的對話一眼就能找到,沒取名的只會看到一串看不懂的開頭——像下圖裡的 post-skill、portal-update 都是取過名字的,馬上知道那次在做什麼事。
Claude Code 怎麼用:認識 Skill 這個概念
到這裡,你已經進入 Claude Code 了。但現在問題來了——你要跟它說什麼?
如果你直接說「幫我寫一篇文章」,Claude Code 當然會寫。但它寫出來的東西,可能語氣不對、格式不對、風格也不是你要的。你得來回修改很多次,才能得到一個勉強能用的結果。
這就是 Skill 要解決的問題。
想像一下:你去一家新的咖啡店,跟店員說「給我一杯咖啡」。店員可能會問你:要熱的還是冰的?要美式還是拿鐵?要大杯還是小杯?糖要幾分?你得來回溝通好幾次,才能拿到你想要的那杯咖啡。
但如果這家店有一張點餐單,上面寫著每款咖啡的規格、甜度選項、份量大小——你只要在單子上勾選就好。不用解釋、不用來回確認,一次就能拿到你要的東西。
Skill 就是那張點餐單。
它是一份預先寫好的指令文件,告訴 Claude Code:「當有人請你做這件事的時候,請按照這些規範來執行。」裡面定義了語氣、格式、該注意的事項、品質標準——所有你每次都要重新交代的細節,全部預先設定好了。
認識 MCP:讓 Claude Code 連接外部工具
在解釋怎麼使用 Skill 之前,有另一個概念值得認識:MCP(Model Context Protocol)。
如果 Skill 是「點餐單」,那 MCP 就是「外送平台」。
Claude Code 本身很聰明,但它原本只能在你的電腦裡工作。MCP 讓它能夠連接外部的工具和服務——查詢搜尋引擎的資料、讀取網頁內容、串接資料庫。就像你透過外送平台,能點到不同餐廳的菜色一樣。
舉個實際的例子:我們公司的寫作 Skill 裡面,有一個步驟是「在寫文章之前,先做關鍵字研究」。這個關鍵字研究需要查詢 Google 的搜尋量資料。Claude Code 本身沒有這個能力,但透過 MCP 連接了一個叫 DataForSEO 的服務之後,它就能自動查詢任何關鍵字的搜尋量、競爭程度和趨勢。
你不需要現在就設定 MCP。大部分 Skill 不需要額外的外部連接就能使用。但知道這個概念,會幫助你理解 Claude Code 為什麼能做到那麼多事。
想更深入了解 MCP 的運作方式,可以參考我們寫的 CLAUDE.md 與記憶機制教學。
實戰:用現成的 Skill 寫一篇文章
概念講完了。接下來我用一個實際的例子,帶你走一遍完整的流程。
我們公司有一個公開的寫作 Skill,叫做 codotx-blog。這個 Skill 的功能是:你告訴它文章主題和素材,它會按照我們公司的風格和規範,產出一篇完整的技術文章。包含 SEO 關鍵字研究、競品分析、內文撰寫、品質檢查——全部自動化。
你可以在 GitHub Gist 上看到這個 Skill 的完整內容。
但重點不是這個 Skill 本身——重點是你學會之後,可以去找任何你需要的 Skill,放進 Claude Code 裡面用。網路上有越來越多人分享自己做的 Skill,從寫文章、做簡報、整理會議記錄到分析資料都有。
不過要提醒一件事:使用別人寫好的 Skill 或任何第三方工具之前,請先把內容丟到 AI 裡面問一下「這份文件有沒有安全疑慮」,或是自己讀過一遍確認沒有問題。Skill 本質上就是一份指令文件,裡面寫什麼,Claude Code 就會照做——所以確認來源可信再使用,是一個好習慣。
怎麼把 Skill 放進 Claude Code
你不需要自己建資料夾、不需要手動複製貼上任何檔案。直接把 Skill 的網址丟給 Claude Code,請它幫你安裝就好。
在 Claude Code 的對話框裡,輸入這段話:
請幫我把這個 Skill 安裝到專案裡:
https://gist.github.com/oberonlai/1da61d51bf59f29dc838c37d84b38865Claude Code 會自動幫你做完所有事——建立資料夾、下載 Skill 內容、放到正確的位置。你只需要在它詢問權限的時候按下確認。
安裝完成後,你可以在專案資料夾裡找到這份 Skill:
my-blog/.claude/skills/codotx-blog/SKILL.md.claude 是一個隱藏資料夾(名稱前面有一個點),在檔案管理工具裡預設看不到。Mac 的 Finder 按下 Cmd + Shift + . 就能顯示隱藏檔案;Windows 的檔案總管則是點上方的「檢視」,勾選「隱藏的項目」。
打開 Skill 看看裡面寫了什麼
安裝好之後,我建議你用文字編輯器打開 SKILL.md 這個檔案,花幾分鐘讀一下裡面的內容。
檔案的開頭是一段用 --- 包起來的區塊,叫做 frontmatter:
---
name: codotx-blog
description: |
撰寫想點創意科技(codotx)技術部落格文章……
當使用者提到要寫部落格、寫文章、寫技術分享時,使用這個 skill。
---這段 frontmatter 決定了兩件事:
- name — Skill 的名稱。Claude Code 會用這個名稱來識別它,你之後輸入
/codotx-blog就能觸發這個 Skill - description — 觸發條件的描述。Claude Code 會讀這段文字來判斷什麼時候該啟用這個 Skill。像這個例子裡寫的「當使用者提到要寫部落格、寫文章時,使用這個 skill」,代表你就算不用
/codotx-blog指令,只要說「幫我寫一篇文章」,Claude Code 也會自動啟用它
frontmatter 下方的內容,就是 Skill 的本體——所有的工作規範都寫在這裡。以這個寫作 Skill 為例,裡面包含了語氣校準表、禁用詞彙清單、SEO 關鍵字研究流程、文章格式規範、品質評分標準。Claude Code 每次執行這個 Skill 的時候,都會嚴格遵守這些規則。
重點來了:這份檔案完全可以修改。
你可以根據自己的需求,把裡面的規範改成你要的版本。想要不同的語氣風格?改掉語氣校準表。不需要 SEO 關鍵字研究?把那段刪掉。想加上你自己公司的品牌用語規範?直接加進去。
Skill 不是什麼神秘的程式碼——它就是一份用中文寫的指令文件。你看得懂,就改得動。
你可以自己打開檔案直接編輯,也可以用更省力的方式——直接在 Claude Code 裡用自然語言請它幫你改。例如跟它說「幫我把 Skill 裡面的語氣改成更輕鬆的風格」或「幫我把 SEO 研究的步驟拿掉」,它就會自動找到對應的段落幫你修改。連打開檔案都不用。
使用 Skill 來寫文章
現在你已經在 Claude Code 裡面了,而且它已經載入了 codotx-blog 這個 Skill。
接下來怎麼做?就像平常跟 AI 聊天一樣,告訴它你想寫什麼:
/codotx-blog 幫我寫一篇關於遠端工作溝通工具比較的文章,
目標讀者是中小企業的管理者然後,Claude Code 就會按照 Skill 裡面定義好的流程,一步一步執行:
- 它會先跟你確認文章的方向和讀者
- 自動做關鍵字研究(如果 Skill 有設定這個步驟)
- 分析目前搜尋排名前幾名的競爭文章
- 把研究結果整理成一張表格給你看,等你確認
- 你確認之後,它才開始寫文章
- 寫完之後自動跑品質檢查,給你評分
整個過程中你不需要寫任何一行程式碼。你只需要回答它的問題、確認它的建議、最後驗收成果。
跟直接對 ChatGPT 說「幫我寫一篇文章」相比,最大的差別在於:Skill 帶來的是一致性和品質控制。 它不會每次寫出不同風格的東西,因為所有的規範都已經預先定義好了。
不只是寫文章
寫文章只是其中一個例子。Skill 的應用範圍取決於你的需求。
你可以找到(或自己設計)各種用途的 Skill:
- 會議記錄整理:把錄音逐字稿丟進去,自動整理成重點摘要和待辦事項
- 社群貼文生成:給它產品資訊,按照品牌風格產出不同平台的貼文
- 資料分析報告:丟入 CSV 資料,產出圖表和分析結論
- 客戶信件回覆:根據來信內容和公司政策,草擬回覆信件
關鍵在於:你不需要會寫程式,你需要的是找到適合你的 Skill,然後按照這篇教學的步驟放進去。
如果你想了解我們為什麼選擇 Claude Code 而不是其他工具,或是想知道非工程師學 Claude Code 的八個理由,這兩篇文章能給你更多背景。
常見問題
Claude Code 一定要用終端機嗎?不能用圖形介面?
Claude Code 有 Desktop App 版本,可以在圖形介面裡使用 Code 模式。但如果你想使用自訂 Skill 或 MCP 連接外部工具,目前還是需要透過終端機操作。好消息是,你真正需要學的終端機指令只有一個:cd。
Skill 檔案放錯位置怎麼辦?
Claude Code 會在 .claude/skills/ 這個路徑下尋找 Skill。如果你放錯位置,它不會報錯,只是找不到。確認你的資料夾結構是 你的專案/.claude/skills/skill名稱/SKILL.md,大小寫也要正確。
我可以同時放多個 Skill 嗎?
可以。每個 Skill 放在 .claude/skills/ 底下各自的資料夾裡就好。例如你可以同時有 .claude/skills/blog-writer/ 和 .claude/skills/meeting-notes/,Claude Code 會根據你的指令自動選擇對應的 Skill。
想用 Claude Code 來改善你的工作流程,但不確定從哪裡開始?歡迎聯絡我們,聊聊你的需求。
Claude Code x 社群自動化發文
第 6 篇,共 21 篇用 Claude Code 的瀏覽器自動化功能,可以直接操作你已登入的 Chrome 瀏覽器,不需要申請任何社群平台的 API key,一句指令就能把文章發到 Threads、X、LinkedIn。
上一篇文章提到,用 Skill 就能讓 Claude Code 幫你產出文章,但寫完文章只是第一步,接下來得把內容貼到各個社群平台。每個平台的字數限制不同、語氣要調整、格式要修改,光是複製貼上就要重複三四次。
我一開始想到的解法是用 API 自動化——對熟悉開發的人來說,申請 API key 是再日常不過的事,但對一般使用者來說,光是搞懂每個平台的申請流程就是一道門檻。
每個平台的 API 都是一道關卡
要用 API 自動發文,第一步是申請開發者帳號和 API key。聽起來不難,但實際走一遍就知道有多麻煩。
Facebook 和 Threads 共用 Meta 的開發者平台,申請 App 之後還要通過 App Review,審核流程動輒好幾天。X 的 API 在 2023 年改成付費制,免費方案只能發文,不能讀取——而且每個月有發文數量限制。LinkedIn 的 API 申請需要填寫商業用途說明,審核完才能拿到 token。
就算全部申請下來,你手上會多出四組 API key、四組 secret、可能還有 OAuth token 要定期更新。管理這些憑證本身就是一個工程。
當然,市面上有 Buffer、Hootsuite 這類社群排程工具可以幫你管理多平台發文,登入授權就能用,不用自己碰 API,但這些服務都要月費,而且我只是想把寫好的文章發到社群而已,為了這件事多訂閱一個工具,總覺得不太值得。有沒有不用額外花錢的方法?
第一個嘗試:CLI 瀏覽器自動化
我先想到的是 agent-browser,一個 CLI 工具,可以用指令開啟瀏覽器、操作網頁元素。邏輯很簡單:開瀏覽器 → 打開社群平台 → 找到發文框 → 填入內容 → 點發布。
問題是,agent-browser 每次啟動都會開一個全新的瀏覽器 session。這意味著每次執行都要重新登入,而現在的社群平台幾乎都有雙重驗證。每發一次文就要輸入一次驗證碼,自動化的意義就消失了。
第二個嘗試:Computer Use MCP
Claude Code 有一個叫 Computer Use 的 MCP 功能,可以控制你的電腦——截圖、點擊、打字。我以為這就是答案。
實際測試才發現,Computer Use 對瀏覽器有特殊的安全限制。它把瀏覽器歸類為「read」層級,只能截圖看畫面,不能點擊也不能打字。這是刻意的設計,不是 bug。
能看不能碰,等於白搭。
真正的解法:Claude in Chrome
繞了一圈之後,我發現 Claude Code 其實有一個專門為瀏覽器設計的功能——Claude in Chrome。它是一個 Chrome 擴充功能,安裝之後會透過 MCP(Model Context Protocol)跟 Claude Code 連線。
跟前面兩個方案的關鍵差別在於:它直接操作你已經登入的 Chrome 瀏覽器。你平常用哪個 Chrome profile 登入社群帳號,它就用那個 profile。不需要重新登入,不會觸發雙重驗證,因為對社群平台來說,這就是你在用自己的瀏覽器。
不需要 API key。不需要寫程式。只要裝好擴充功能,Claude Code 就能幫你在瀏覽器裡操作。
做成一個 Skill
確認方案可行之後,我把它包裝成一個 Claude Code Skill,取名叫 /social-publish。整個流程分兩個階段。
階段一:內容產生。 我指定一篇 Markdown 文章的路徑,Claude Code 讀取文章內容後,針對三個平台產出客製化版本——Threads 用繁體中文、口語化、控制在 300 字內;X 用英文、280 字元以內;LinkedIn 用繁體中文、專業語氣、可以寫到 500 字。三個版本一次展示,我確認沒問題再進入下一步。
階段二:瀏覽器發布。 確認後,Claude Code 透過 Chrome 擴充功能自動開啟各平台的發文頁面,填入內容,等我做最後確認再點發布。每個平台發布前都會再問一次,所以我可以選擇只發其中幾個。
整個操作就是一句指令:
/social-publish src/data/news/2026-04-01-ai-writing-mindset-shift.md從產出三個平台的貼文到全部發布完成,大約三分鐘。
為什麼放棄 Facebook 自動化
你可能注意到只有三個平台,沒有 Facebook。不是不想做,是做不到。
Facebook 的反機器人偵測是所有平台裡最嚴格的。即使用 Chrome MCP 操作已登入的瀏覽器,Facebook 的頁面捲動時會出現黑屏、DOM 結構經常改版、發文框的渲染方式也跟其他平台不同。試了幾次之後,我決定 Facebook 就手動發布,把自動化的力氣花在其他三個平台上。
這是一個務實的取捨。自動化不需要追求 100% 覆蓋,能省掉 75% 的重複操作就已經很值得了。
踩到的坑:從搜尋元素到 Intent URL
一開始 Chrome MCP 用的是 find 和 snapshot 功能去搜尋頁面上的元素——先掃描整個頁面的無障礙樹,找到發文框的位置,再點擊它。這個方法能用,但有兩個問題:
第一,每次搜尋和解析頁面結構都會消耗 token。一個平台的發文流程要來回好幾次,三個平台加起來的 token 消耗很可觀。
第二,社群平台的 DOM 結構不穩定。上週能找到的元素 class name,這週可能就改了。
後來我發現 Threads 和 X 都支援 Intent URL——一種特殊的網址格式,可以直接帶入要發布的文字。只要把貼文內容 URL encode 之後接在網址後面,打開這個網址就會自動跳出發文對話框,內容已經填好了。
https://www.threads.net/intent/post?text=<encoded_text>
https://x.com/intent/tweet?text=<encoded_text>用 Intent URL 之後,原本需要好幾步的「找發文框 → 點擊 → 填入文字」變成一步到位。發布按鈕的位置也相對固定,直接寫死座標就好。
這個改動讓每次發文少了好幾輪的頁面搜尋,token 消耗大幅降低,穩定度也提高了。LinkedIn 沒有 Intent URL,所以還是用 DOM 操作的方式——點擊「撰寫貼文」按鈕、填入內容、點發布。
設定 Chrome MCP 的步驟
如果你想自己做類似的東西,設定流程其實不複雜,但有幾個步驟要照順序走。
第一步:安裝 Chrome 擴充功能。 到 Chrome Web Store 安裝 Claude 擴充功能,安裝後會在瀏覽器右上角看到擴充功能圖示。
第二步:在 Claude Code 裡啟用。 在 Claude Code 的終端機裡輸入 /chrome,會看到以下畫面:
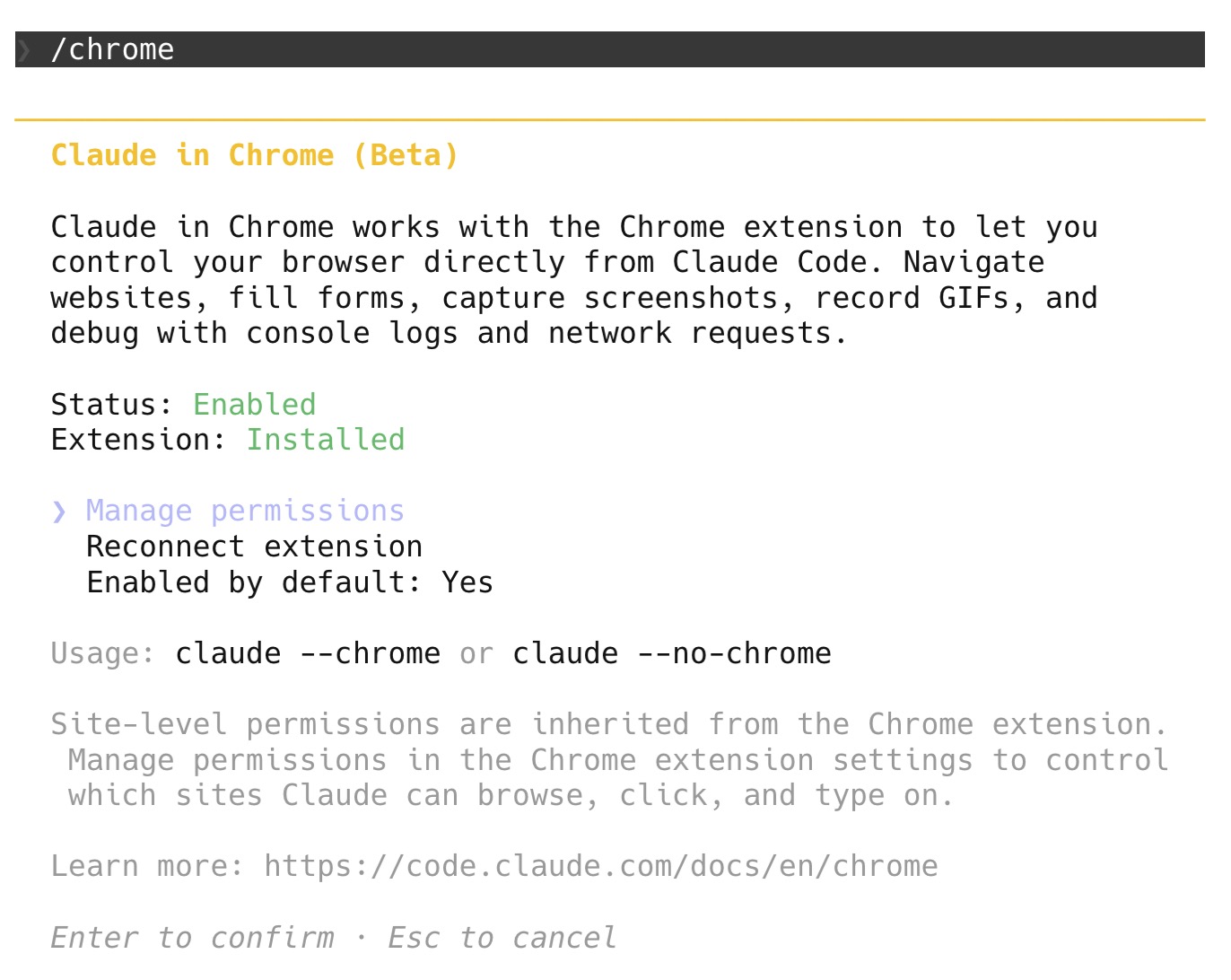
確認 Status 顯示 Enabled、Extension 顯示 Installed 就表示連線成功。如果你想在啟動 Claude Code 時自動啟用,可以用 claude --chrome 指令。
第三步:設定網站權限。 在 Chrome 擴充功能的設定裡,你可以控制 Claude 能操作哪些網站。預設不會開放所有網站,你需要手動允許 Threads、X、LinkedIn 等你要自動發文的平台。
設定完成後,還有幾個容易踩到的坑:
Computer Use MCP 和 Chrome MCP 是兩個不同的東西。 Computer Use 可以控制你的桌面應用程式,但對瀏覽器有讀取限制。Chrome MCP 專門操作瀏覽器,沒有這個限制。不要搞混。
你的 Chrome 必須已經登入社群帳號。 Chrome MCP 操作的是你正在使用的 Chrome profile。如果你在 Chrome 裡沒有登入 Threads,它也沒辦法幫你發文。
從寫作到發布的完整自動化鏈
回頭看整個流程,其實是一條從寫作到發布的自動化鏈:
每一步都是一個 Skill,每一步都只需要一句指令。以前從寫完文章到發完所有社群,可能要花 20-30 分鐘的零碎操作。現在整個流程壓縮到三分鐘,而且不需要在不同平台之間來回切換。
最重要的是,這整套方案不需要申請任何 API key,不需要付費訂閱排程工具,也不需要學習 n8n 這類自動化平台。只要你已經在用 Claude Code,裝一個 Chrome 擴充功能就能開始。
常見問題
瀏覽器自動化發文會不會被平台封鎖帳號?
目前使用下來沒有遇到封鎖的狀況。因為 Chrome MCP 操作的是你自己已登入的瀏覽器,對平台來說跟你手動操作沒有差別,但建議不要短時間內大量發文,保持正常的發文頻率。
除了 Threads、X、LinkedIn,可以用在其他平台嗎?
只要該平台可以在 Chrome 瀏覽器裡操作,理論上都可以,但每個平台的發文流程不同,需要個別設計操作步驟。Facebook 因為反偵測機制太嚴格,目前不建議自動化。
不會寫程式也能用嗎?
可以。整個操作是透過 Claude Code 的 Skill 指令完成的,你只需要輸入 /social-publish 加上文章路徑。Skill 的設定是一個 Markdown 檔案,不需要寫任何程式碼。
Claude Code x 部落格架設(一):搞懂 Astro、Git、Cloudflare
第 7 篇,共 21 篇前幾篇文章我們聊了怎麼用 AI 輔助產文、怎麼把文章自動化發布到社群平台。內容產出的流程順了,但這些內容最後都散落在別人的平台上。接下來這一步,是把內容收回來——建立我們自己的部落格,讓這些文章留在自己的資產底下。
用 Claude Code 架一個部落格,從頭到尾不需要一個下午,但在動手之前,有三個名詞你會不斷遇到:Astro、Git / GitHub、Cloudflare。這篇文章用最白話的方式,讓你在不寫任何一行程式碼的情況下,搞懂它們分別是什麼、為什麼需要它們。
這是「用 Claude Code 架部落格」系列的第一篇。概念搞清楚之後,下一篇我們會直接動手安裝 Astro,讓 Claude Code 幫你把部落格跑起來。
為什麼不用 WordPress 或 Medium?
在解釋那三個名詞之前,先回答一個更根本的問題:為什麼要自己架站?
WordPress 功能強大,但它需要租用主機、安裝資料庫、定期更新安全漏洞。對不懂技術的人來說,光是主機方案的選擇就能卡住一整天。Medium 和方格子之類的平台免去了技術問題,但你寫的內容不真正屬於你——平台改規則、關閉服務、限制流量,你完全無法控制。
我們想要的是:免費、快速、內容完全由自己掌控。
這正是 Astro + Git + Cloudflare 這個組合能做到的事。而且有了 Claude Code,整個過程不需要你懂程式。
Astro 是什麼?你的部落格生成器
想像你要蓋一棟房子。你不需要從燒磚頭開始,去建材行買預製的牆板、門框、窗戶,按照設計圖組裝就好。
Astro 就是你的建材行加上設計圖。
它是一個「靜態網站產生器」。聽起來很技術,但核心概念很簡單:你寫好文章內容,Astro 會自動幫你把內容套進設計好的版型,產生出一個完整的網站。
什麼是靜態網站?
網站分兩種。一種是「動態網站」,像 Facebook 或蝦皮,每個人看到的內容都不一樣,因為它會根據你的帳號、地點、瀏覽紀錄即時產生頁面。另一種是「靜態網站」,每個人看到的內容都一樣——就像一本印好的書,內容不會因為讀者不同而改變。
部落格本質上就是一本書。你寫好一篇文章,所有讀者看到的都是同一篇。這種場景用靜態網站就夠了,而且靜態網站有幾個明顯的優勢:
- 速度快。 不需要等伺服器臨時產生頁面,直接把做好的頁面丟給讀者
- 安全。 沒有資料庫可以被攻擊,沒有後台可以被入侵
- 免費託管。 很多平台(包括等一下會講的 Cloudflare)都提供靜態網站的免費託管
為什麼選 Astro?
靜態網站產生器有很多:Hugo、Jekyll、Next.js、Gatsby,隨便列就是一長串。我們選 Astro 有幾個原因:
第一,它產出的網頁特別輕。 Astro 預設不會載入任何 JavaScript,所以你的部落格打開速度會比大多數網站都快。對 Google 搜尋排名來說,速度快就是優勢。
第二,寫文章的方式很直覺。 Astro 支援用 Markdown 寫文章。Markdown 是一種簡單的格式標記,用 # 表示標題、用 ** 表示粗體,寫起來幾乎跟打記事本一樣。你現在讀的這篇文章,就是用 Markdown 寫的。
第三,Claude Code 對 Astro 很熟。 這一點很關鍵。我們的目標是讓 Claude Code 幫你處理所有技術細節,而 Claude Code 對 Astro 的理解程度非常高,給它指令基本上都能正確執行。
Git 和 GitHub 是什麼?你的備份 + 時光機
蓋好房子之後,你需要一個保險箱來存放設計圖,萬一房子出了問題,可以隨時拿出設計圖重建。
Git 就是那個保險箱,GitHub 就是保險箱的存放地點。
Git:追蹤每一次修改的工具
Git 是一個「版本控制系統」。這個詞聽起來嚇人,但做的事情你一定很熟悉。
想想你寫報告的經驗:期末報告_v1.docx、期末報告_v2.docx、期末報告_最終版.docx、期末報告_最終版(真的最終).docx⋯⋯
Git 做的事情本質上一樣,但更聰明。它不是每次存一份完整的新檔案,而是只記錄「哪裡改了什麼」。你可以隨時回到任何一個版本,看看當時改了什麼,甚至把某次錯誤的修改「撤銷」回去。
對部落格來說,Git 的價值是:
- 每次修改都有紀錄。 你改了文章標題、調了版面配色,Git 都會記住,想回到之前的版本隨時可以
- 不怕改壞。 大膽修改,改壞了隨時回復
- 自動觸發部署。 這一點下面會詳細解釋
GitHub:你的雲端程式碼倉庫
Git 是工具,GitHub 是平台。Git 在你的電腦上運作,GitHub 把你的紀錄同步到雲端。
你可以把 GitHub 想像成 Google Drive,但專門用來存放程式碼和網站檔案。把檔案「推」到 GitHub 上之後,你的程式碼就有了一份雲端備份。電腦壞了、硬碟掛了,你的網站檔案都還在。
不過 GitHub 對部落格來說,最重要的功能不是備份——而是它可以跟 Cloudflare 連動。你把修改推到 GitHub,Cloudflare 會自動偵測到變化,幫你重新產生網站。這表示你更新一篇文章的流程是:
- 在電腦上改好文章
- 用 Git 記錄修改
- 推到 GitHub
- Cloudflare 自動幫你部署
整個過程,Claude Code 可以在一句話之內幫你完成。
Cloudflare 是什麼?你的免費全球發行商
房子蓋好了,設計圖存好了,但房子蓋在深山裡,沒有人找得到。你需要一個地址,還需要一條通往房子的高速公路。
Cloudflare Workers 就是幫你把房子搬到市中心,還免費幫你修了高速公路。
傳統架站 vs Cloudflare Workers
傳統做法是:租一台伺服器(每個月幾百到幾千塊),把網站檔案放上去,自己設定網域、SSL 憑證、安全性防護⋯⋯光是這串術語就足以勸退大部分人。
Cloudflare Workers 把這些全部打包好了:
- 免費託管。 靜態網站不限流量,不用付錢
- 自動部署。 連結 GitHub 之後,每次推送更新就自動重新部署
- 全球 CDN。 Cloudflare 在全世界超過 300 個城市有伺服器節點。不管讀者在台北、東京還是紐約,都能快速載入你的網站
- 自動 HTTPS。 網址前面那個小鎖頭圖示,代表連線是加密的。Cloudflare 自動幫你處理
什麼是 CDN?
CDN(Content Delivery Network,內容傳遞網路)可以理解為「全球複製站」。假設你的部落格主機在美國,一個台灣讀者要看你的文章,資料得從美國傳到台灣,距離遠,速度慢。
CDN 做的事是把你的網站內容複製到全世界各地的伺服器上。台灣讀者訪問你的網站時,資料從台北的節點回應,不用跑到美國去。就像台北市立圖書館——總館在建國南路,但你家附近就有分館,直接去分館借書就好,不用每次都跑去總館。
三個工具怎麼搭配?
說了這麼多,讓我們把三個工具串在一起,看看完整的流程:
你寫文章(Markdown)
↓
Astro 把文章變成網頁
↓
Git 記錄這次的修改
↓
推送到 GitHub(雲端備份)
↓
Cloudflare Workers 偵測到更新
↓
自動部署,全球讀者都能看到整個流程中,你唯一要做的就是寫文章。剩下的步驟,Claude Code 會幫你執行。你跟它說「幫我把這篇文章發布上去」,它就會自動執行 Git 指令、推送到 GitHub,然後 Cloudflare 在幾十秒內幫你部署完成。
如果你還不確定 Claude Code 能做到什麼程度,可以先看看我們整理的八個非工程師也該學 Claude Code 的理由。
需要花多少錢?
這大概是你最關心的問題。
| 項目 | 費用 |
|---|---|
| Astro | 免費(開源軟體) |
| Git | 免費(開源軟體) |
| GitHub | 免費(公開與私有倉庫皆不限制) |
| Cloudflare Workers | 免費(靜態網站方案) |
| Claude Code | 需要 Claude Pro 訂閱,每月 $20 美元 |
| 網域名稱 | 可選,約每年 $10-15 美元 |
除了 Claude Code 的訂閱費和可選的網域名稱之外,架部落格本身的成本幾乎是零。如果你只是想試玩看看,甚至可以先用 Cloudflare 提供的免費子網域(你的名字.workers.dev),連網域費用都省了。不過如果你想累積個人品牌,還是建議想一個名字、買一個自己的網域,讀者記得住,搜尋引擎也會更認真對待。
下一步:動手安裝 Astro
概念講完了,不需要背這篇提到的任何術語。你只需要記得一件事:Astro 負責產生網站,Git 和 GitHub 負責備份和同步,Cloudflare 負責讓全世界都能看到。
下一篇文章,我們會直接動手。你會打開終端機,讓 Claude Code 幫你安裝 Astro、建立第一個部落格專案、選好主題樣式,然後在瀏覽器裡親眼看到你的網站跑起來。從一片空白到「哇,這是我的網站」,整個過程不會超過 30 分鐘。
常見問題
完全不會寫程式,真的能用 Claude Code 架部落格嗎?
可以。Claude Code 能理解中文指令,你只需要告訴它你想做什麼,它會幫你寫程式碼、執行指令、處理設定。整個過程更像是在跟一個工程師對話,而不是自己寫程式。我們有一篇完整的安裝指南,從零開始帶你操作。
部落格文章要用什麼格式寫?
Astro 使用 Markdown 格式。Markdown 是一種用純文字標記的寫法,用 # 表示標題、** 表示粗體、- 表示清單。不需要安裝任何特殊軟體,用記事本就能寫。學習成本大概十分鐘,寫過一篇就會了。而且搭配 AI 產文的流程,你甚至不用自己寫 Markdown,讓 AI 直接產出格式正確的文章檔案就好。
Cloudflare Workers 免費方案有什麼限制?
免費方案每個月可以發布 500 次更新,每天最多讓 10 萬個訪客瀏覽你的網站。對個人部落格來說綽綽有餘,大多數人根本用不到這個上限的十分之一。
Claude Code x 部落格架設(二):安裝 Astro 與 Git 存檔
第 8 篇,共 21 篇上一篇我們搞懂了 Astro、Git、Cloudflare 這三個名詞,概念有了,這篇直接動手——讓 Claude Code 幫你安裝 Astro,建立你的第一個部落格專案,然後在瀏覽器裡親眼看到它跑起來。
整個過程你不需要記任何指令,你要做的只有兩件事:跟 Claude Code 說話,然後看它幫你搞定。
動手之前,確認兩件事
在讓 Claude Code 安裝 Astro 之前,你的電腦需要兩樣東西:
第一,Claude Code 已經裝好。 如果還沒裝,先照著這篇安裝指南走完流程,大概十分鐘。
第二,Node.js 已經裝好。 Node.js 是讓 Astro 能在你電腦上運作的底層引擎。你不需要知道它的細節,只需要確認有裝就好。打開 Warp,輸入:
node -v如果看到類似下圖的版本號,代表已經裝好了:
 如果看到「command not found」之類的訊息,別緊張——直接跟 Claude Code 說「幫我安裝 Node.js」,它會幫你處理。
如果看到「command not found」之類的訊息,別緊張——直接跟 Claude Code 說「幫我安裝 Node.js」,它會幫你處理。
讓 Claude Code 建立 Astro 專案
準備好了,我們分四步走:
第一步,建立專案資料夾 在桌面上按右鍵,新增一個資料夾,命名為 my-blog。這個資料夾就是你部落格的家,所有檔案都會放在裡面。
第二步,打開 Warp 終端機 如果你照著安裝指南走過一遍,電腦裡應該已經有 Warp 了。直接打開它就好。
第三步,進入你的專案資料夾 在 Warp 裡輸入 cd (cd 後面加一個空格),然後把桌面上的 my-blog 資料夾用滑鼠直接拖曳到 Warp 視窗裡,它會自動填入資料夾的完整路徑,按下 Enter 就進去了。Windows 使用者如果拖曳沒反應,可以手動輸入路徑:cd C:\Users\你的使用者名稱\Desktop\my-blog。
第四步,啟動 Claude Code 在 Warp 裡輸入 claude,按下 Enter。你會看到 Claude Code 的互動介面出現——現在你可以直接跟它對話了。
跟它說:
幫我用 Astro 在目前的資料夾建立一個部落格專案Claude Code 會開始執行一連串操作,你會看到畫面上跑出很多文字,像下面這樣:
那是它在背後幫你做這些事:
- 用 Astro 的官方工具產生部落格的初始檔案
- 安裝所有需要的套件
- 設定好基本的專案結構
整個過程大概一到兩分鐘,跑完之後,Claude Code 會告訴你專案建好了。
這時候你可以繼續跟它說:
幫我啟動開發伺服器等幾秒鐘,它會回你一個網址,像下圖中的 http://localhost:4323(數字可能不同,不影響):
把這個網址貼到瀏覽器裡——你會看到一個有模有樣的部落格頁面:
沒錯,你的網站已經跑起來了。
Astro 專案裡面有什麼?
你不需要另外開 Finder 或檔案總管來看專案內容。在 Warp 的頂部工具列,點選左邊數過來第二個 icon(File explorer),側邊欄就會展開目錄結構:
第一眼看到這麼多檔案可能會有點慌,但其實結構很清楚。我們用一個比喻來理解:把整個專案想像成一間餐廳。
my-blog/
├── src/
│ ├── pages/ ← 菜單(每一頁對應網站上的一個頁面)
│ ├── layouts/ ← 餐廳裝潢(頁面的整體版型)
│ ├── components/ ← 餐具和擺盤(可重複使用的小元件)
│ └── content/ ← 食材倉庫(你寫的文章放這裡)
├── public/ ← 門口的招牌和裝飾(圖片、favicon 等靜態檔案)
├── astro.config.mjs ← 餐廳的營業登記(Astro 的設定檔)
└── package.json ← 食材供應商清單(專案用了哪些套件)不用全部記住。日常寫部落格,你最常碰的只有一個地方。
你真正需要關心的:content 資料夾
src/content/ 是你放文章的地方。Astro 的部落格模板通常會在裡面建一個 blog 資料夾,結構像這樣:
src/content/blog/
├── first-post.md
├── second-post.md
└── third-post.md每個 .md 檔就是一篇文章。打開其中一個,長這樣:
---
title: "我的第一篇文章"
description: "這是文章的簡短描述"
pubDate: 2026-04-13
---
文章內容寫在這裡。
用 # 表示大標題,用 ** 表示粗體。上面用 --- 包起來的區塊叫「frontmatter」,你可以把它想成文章的「基本資料卡」——標題、描述、發布日期都寫在這裡。下面就是文章本文,用 Markdown 格式書寫。
要新增一篇文章?建一個新的 .md 檔就好。或者更簡單——跟 Claude Code 說「幫我新增一篇文章,標題是 XXX」,它會幫你建好檔案、填好 frontmatter,你只要寫內容。
其他資料夾快速導覽
雖然日常不太會碰,但知道它們的用途,遇到問題時比較不會慌。
pages(菜單):這個資料夾裡的每一個檔案,對應網站上的一個頁面。index.astro 就是首頁,about.astro 就是「關於」頁面。Astro 會自動根據檔案名稱產生對應的網址——你不需要設定任何路由規則。
layouts(裝潢):定義頁面的整體架構。頂部的導覽列、底部的頁尾、側邊欄——這些每一頁都長一樣的部分,就放在 layout 裡。寫文章時不用管它,但如果你想改網站的整體外觀,跟 Claude Code 說一聲,它知道該改哪裡。
components(餐具):可以重複使用的小零件。像是文章列表的卡片、社群分享按鈕、標籤雲。你不需要自己寫這些,Claude Code 很擅長處理元件。
public(招牌):放圖片、網站圖示(favicon)這類不需要被 Astro 處理的靜態檔案。你丟一張 logo.png 進去,網站上就能直接用 /logo.png 存取它。
選一個好看的主題
Astro 預設的部落格模板功能完整,但外觀比較素,好消息是 Astro 有大量免費的部落格主題可以選擇,從極簡風到功能豐富的都有。
挑選主題的方式很簡單:在主題頁面上瀏覽,左側已經幫你篩選好 Blog 類別和免費條件,看到喜歡的點進去,每個主題都有 Demo 可以預覽實際效果。
確定喜歡之後,找到主題頁面上的 GitHub 連結,複製它的網址。
然後回到 Claude Code,跟它說:
幫我用這個 Astro 主題重新建立部落格專案:https://github.com/satnaing/astro-paperClaude Code 會幫你把主題的原始碼下載下來,安裝好所有套件,你只需要再跑一次開發伺服器,就能在瀏覽器裡看到新的樣子。不滿意?換一個主題的 GitHub 連結再說一次就好,整個過程不到五分鐘。
把網站名稱換成你自己的
專案建好之後,網站上顯示的名稱、描述還是模板預設的內容,第一件想做的事,大概就是把它改成自己的名字。
不需要知道設定檔在哪裡,直接跟 Claude Code 說:
把網站名稱改成「我的學習筆記」,網站描述改成「記錄我的學習心得和生活觀察」Claude Code 會自動找到存放這些設定的檔案——通常在 astro.config.mjs 或主題自己的設定檔裡——然後幫你改好。重新整理瀏覽器,你就會看到新的名稱出現在網站標題和瀏覽器分頁上。
如果你用的主題有 logo,也可以說「幫我把 logo 換成這張圖片」,把圖片丟進專案資料夾就好。
調整選單內容
大部分主題預設的選單會有幾個連結:首頁、文章列表、關於頁面。你可能想加一個「聯絡我」,或者把不需要的項目拿掉。
跟 Claude Code 說:
幫我把導覽列的選單改成:首頁、文章、關於我、聯絡我它會去找主題中負責選單的設定或元件,幫你調整項目和連結。不同的主題處理選單的方式不太一樣——有些用設定檔,有些直接寫在元件裡——但這些差異 Claude Code 都能自己判斷,你不需要管。
想調整選單的順序?想讓某個連結另開分頁?說一聲就好。
新增你的第一篇文章
選單調好了,網站名稱也改了,接下來最重要的事——寫一篇文章。
跟 Claude Code 說:
幫我新增一篇部落格文章,標題是「我的第一篇文章」,內容先寫一段自我介紹它會在 src/content/blog/(或主題指定的文章資料夾)底下建一個新的 Markdown 檔案,幫你填好 frontmatter 裡的標題、日期、描述,甚至會幫你起個草稿。你只需要打開檔案,把內容改成你想寫的東西。
想要更進階一點?你可以一次給它更多資訊:
幫我新增一篇文章,標題是「搬家到新城市的第一個月」,
描述是「記錄搬到台北之後的生活適應」,
標籤是「生活」和「台北」Claude Code 會根據主題支援的 frontmatter 欄位,自動幫你填進去。存檔後重新整理瀏覽器,新文章就會出現在文章列表裡。從跟 Claude Code 說話到看到文章上線,不到一分鐘。
之後要修改文章也一樣簡單:「幫我把那篇搬家的文章標題改成……」「幫我在第二段後面加一張圖片」。Claude Code 知道檔案在哪裡,直接幫你改。
如果你打算認真經營部落格,不只是偶爾發一篇,Claude Code 還有一個更強的玩法:用 Skill 把你的寫作流程變成一套可重複執行的指令。你可以教它「每次寫文章前先做關鍵字研究、用什麼語氣、文章結構怎麼安排」,之後只要一句「幫我寫一篇關於 XX 的文章」,它就會按照你定義好的流程走完全部步驟。我們在這篇文章有完整的實作紀錄,等你熟悉基本操作之後,值得回來看看。
用 Git 幫你的專案存檔
到目前為止,所有修改都只存在你的電腦上。如果不小心刪錯檔案、改壞設定,沒有任何備份可以回復。這時候就需要 Git 了——上一篇提到的那個「時光機」。
為什麼不用 iCloud 或 Dropbox 備份?
你可能會想:「我把專案資料夾放到 iCloud Drive 或 Dropbox 裡,不就自動備份了嗎?」
聽起來合理,但實際上會出問題。一個 Astro 專案裡有一個叫 node_modules 的資料夾,裝著幾萬個小檔案(你在 Warp 的 File explorer 裡有看到它)。iCloud 和 Dropbox 會試圖同步這些檔案,結果就是:同步速度慢到不行、佔用大量上傳頻寬,有時候還會因為檔案鎖定衝突,導致專案跑不起來。
Git 的做法不一樣。它只追蹤你真正需要的檔案(原始碼和文章),自動忽略 node_modules 這類可以隨時重新安裝的東西。而且 Git 不只是備份——它記錄每一次修改的差異,你可以隨時回到任何一個版本,看看當時改了什麼。雲端硬碟做不到這件事。
安裝 Git 並初始化專案
如果你照著安裝指南走過一遍,Git 應該已經裝好了。確認一下:
git --version看到版本號就代表沒問題。接下來跟 Claude Code 說:
幫我初始化 Git,然後把目前的檔案都做第一次存檔Claude Code 會幫你執行三件事:
- 初始化 Git 倉庫 — 在專案裡建立 Git 的追蹤系統
- 設定忽略規則 — 自動排除
node_modules等不需要追蹤的檔案 - 建立第一個 commit — 把目前所有檔案存成第一個版本
「commit」你可以理解成 Word 或 Excel 裡的「另存新檔」,但更聰明——它不會產生一堆 v1、v2、最終版 的副本,而是在同一個檔案上記錄每一次修改的差異。每做一次 commit,Git 就記住你的專案在那個當下長什麼樣子。
改完之後:存檔的流程
之後每次你改了東西——修改文章、調整選單、換了主題——都可以跟 Claude Code 說:
幫我把這次的修改存檔Claude Code 會幫你做一次 commit,附上一句簡短的說明,描述這次改了什麼,這些存檔會累積成一條時間線,你隨時可以回頭看。
推到 GitHub:雲端備份
存檔只在你的電腦上。如果電腦壞了,存檔也跟著消失,所以我們要把這些存檔「推」到 GitHub——上一篇介紹過的雲端程式碼倉庫。
在推之前,你需要一個 GitHub 帳號,如果還沒有,先到 github.com/signup 註冊,流程跟一般網站註冊差不多:填 email、設定密碼、選使用者名稱,然後到信箱點確認連結就好,免費帳號就夠用了,不需要付費方案。
帳號準備好之後,跟 Claude Code 說:
幫我在 GitHub 上建立一個私有倉庫,然後把專案推上去這裡特別提醒:記得說「私有倉庫」。GitHub 的倉庫分公開和私有兩種,公開倉庫任何人都能看到你的程式碼和文章內容,私有倉庫只有你自己(和你授權的人)看得到。部落格在正式上線之前,沒有理由讓全世界看到你的草稿。
第一次推的時候,Claude Code 會請你登入 GitHub 帳號進行授權,照著它的提示走就好,通常會打開瀏覽器讓你點一下「授權」,完成之後,你會看到類似這樣的畫面:
看到最後一行顯示你的 GitHub 倉庫網址,就代表專案已經有了一份雲端備份。
之後每次做完修改,想同步到 GitHub,只要說:
幫我把修改推到 GitHub一句話搞定。整個「修改 → 存檔 → 推到雲端」的流程,你不需要記任何 Git 指令,全部交給 Claude Code。
改東西不需要怕
有了 Git 當靠山,這個心理關卡就不存在了。
假設你請 Claude Code 改了網站的配色,結果改完之後整個版面歪掉了。不用慌,跟它說:
剛才的修改把版面弄壞了,幫我還原到上一次存檔的狀態Claude Code 會用 Git 把所有檔案回復到上一次 commit 的樣子,就像什麼事都沒發生過。
如果你想回到更早之前的版本——比如三天前的狀態——也可以說:
幫我看一下最近的存檔紀錄Claude Code 會列出每一次 commit 的時間和說明,你挑一個想回去的版本,告訴它「幫我回到那個版本」就好,就像 Word 裡的「復原」按鈕,但不只能回到上一步——你可以回到任何一個存檔過的版本。
還有一種情況:你只想還原某一個檔案,其他修改要保留,比如你改了三個檔案,其中一個改壞了:
幫我把 src/pages/index.astro 還原到上一次存檔的版本,其他檔案不要動Claude Code 知道怎麼只復原指定的檔案。
記住一個原則:改東西之前先存檔,改壞了就還原。養成這個習慣,你就可以大膽嘗試任何修改,而且在推到 GitHub 之前,你的修改只在自己的電腦上,全世界只有你看得到。所以儘管改,改到滿意再說。
到目前為止你完成了什麼?
讓我們回顧一下。從第一篇的概念介紹到現在,你已經:
- 搞懂 Astro、Git、Cloudflare 的角色
- 用 Claude Code 安裝了 Astro
- 建立了第一個部落格專案
- 知道專案裡每個資料夾的用途
- 改好網站名稱、調整了選單
- 新增了第一篇文章
- 用 Git 做了第一次存檔,並推到 GitHub
- 在自己的電腦上看到網站跑起來
整個過程,你沒有手動輸入任何 Git 指令。
下一篇,我們要把這個網站部署到 Cloudflare Workers,讓全世界都能看到。從「我電腦上有個網站」變成「我有一個真正的網址」——這一步同樣交給 Claude Code 來處理。
常見問題
安裝 Astro 的時候出現錯誤怎麼辦?
最常見的原因是 Node.js 版本太舊。Astro 需要 Node.js 18 以上的版本,建議直接裝最新版,跟 Claude Code 說「幫我檢查 Node.js 版本,如果太舊就幫我更新」,它會幫你處理,如果還是不行,把錯誤訊息貼給 Claude Code,它通常能直接判斷問題出在哪裡。
Astro 的主題可以之後再換嗎?
可以,但換主題比較像「搬家」而不是「換窗簾」。不同主題的檔案結構可能不一樣,搬過去需要調整一些設定, 好消息是 Claude Code 對 Astro 主題的結構很熟悉,跟它說你想換主題,它會幫你處理遷移的細節。建議在部落格初期、文章還不多的時候就選定主題。
關掉終端機之後網站就不見了,正常嗎?
正常。開發伺服器只是暫時在你電腦上跑的預覽環境,關掉終端機它就會停止。你的檔案都還在,下次想看的時候,跟 Claude Code 說「幫我啟動開發伺服器」就會再跑起來。等我們在下一篇把網站部署到 Cloudflare Workers 之後,網站就會 24 小時在線,不需要你的電腦一直開著。
Claude Code x 部落格架設(三):部署上線與自訂網域
第 9 篇,共 21 篇上一篇我們把 Astro 裝好了,專案建起來了,Git 也設定完畢,甚至推到 GitHub 了。打開瀏覽器,localhost:4321 跑得好好的——但只有你自己看得到。
這篇要做的事情很單純:讓你的部落格從「我電腦上的網站」變成「任何人輸入網址就能看到的網站」。整個過程大概十五分鐘,你只需要註冊一個帳號,然後跟 Claude Code 說幾句話。
Cloudflare Workers 是什麼?
第一篇我們用過一個比喻:你的網站像一棟蓋好的房子,但蓋在深山裡,沒有人找得到。Cloudflare 就是幫你把房子搬到市中心,還免費幫你修了一條高速公路。
現在你的部落格就是那棟蓋好的房子——localhost:4321 是你家的門牌,但只有你自己走得到。這篇要做的事,就是把它搬到市中心去。
搬過去之後你會得到什麼?
- 完全免費。 不限流量,不限頻寬,個人部落格用免費方案就綽綽有餘
- 全球都快。 Cloudflare 在超過 300 個城市有伺服器,不管讀者在台北還是紐約,網站都能快速載入
- 自動更新。 你每次把修改推到 GitHub,Cloudflare 會自動幫你重新產生最新版的網站,不需要手動操作
註冊 Cloudflare 帳號
到 Cloudflare 註冊頁面,你可以用 Google、Apple 或 GitHub 帳號一鍵註冊,也可以填 Email 和密碼。不需要填信用卡,免費帳號就夠用了。
註冊完畢後,你會看到 Cloudflare 的 Dashboard。不需要在上面做任何設定——接下來的步驟全部交給 Claude Code。
把網站部署到 Cloudflare Workers
確認你的 Astro 專案已經推到 GitHub(上一篇的最後一步)。如果還沒推,跟 Claude Code 說「幫我把專案推到 GitHub」就好。
準備好之後,我們要在 Cloudflare Dashboard 上建立專案,並且直接連結 GitHub。這樣做的好處是——以後每次推程式碼到 GitHub,Cloudflare 就會自動幫你更新網站,不需要手動操作。
第一步:建立專案並連結 GitHub
登入 Cloudflare Dashboard,點選左側的 Workers 和 Pages,然後點右上角的建立應用程式。
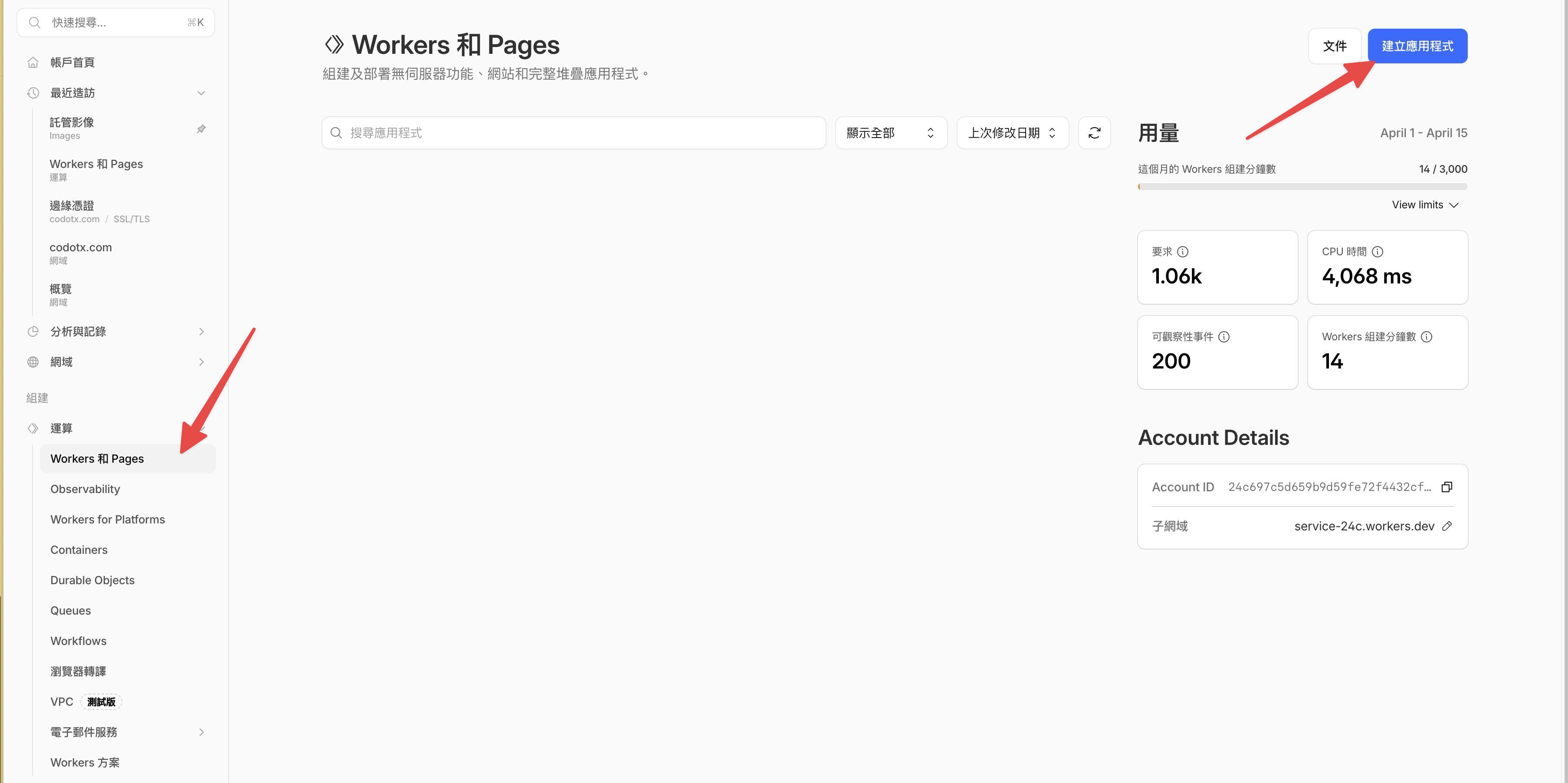
接下來會看到幾個選項,點 Continue with GitHub。
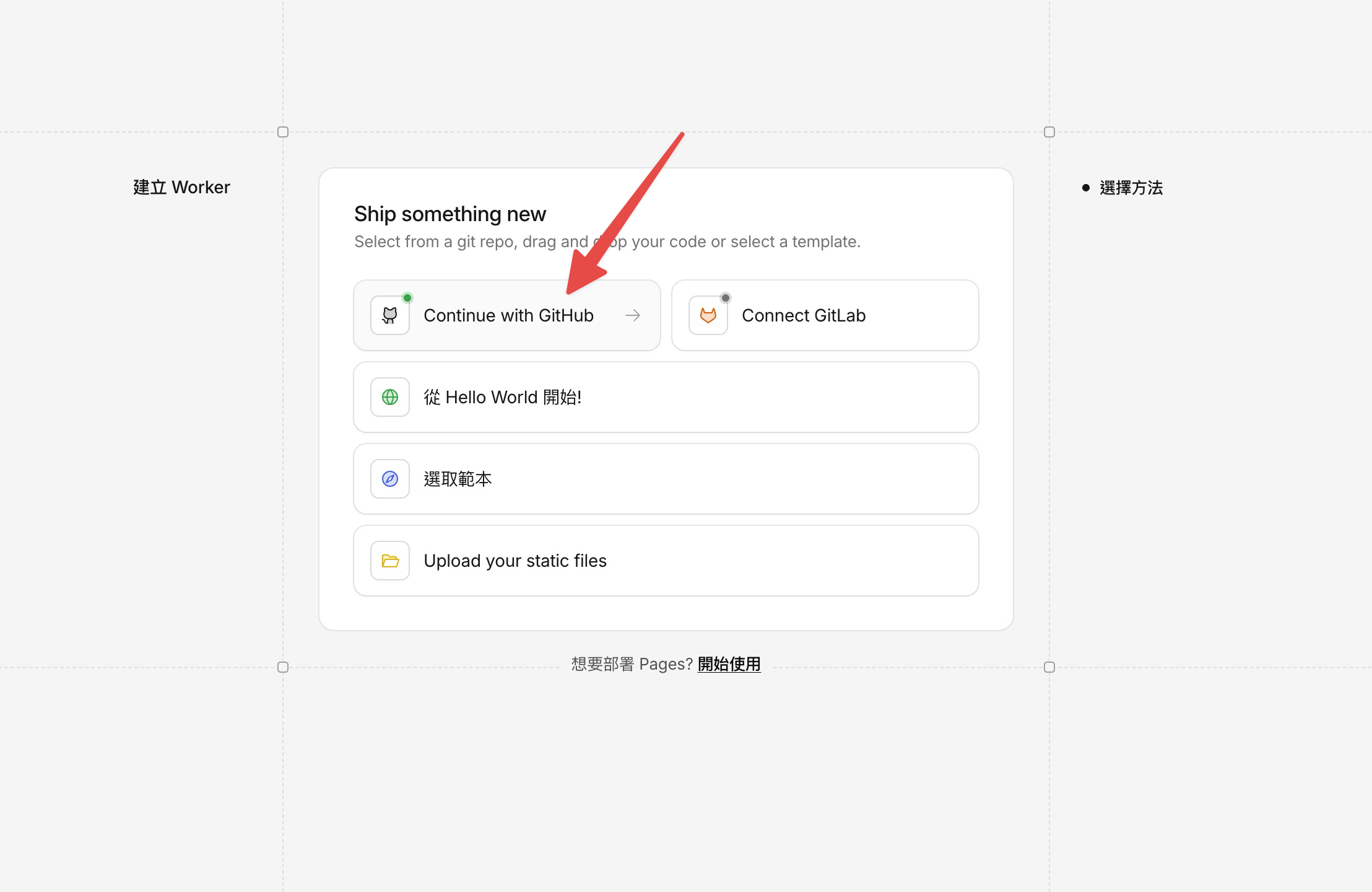
如果是第一次連結,Cloudflare 會請你授權存取 GitHub。授權的畫面跟上一篇推到 GitHub 時差不多——點「授權」就好。
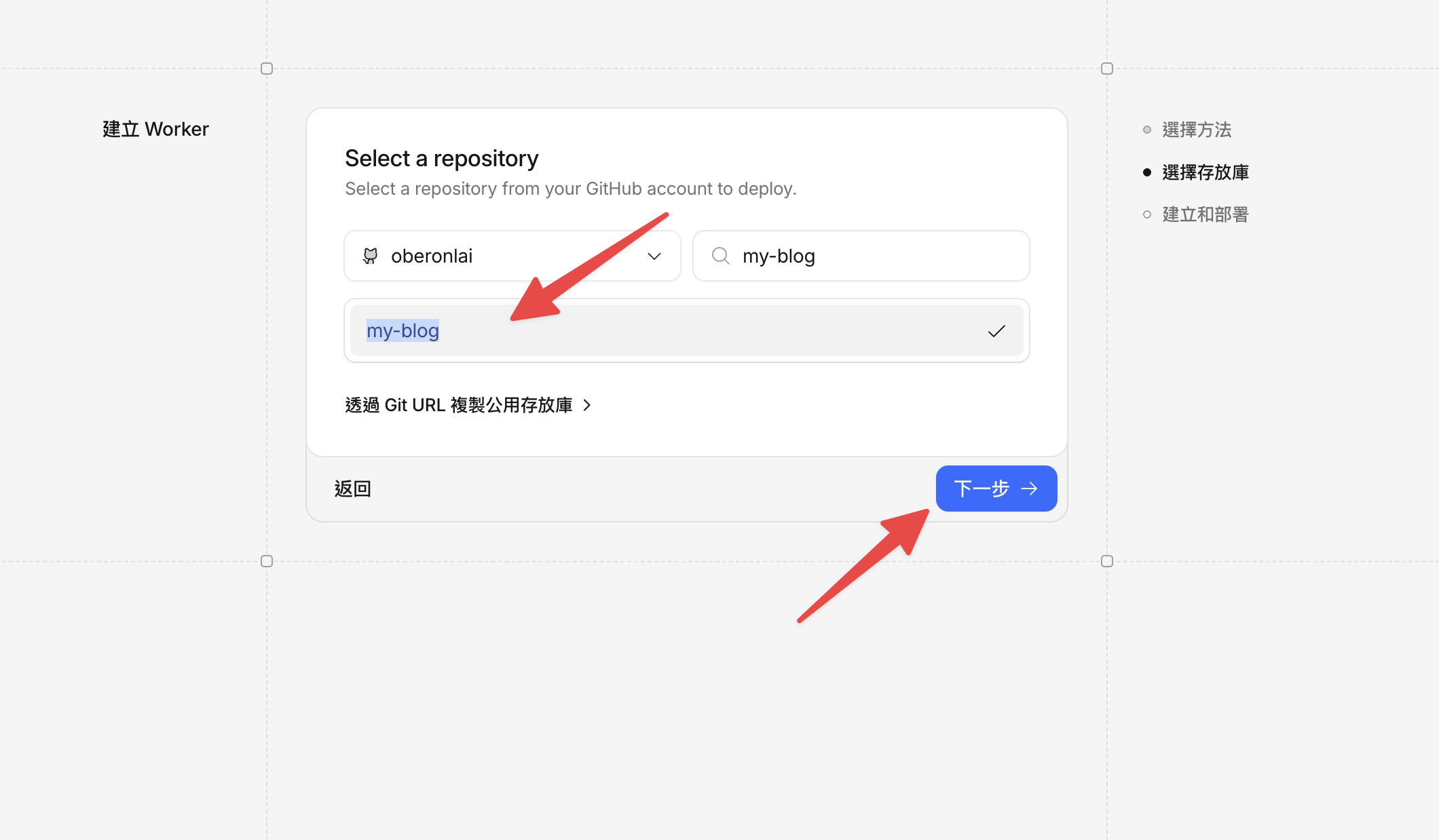
第二步:選擇存放庫和設定建構
授權完成後,你會看到存放庫選擇頁面。在搜尋框裡輸入 my-blog,找到我們的專案後點選它,然後點下一步。
接下來是建構設定。Cloudflare 會自動幫你填好:
- 專案名稱:
my-blog(跟你的存放庫名稱一樣) - 組建命令:
npm run build - 部署命令:
npx wrangler deploy
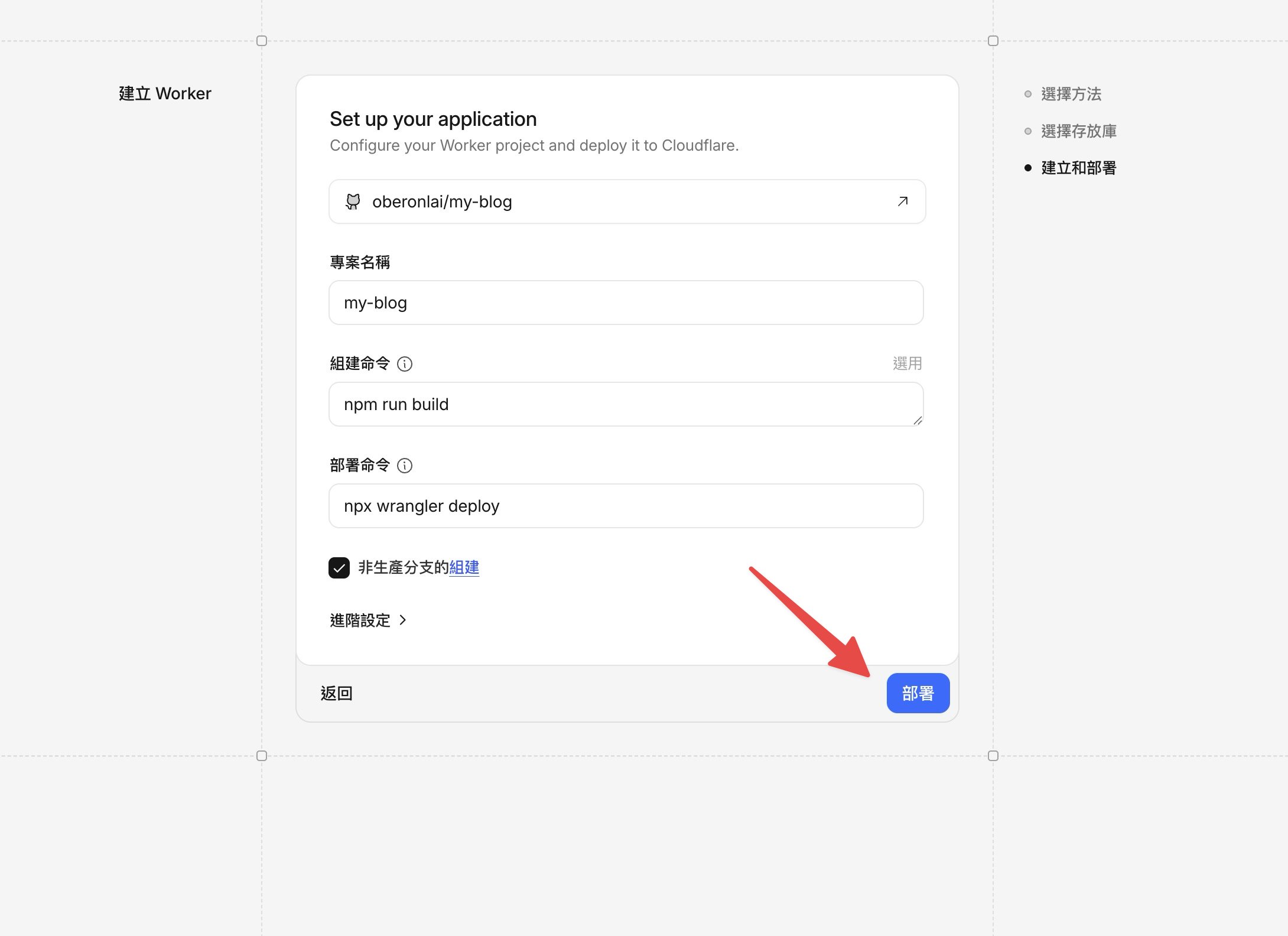
不需要改任何東西,直接點部署。
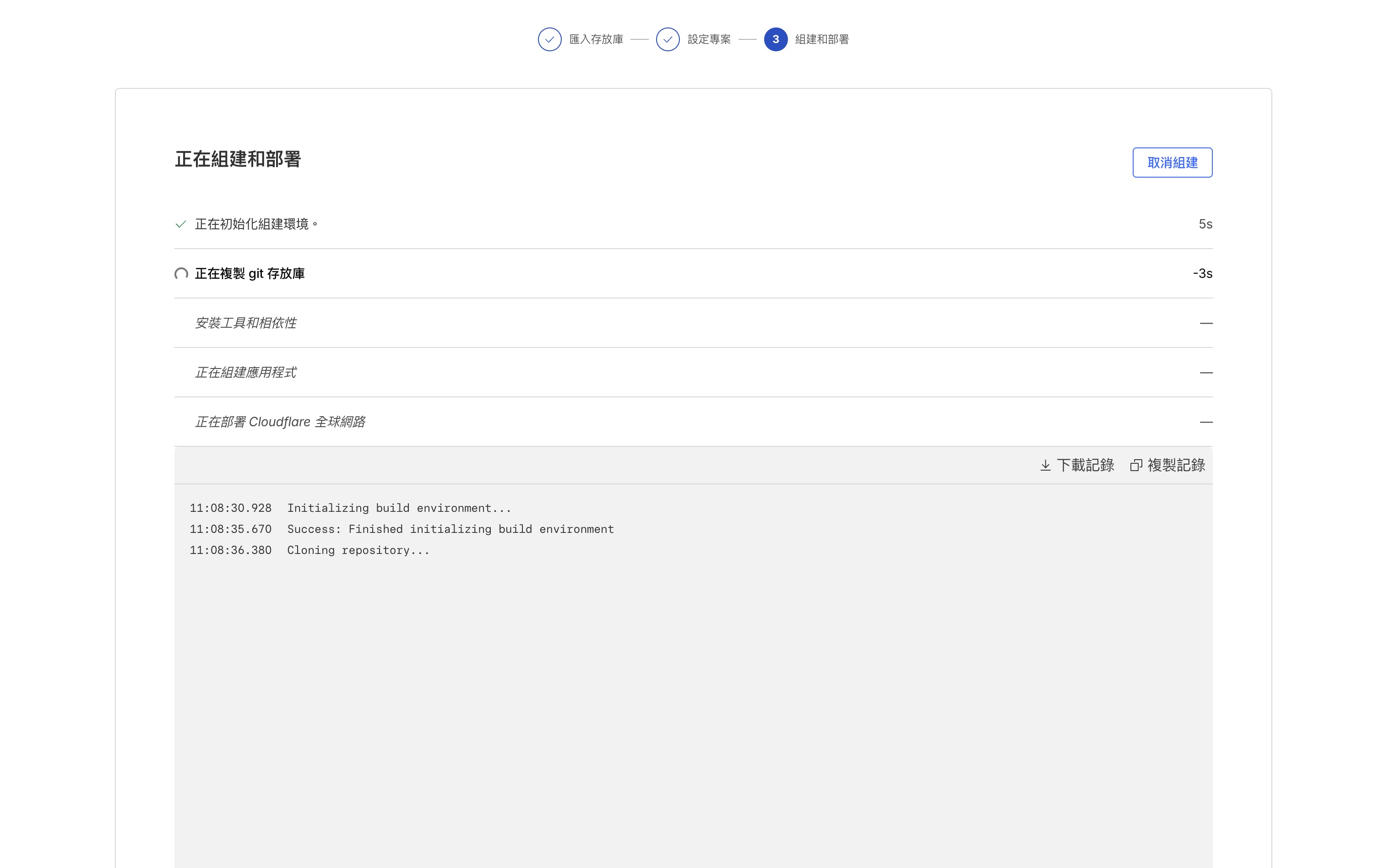
第三步:等它跑完,打開你的網站
Cloudflare 會開始建構你的網站。畫面上會顯示部署進度——初始化組建環境、複製 git 存放庫、安裝工具和相依性、正在組建應用程式、正在部署 Cloudflare 全球網路。整個過程大概一到兩分鐘。
建構完成後,你會看到專案的概觀頁面。點右上角的造訪按鈕:
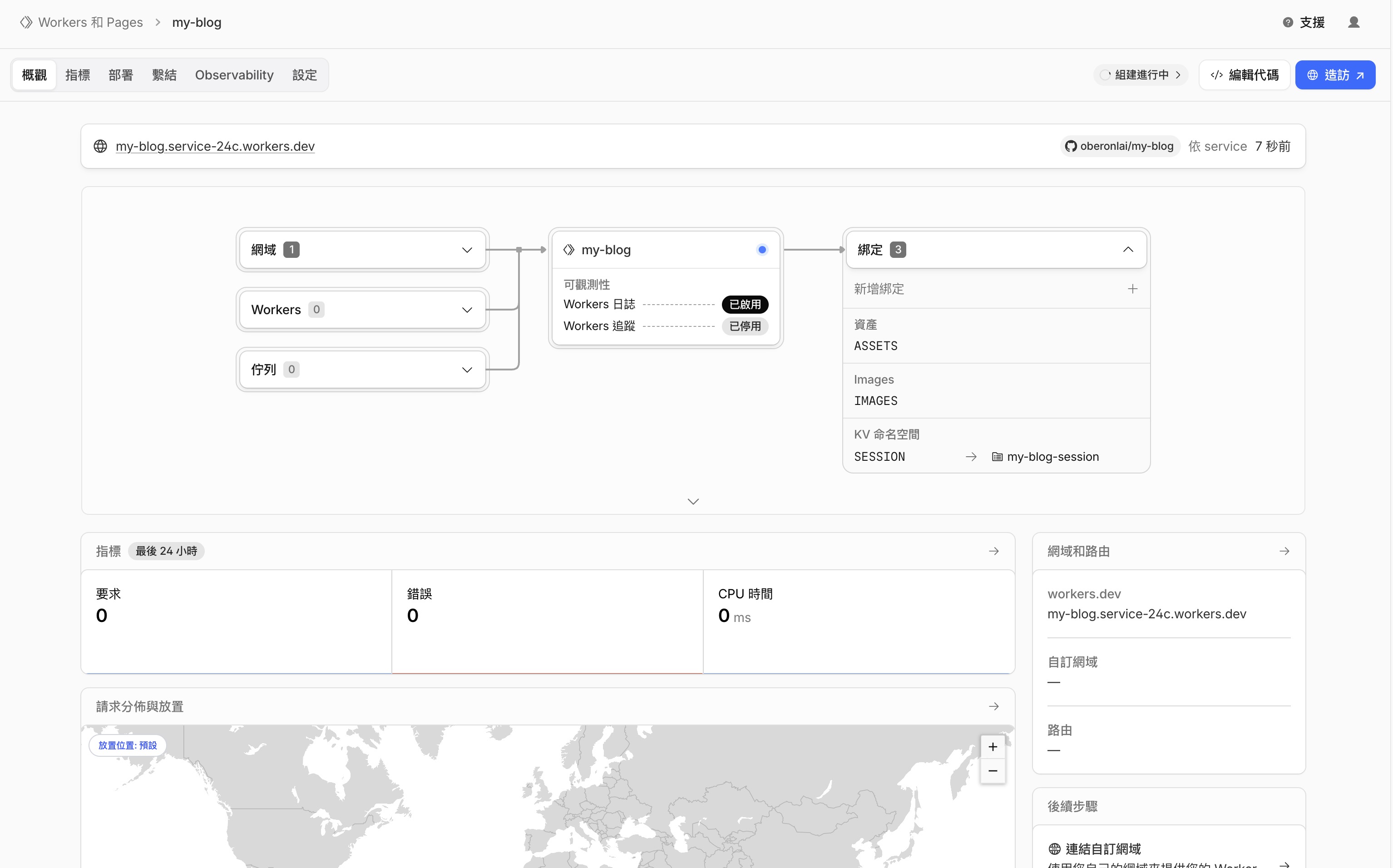
瀏覽器會打開你的網站——跟 localhost:4321 一模一樣的頁面。
差別是:現在全世界都能看到它了。
你可以把這個網址傳給朋友試試看,不管對方在哪裡,都能打開你的部落格。而且因為我們直接連結了 GitHub,之後更新文章時不需要再回到這個頁面——Cloudflare 會自動處理。
更新文章之後怎麼辦?
因為我們已經把 Cloudflare Workers 跟 GitHub 連在一起了,更新網站只需要一句話。
假設你改了一篇文章的標題,或者新增了一篇文章,跟 Claude Code 說:
幫我把這次的修改推到 GitHubClaude Code 會幫你做 Git commit 和 push。推上去之後,Cloudflare 會自動偵測到變更,幾十秒內重新部署。你不需要打開任何後台,不需要按任何按鈕。
整個流程是這樣的:
你修改文章
↓
跟 Claude Code 說「幫我推到 GitHub」
↓
Claude Code 自動 commit + push
↓
Cloudflare 偵測到更新,自動重新部署
↓
幾十秒後,網站上就是最新的版本你唯一要做的就是寫文章,然後說一句「幫我推到 GitHub」。
想要自己的網域名稱嗎?
Cloudflare 給你的免費網址是 workers.dev 結尾的,功能完全正常,但網址不太好記。如果你想要一個像 my-blog.com 這樣的專屬網址,可以直接在 Cloudflare 裡面買,然後綁到你的 Workers 專案上。
這不是必要的步驟。如果你還在摸索階段,先用免費網址就好,等你確定要認真經營了再買也不遲。以下是購買以及綁定網址的流程:
買網域
在 Cloudflare Dashboard 左側選單,點網域 → 註冊。
在搜尋框裡輸入你想要的網域名稱,按搜尋。Cloudflare 會列出可以購買的網域和價格:
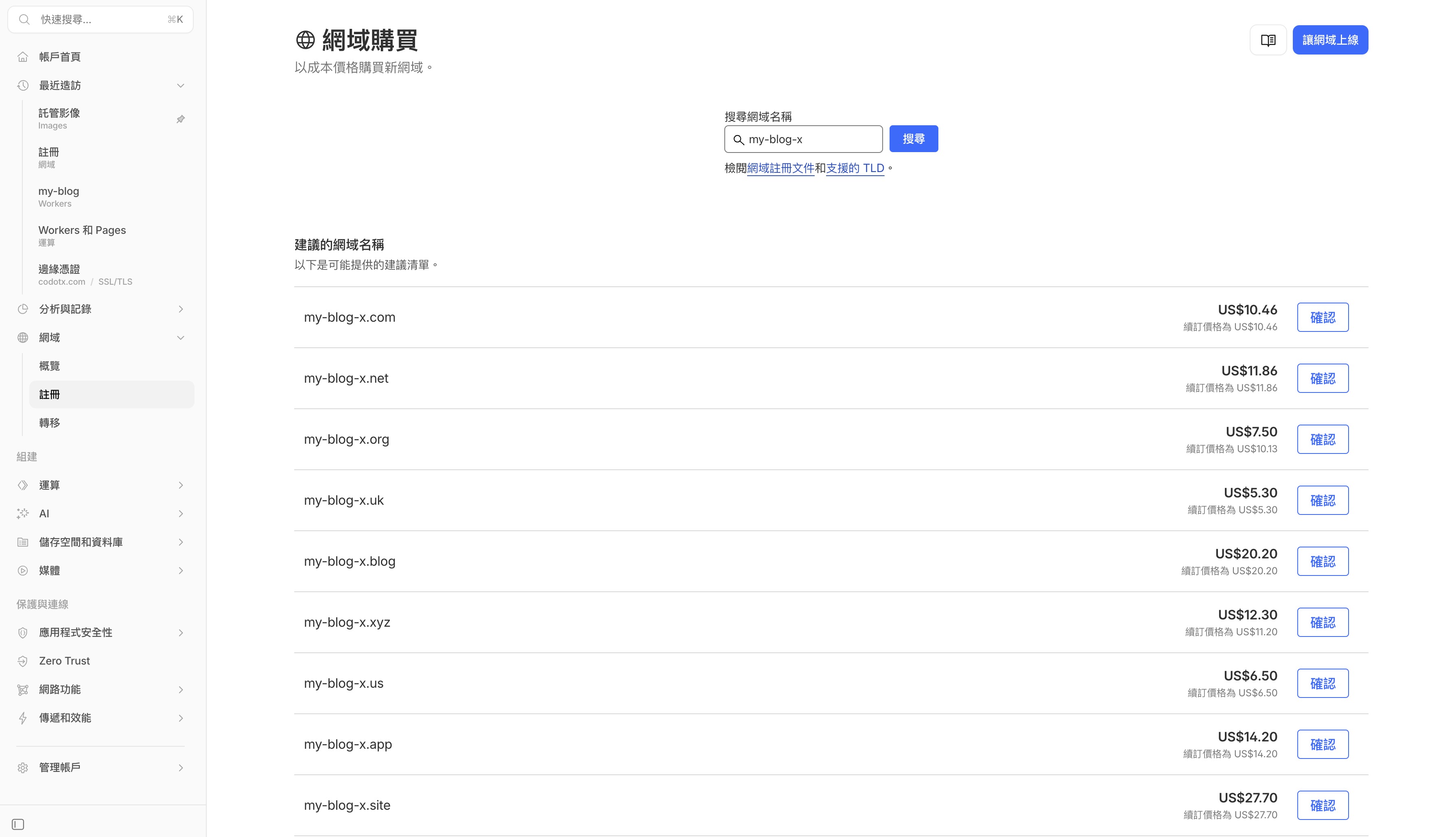
.com 一年大概 US$10 左右,看你選什麼結尾。挑一個喜歡的,點確認,填好付款資訊和註冊者資料就完成了。
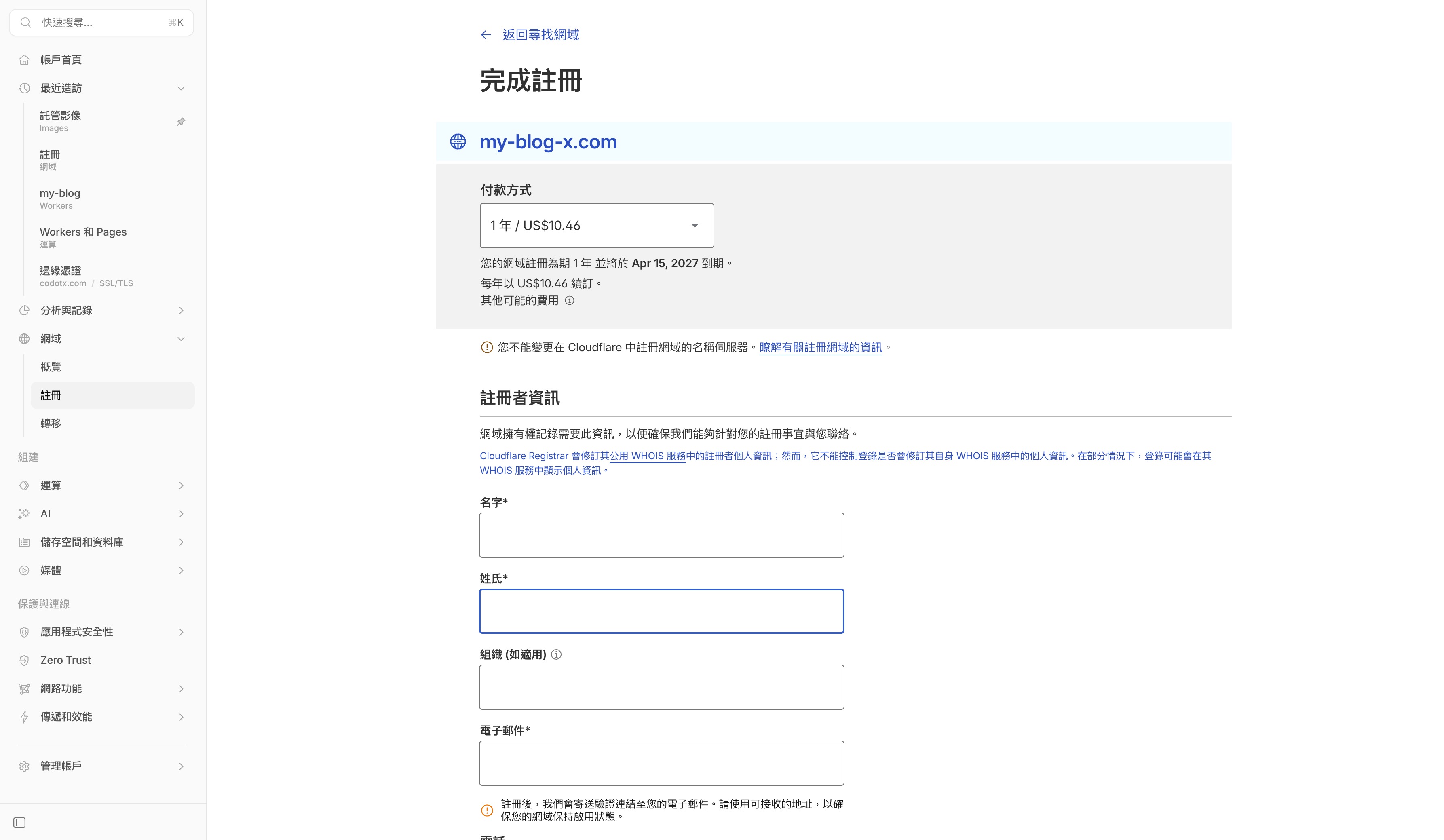
把網域綁到 Workers 專案
網域買好之後,回到你的 Workers 專案頁面,點上方的設定分頁。在「網域和路由」區塊,點 + 新增。
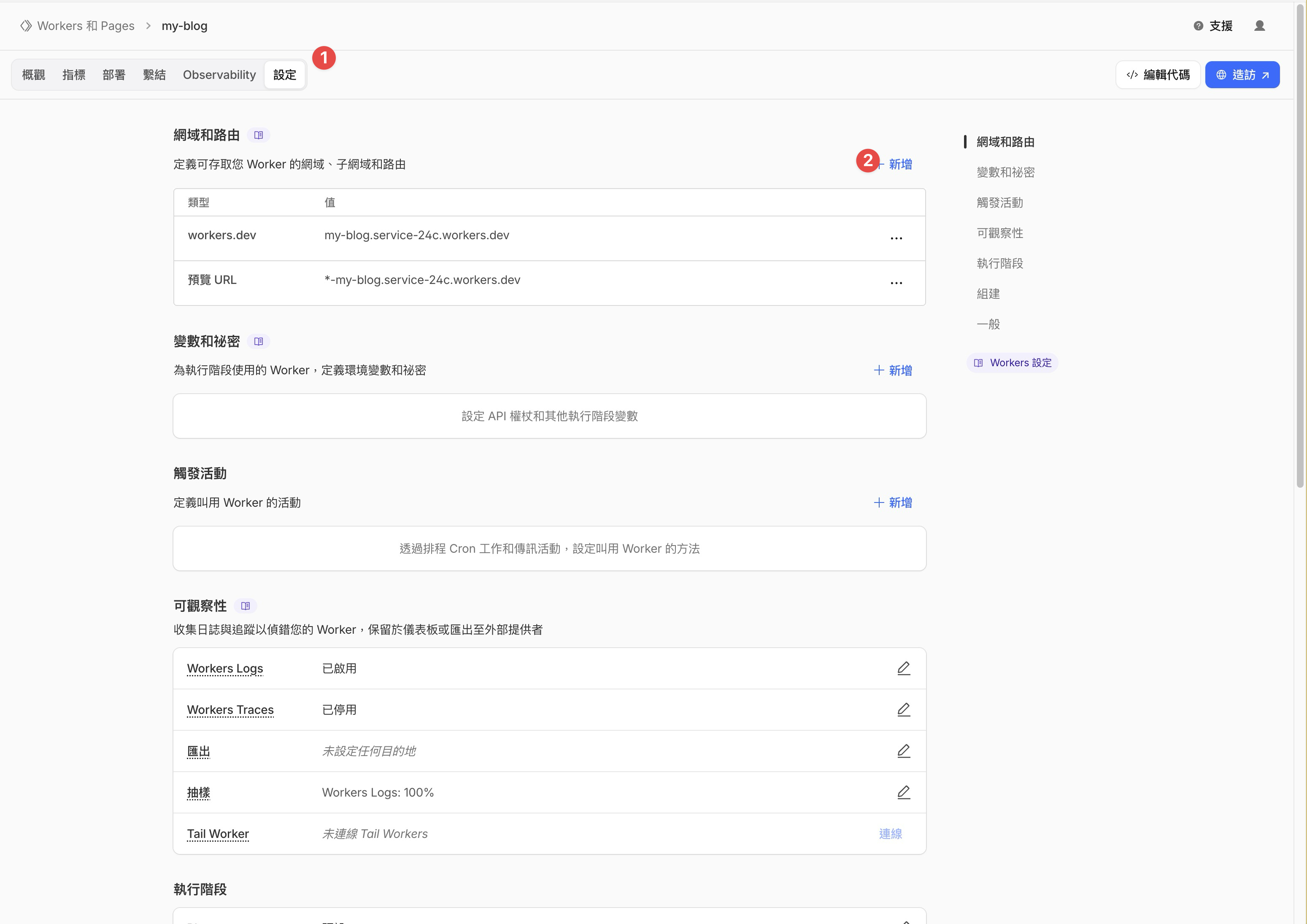
右邊會彈出一個面板,選自訂網域。
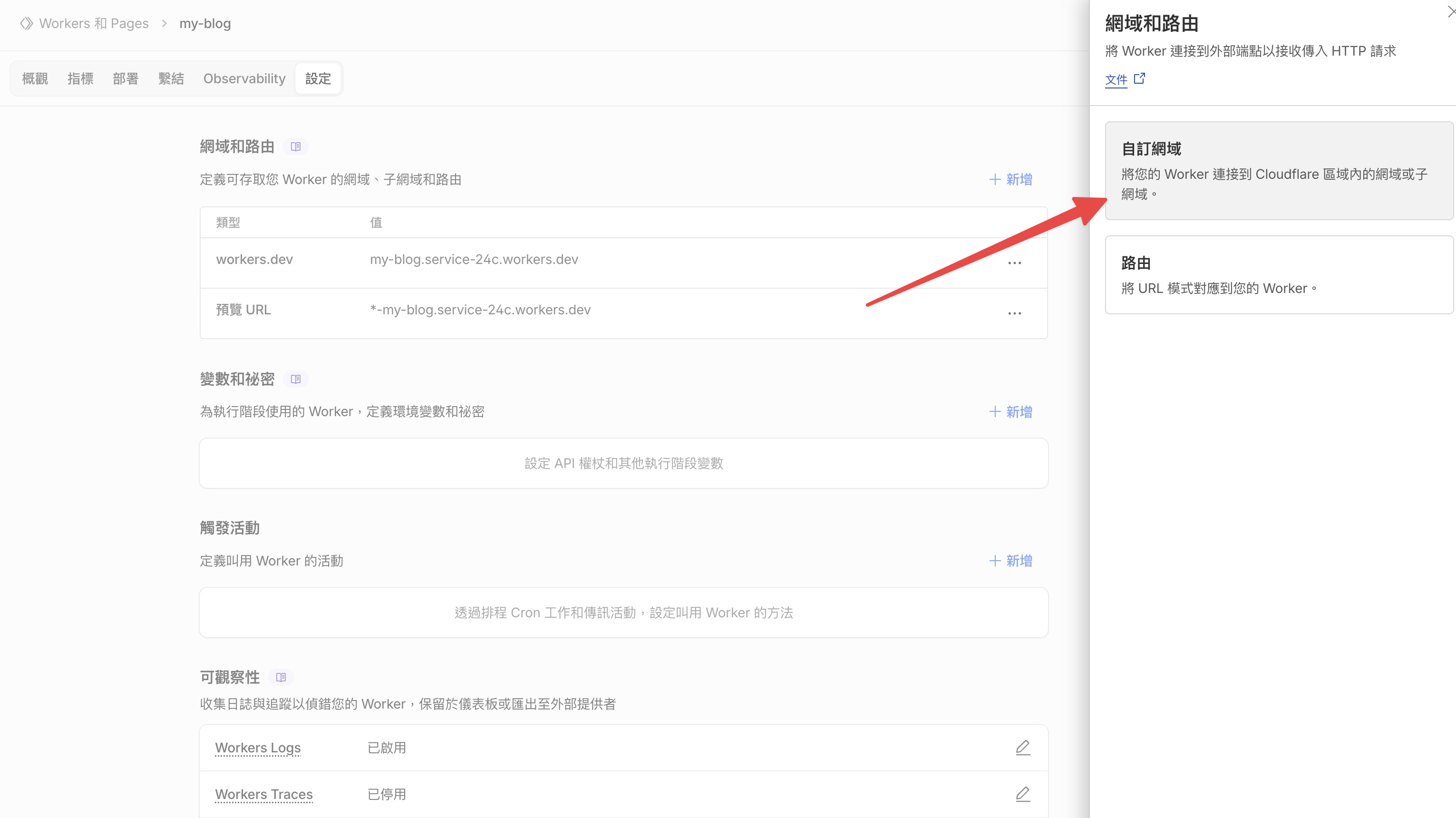
輸入你剛才買的網域名稱,點新增網域。
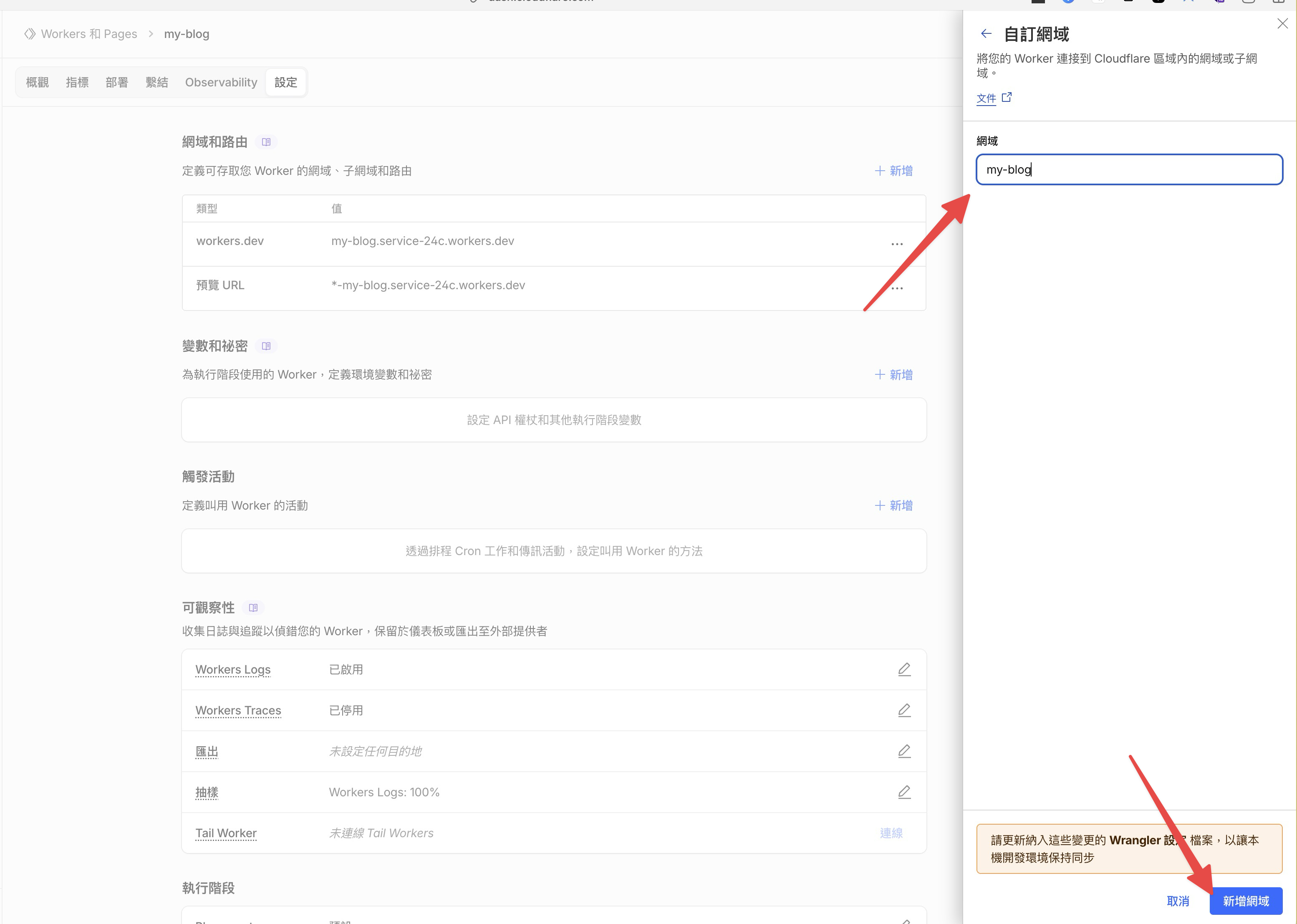
因為網域是在 Cloudflare 買的,DNS 設定會自動完成,不需要額外操作。等幾分鐘讓 DNS 生效,之後用你的專屬網域就能打開部落格了。
到目前為止你完成了什麼?
讓我們回顧一下整個系列。從第一篇的概念介紹到現在,你已經:
- 搞懂 Astro、Git、Cloudflare 的角色
- 用 Claude Code 安裝了 Astro,建好部落格專案
- 改了網站名稱、調了選單、新增了文章
- 用 Git 做了存檔,推到 GitHub
- 把網站部署到 Cloudflare Workers,全世界都能看到
- 知道怎麼更新文章並自動部署
整個過程,你沒有手動輸入任何部署指令。每一步都是跟 Claude Code 說話,然後看它幫你搞定。
你現在有了一個真正的網站——免費架設、免費託管、全球都能快速存取、更新文章全自動。這就是用 AI 架設網站的力量。
接下來的路就是你的了。寫你想寫的東西,用你的部落格記錄任何你覺得值得分享的事情。如果你想讓 Claude Code 幫你更有系統地寫文章——從關鍵字研究到文章結構一條龍搞定——可以看看我們整理的用 Skill 打造 AI 寫作流程。
下一篇,我們會處理另一個重要的事:讓搜尋引擎找到你的部落格。我們會設定 Astro 的 SEO 相關功能(meta 標籤、sitemap、Open Graph),然後串接 Google Analytics 和 Search Console,讓你知道有多少人在看你的文章、他們是從哪裡來的。網站上線只是開始,被人看到才是重點。
常見問題
部署的時候失敗了怎麼辦?
最常見的原因是 Node.js 版本不對。Cloudflare 建構環境的 Node.js 版本可能跟你本機的不同,跟 Claude Code 說「部署失敗了,幫我看看是什麼問題」,把錯誤訊息貼給它,它通常能直接判斷原因並幫你修好。
Cloudflare Workers 免費方案有什麼限制?
每次你推更新到 GitHub,Cloudflare 就會重新產生一次網站,免費方案每天最多 1,000 次。就算你每天更新十篇文章也用不完。流量和頻寬沒有限制,對個人部落格來說綽綽有餘。
自訂網域要花錢嗎?
要。網域本身需要購買,一年大概 300-500 台幣。但「把網域指向 Cloudflare Workers」這個動作是免費的。如果你還不確定要不要投入,先用 Cloudflare 提供的免費 workers.dev 網址就好,功能完全一樣。
Cloudflare Workers 跟 Cloudflare Pages 有什麼不同?
Cloudflare Pages 是早期專門用來託管靜態網站的服務,功能比較單純,只能放靜態檔案。後來 Cloudflare 把 Pages 和 Workers 合併在一起了——現在建立新專案走的都是 Workers 的流程。簡單來說,Workers 能做到 Pages 做的所有事情,還額外支援後端程式。對部落格來說,你不需要在意這個差異,只要知道 Workers 就是現在的統一平台就好。
可以同時有多個網站嗎?
可以。Cloudflare 免費帳號可以建立多個 Workers 專案,每個專案都有自己的 workers.dev 網址。你可以一個做部落格、一個做作品集,完全不用額外付費。
Claude Code x 部落格架設(四):部落格 SEO 設定與流量追蹤
第 10 篇,共 21 篇
上一篇我們把部落格部署到 Cloudflare Workers,全世界都能打開你的網址了。但「能打開」跟「有人會打開」是兩件事。
你的部落格現在就像一間開在巷子裡的店——裝潢好了、門也開了,但沒有招牌、沒有地圖標記,路過的人根本不知道你在這裡。這篇要做的事,就是幫你掛上招牌、登記到 Google 地圖上,然後裝一個計數器,讓你知道到底有沒有人來過。
具體來說,我們會完成三件事:
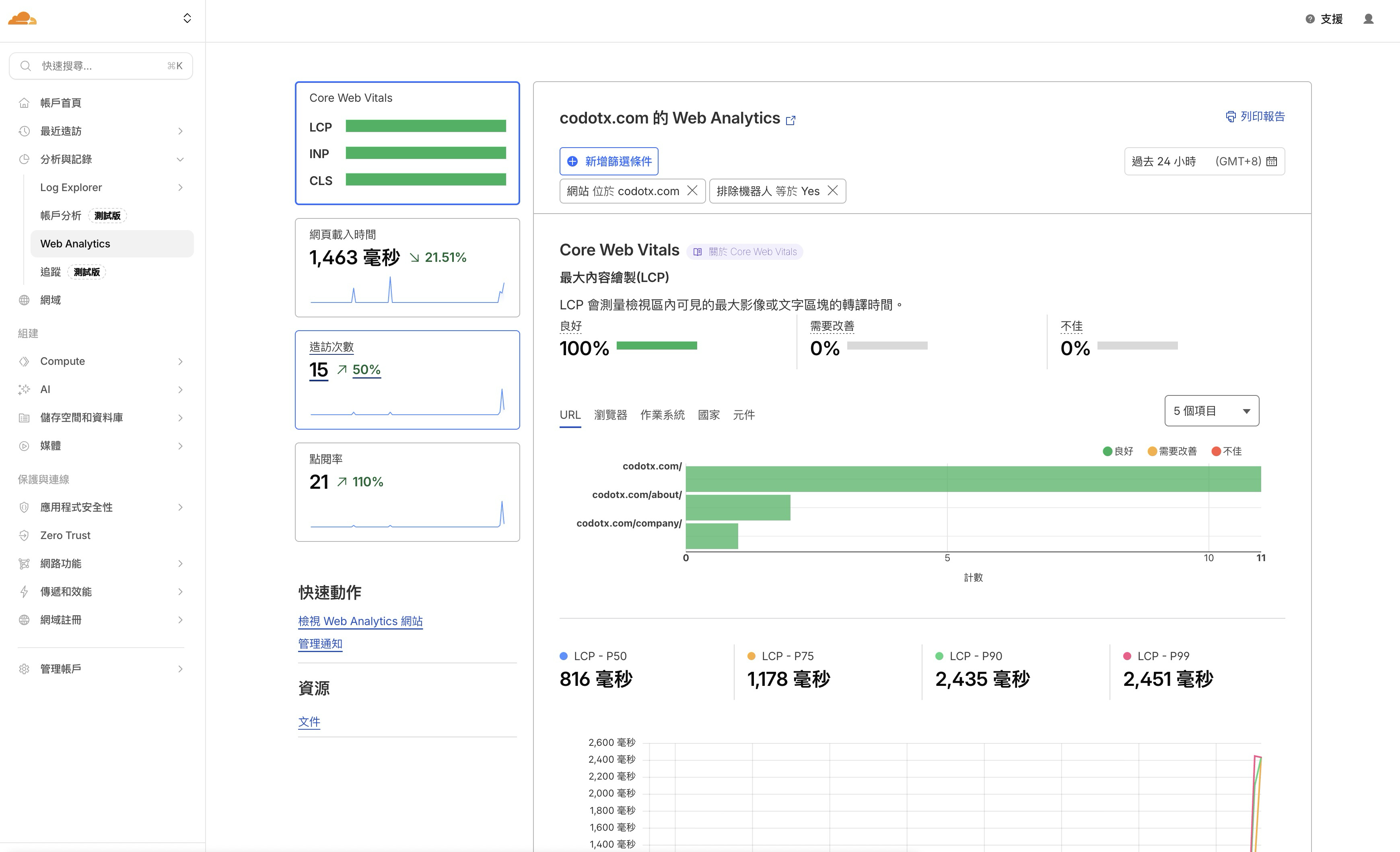
- SEO 基本設定 — 讓搜尋引擎看懂你的網站內容(meta 標籤、sitemap、Open Graph 等)
- Cloudflare Web Analytics — 知道有多少人來、從哪裡來
- Google Search Console — 知道搜尋引擎怎麼看你的網站
整個過程大概三十分鐘,一樣全部交給 Claude Code 處理。
搜尋引擎怎麼「看」你的網站?
在動手設定之前,花一分鐘搞懂搜尋引擎的運作方式,後面的步驟會更有感覺。
Google 會派出一個叫「爬蟲」的程式,像一隻到處爬的蜘蛛,順著網路上的連結從一個頁面爬到另一個頁面。它爬到你的部落格之後,會做兩件事:
第一,讀懂你的內容。 它看的不只是文章本文,還會看你在 HTML 裡留下的「標籤」。這些標籤告訴 Google:這頁的標題是什麼、描述是什麼、配圖是什麼。標籤寫得好,Google 就能正確理解你的內容,搜尋結果上顯示的資訊也會更吸引人。
第二,決定排名。 Google 會根據內容品質、網站速度、連結數量等因素,決定你的文章在搜尋結果裡排第幾位。好消息是,Astro 產出的網站先天速度就快——第一篇提過,Astro 產出的頁面非常輕量,這在 Google 的速度評分裡是加分項。
我們現在要做的,就是把那些「標籤」設定好,再給 Google 一份網站的完整目錄,讓它不用瞎摸就能找到你所有的頁面。
Meta 標籤:你在搜尋結果上的門面
你在 Google 搜尋的時候,每一筆結果都會顯示三樣東西:標題、網址、一段描述文字。
那段描述文字不是 Google 自己寫的——是你在 HTML 裡用 meta 標籤告訴它的。
如果你沒有設定 meta 標籤,Google 會自己從頁面內容裡抓一段文字來當描述。結果通常不太好看,可能是文章開頭的半句話,也可能是導覽列上的選單文字。設定好 meta 標籤,你就能控制搜尋結果上顯示的每一個字。
標題標籤和描述標籤
最重要的兩個 meta 標籤:
- Title 標籤:顯示在搜尋結果最上面那行藍色文字,也是瀏覽器分頁上顯示的名稱。好的標題要清楚說明這一頁在講什麼,長度建議控制在 30 個中文字以內,超過的部分會被 Google 截掉
- Description 標籤:顯示在標題下方的灰色描述文字。好的描述要讓搜尋的人一眼知道這篇文章值不值得點進來,長度建議 50-75 個中文字
跟 Claude Code 說:
幫我設定部落格的 SEO meta 標籤,包括每一頁的 title 和 description。
文章頁面用文章的標題和描述,首頁用網站名稱和網站描述。Claude Code 會去改你的 layout 檔案(還記得第二篇提到的「餐廳裝潢」嗎?),在 HTML 的 <head> 區塊裡加上這些標籤。
你寫文章的時候其實就在設定 meta 標籤
這裡有一個重要的觀念:設定完之後,你以後寫文章不需要再去動任何程式碼。
還記得第二篇提過,每篇文章開頭都有一個「基本資料卡」(frontmatter)嗎?
---
title: "我用 Claude Code 架了一個部落格"
description: "完全不懂程式,從零開始的架站紀錄"
pubDate: 2026-04-17
---Claude Code 設定好 meta 標籤之後,Astro 會自動把 frontmatter 裡的 title 變成標題標籤,description 變成描述標籤。你每次寫新文章,只要把這兩個欄位填好,那篇文章在 Google 搜尋結果上的門面就自動搞定了。
所以「設定 SEO」不只是一次性的技術操作。之後每一篇文章的 title 和 description 都值得花幾秒鐘想一下——這是讀者在 Google 上看到你的第一印象。
怎麼確認有設定成功?
在瀏覽器裡打開你的部落格,在頁面上按右鍵,選「檢視原始碼」。你會看到一大堆 HTML,不用看懂全部,只要搜尋 <meta name="description",找到一行長這樣的東西:
<meta name="description" content="你設定的描述文字">有的話就代表設定成功了。每一頁都檢查一下,確認首頁和文章頁面顯示的描述不一樣——如果每一頁的描述都一模一樣,等於沒設定。
Canonical URL:告訴 Google 哪個才是「正版」
這個名詞聽起來很嚇人,但概念很簡單。
有時候同一篇文章可能會出現在不同的網址上。最常見的情況是多語系網站——假設你的部落格有中文和英文版,同一篇文章可能同時存在 https://my-blog.com/first-post 和 https://my-blog.com/en/first-post。或者更單純的情況:你的網址有沒有結尾斜線(/first-post vs /first-post/)都能存取同一頁,Cloudflare 的預覽網址上也看得到同樣的內容。
Google 的爬蟲看到這些不同的網址指向相似的內容,會困惑:「到底哪一個才是正版?」如果它猜錯了,搜尋排名的分數就會分散到好幾個網址上,反而降低你的排名。
Canonical URL 就是你在 HTML 裡放一個標籤,告訴 Google:「不管你從哪個網址看到這個頁面,正版在這裡。」對多語系網站來說,中文版的 canonical 指向中文網址,英文版的指向英文網址,Google 就不會把兩個語言版本搞混。
跟 Claude Code 說:
幫我在每一頁加上 canonical URL 標籤,指向該頁面的標準網址Claude Code 會在 layout 的 <head> 裡加上一行 <link rel="canonical">。設定完之後你不需要再管它,Astro 會自動幫每一頁產生正確的 canonical URL。
Robots.txt:跟爬蟲說規矩
如果 sitemap 是「請看這份目錄」,robots.txt 就是「請遵守這些規矩」。
Robots.txt 是一個放在網站根目錄的小檔案,告訴搜尋引擎的爬蟲:哪些頁面可以爬、哪些不要來。對部落格來說,大部分頁面都歡迎爬蟲來訪。但有些頁面不需要被搜尋到——比如標籤頁、分頁的第 2、3、4 頁,這些頁面內容重複度高,讓 Google 收錄反而會稀釋你的搜尋排名。
跟 Claude Code 說:
幫我建立 robots.txt,允許所有搜尋引擎爬取,並且在裡面指向 sitemap 的位置Claude Code 會在 public/ 資料夾裡建一個 robots.txt 檔案。內容很短,通常就幾行:
User-agent: *
Allow: /
Sitemap: https://你的網址/sitemap-index.xml第一行說「對所有爬蟲」,第二行說「所有頁面都可以爬」,第三行說「sitemap 在這裡」。就這麼簡單。
Sitemap:給搜尋引擎的網站地圖
剛才 robots.txt 裡提到了 sitemap,現在來把它裝上。
Sitemap 是你網站的完整目錄,用 XML 格式列出所有頁面的網址和最後更新時間。沒有 sitemap,Google 的爬蟲得自己順著連結一頁一頁去找,可能會漏掉你的某些文章。有了 sitemap,等於你直接遞了一份清單給它:「這是我所有的頁面,請全部收錄。」
Astro 有官方的 sitemap 套件,安裝只要一句話。跟 Claude Code 說:
幫我安裝 Astro 的 sitemap 套件,設定好讓它自動產生 sitemapClaude Code 會幫你安裝 @astrojs/sitemap,然後在 astro.config.mjs(那個「餐廳營業登記」)裡加上設定。這裡有一個重要的細節:Claude Code 會確認 astro.config.mjs 裡面有設定你的網站網址。Sitemap 需要知道你的完整網址才能正確產生,如果設定檔裡的 site 欄位是空的或還是預設值,sitemap 產出的連結就會是錯的。
完成之後,每次你部署網站,Astro 就會自動產生一個 sitemap.xml,列出所有頁面的網址。
你可以在瀏覽器裡打開 你的網址/sitemap-index.xml 確認。看到的會是一個 XML 格式的頁面,裡面有一個指向 sitemap-0.xml 的連結:
你可能會想:「怎麼只有一個連結,我的文章清單呢?」別擔心,這是 Astro 的 sitemap 結構——它會先產生一個索引檔(sitemap-index.xml),再把實際的網址清單放在另一個檔案裡。點進 sitemap-0.xml,就能看到你所有頁面的完整網址列表:
為什麼要分兩層?因為 sitemap 規範規定單一檔案最多只能放 50,000 筆網址。Astro 預設就用索引檔的格式,萬一你的部落格以後文章多到超過上限,它會自動拆成 sitemap-0.xml、sitemap-1.xml⋯⋯不用你操心。
後面我們串接 Google Search Console 的時候,提交的是索引檔的網址(sitemap-index.xml),Google 會自動順著找到裡面所有的子 sitemap。
Open Graph:社群分享的門面
你有沒有注意過,在 LINE 或 Facebook 分享一個網址的時候,有些連結會自動顯示一張大圖、標題和描述,有些只顯示一個光禿禿的網址?
差別就在 Open Graph 標籤。
Open Graph 是 Facebook 發明的一套標準,現在幾乎所有社群平台都支援——LINE、X(Twitter)、LinkedIn 都會讀取這些標籤。你在 HTML 裡放上 og:title、og:description、og:image 這些標籤,社群平台就會用這些資訊來產生分享預覽卡片。
跟 Claude Code 說:
幫我設定 Open Graph 標籤,讓部落格文章在 LINE 和 Facebook 分享時能顯示標題、描述和配圖Claude Code 會在 layout 裡加上 Open Graph 的 meta 標籤。跟前面的 meta 標籤一樣,文章頁面會自動從 frontmatter 裡讀取標題和描述,不需要你每次手動設定。
如果你的文章有配圖,也會自動帶上去。沒有配圖的話,建議準備一張通用的預設圖(比如你的部落格 logo 加上背景色),當作沒有特定配圖時的替代。尺寸建議 1200 x 630 像素,這是各平台通用的最佳比例。
怎麼測試分享預覽?
設定好之後,你可以用 Facebook 的 Sharing Debugger 來測試。把你的文章網址貼進去,它會顯示分享時的預覽效果。如果沒有圖片或標題不對,就回頭跟 Claude Code 調整。
LINE 的分享預覽沒有官方測試工具,最簡單的方法就是把網址丟到 LINE 聊天室裡看看預覽長什麼樣子。第一次可能沒有預覽(LINE 會快取舊的結果),等幾分鐘再試一次通常就會出現。
結構化資料:讓 Google 「看懂」你是誰
前面的 meta 標籤告訴 Google 每一頁的標題和描述。結構化資料(Structured Data)做的事情更進一步——它用一種 Google 看得懂的格式,告訴搜尋引擎你的網站「是什麼」、文章「是什麼」。
聽起來很抽象,用一個例子說明。你在 Google 搜尋食譜的時候,有些結果會直接顯示烹飪時間、評分星星、卡路里。搜尋一個人的名字,右邊可能出現一張資訊卡片,列出他的職業、公司、社群連結。這些額外的資訊就是結構化資料的效果——Google 讀到之後,會用更豐富的格式呈現你的搜尋結果。
對部落格來說,最實用的結構化資料有兩種:
網站資訊(WebSite Schema):告訴 Google 你的網站名稱和網址。這會影響 Google 搜尋結果上顯示的網站名稱——沒有設定的話,Google 會自己猜,有時候猜得不太對。
文章資訊(Article Schema):告訴 Google 每篇文章的作者、發布日期、修改日期。這些資訊有機會讓你的文章在搜尋結果上顯示發布日期,讀者看到日期是近期的,會更願意點進來。
跟 Claude Code 說:
幫我加上結構化資料:
1. 網站層級的 WebSite Schema,包含網站名稱和網址
2. 每篇文章加上 Article Schema,包含作者、發布日期
用 JSON-LD 格式放在 HTML 的 head 裡面Claude Code 會在 layout 裡加上一段 <script type="application/ld+json"> 標籤。你不需要看懂裡面的 JSON,只要知道它在那裡就好。跟 meta 標籤一樣,文章的結構化資料會自動從 frontmatter 讀取日期和標題。
怎麼確認結構化資料正確?
Google 提供了一個免費的 Rich Results Test 工具。把你的文章網址貼進去,它會告訴你 Google 讀到了哪些結構化資料、有沒有格式錯誤。綠色勾勾代表正確,紅色警告代表需要修正——把錯誤訊息貼給 Claude Code 就好。
設定結構化資料不保證 Google 一定會顯示那些額外資訊(Google 有自己的判斷標準),但設定好等於給了 Google 選擇的機會。沒設定,機會就是零。
圖片的 alt text:容易忽略但很重要
這個設定跟前面不太一樣——不是一次設定好就不用管的,而是每次你在文章裡放圖片的時候都要注意。
當你用 Markdown 語法插入一張圖片:
方括號裡的那段文字就是「alt text」(替代文字)。它的用途有兩個:
第一,讓看不到圖片的人知道圖片的內容。 視障讀者使用螢幕閱讀器瀏覽你的網站時,螢幕閱讀器會把 alt text 念出來。圖片載入失敗的時候,瀏覽器也會顯示 alt text。
第二,讓 Google 理解圖片的內容。 Google 的爬蟲看不懂圖片,它靠 alt text 來判斷這張圖在講什麼。寫好 alt text,你的圖片有機會出現在 Google 圖片搜尋裡,帶來額外的流量。
好的 alt text 要具體描述圖片的內容,而不是寫「圖片」或「截圖」。「Cloudflare Dashboard 的部署狀態頁面」比「截圖」好太多。
這不是什麼需要跟 Claude Code 設定的東西,但值得養成習慣。每次在文章裡加圖片的時候,花五秒鐘寫一段具體的描述。
全部一次搞定
如果你不想分好幾次跟 Claude Code 溝通,其實可以一句話把前面的設定全部搞定:
幫我設定完整的 SEO:
1. 每一頁都要有 meta title 和 description,從文章的 frontmatter 讀取
2. 每一頁加上 canonical URL
3. 建立 robots.txt,允許所有爬蟲,指向 sitemap
4. 安裝 Astro 的 sitemap 套件,確認 astro.config.mjs 裡的 site 網址正確
5. 設定 Open Graph 標籤,讓社群分享有預覽圖
6. 加上結構化資料:網站的 WebSite Schema,文章的 Article Schema,用 JSON-LD 格式Claude Code 會一次處理完所有設定。跑完之後,用開發伺服器確認一下:打開頁面原始碼看 meta 標籤和 OG 標籤有沒有出現,再打開 /sitemap-index.xml 和 /robots.txt 確認內容正確。都沒問題就可以推到 GitHub,讓 Cloudflare 自動部署。
到這裡,你的部落格對搜尋引擎和社群平台來說已經是一個「準備好了」的網站。接下來要處理的是:怎麼知道有沒有人來?
Cloudflare Web Analytics:你的訪客計數器
網站上線之後,最讓人好奇的問題大概是「到底有沒有人在看?」
好消息是,你的部落格已經部署在 Cloudflare Workers 上了,Cloudflare 本身就有內建的流量分析工具——Web Analytics。不需要額外安裝追蹤碼、不需要註冊新帳號,在 Dashboard 上點幾下就能開啟。
開啟 Web Analytics
登入 Cloudflare Dashboard,點左側選單的 Web Analytics,選擇你的網站,點「啟用」就完成了。
沒有了。就這麼簡單。
不需要在部落格裡加任何程式碼,不需要推到 GitHub 重新部署。Cloudflare 會自動開始收集你的網站流量資料。
看懂基本數據
開啟之後等幾個小時讓資料累積,再回到 Web Analytics 頁面,你會看到幾個重要的數字:
造訪次數(Visits) — 有多少人造訪過你的網站。
頁面瀏覽數(Page Views) — 總共被看了幾頁。一個人看了三篇文章就算三次。
熱門頁面(Top Pages) — 哪幾篇文章最多人看。這個數據很實用,它會告訴你讀者對什麼主題有興趣。
流量來源(Top Sources) — 訪客是從哪裡來的。常見的來源有:
- Google / Bing:從搜尋引擎來的(這是 SEO 的成效指標)
- Direct:直接在瀏覽器輸入網址
- t.co / threads.net:從社群平台來的
- 其他網站名稱:從別人的網站連結過來的
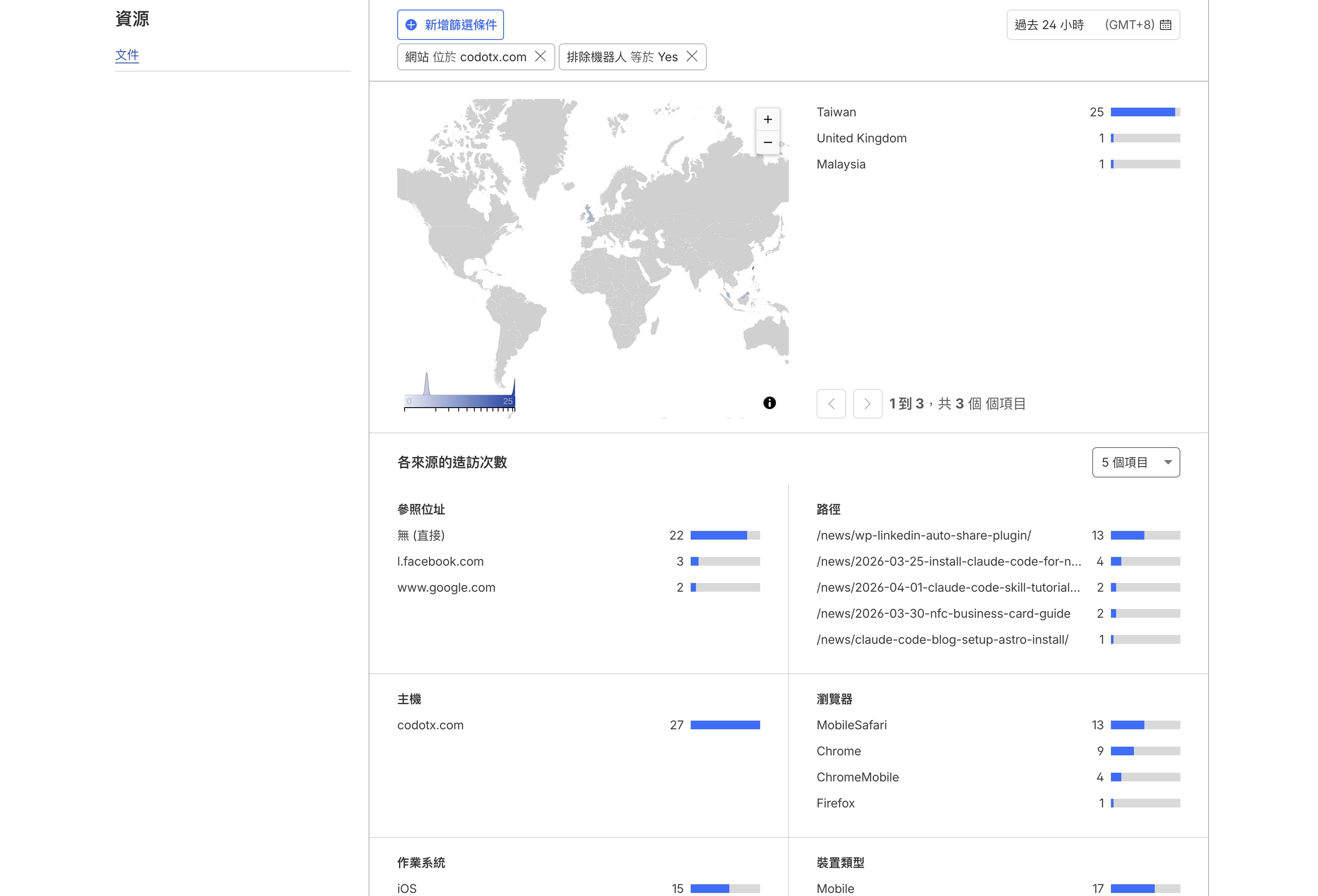
Core Web Vitals — 這是 Cloudflare Web Analytics 比較特別的功能,它會顯示你的網站在真實使用者裝置上的載入速度評分。Google 把這個速度當作搜尋排名的參考指標之一,所以值得偶爾看一眼。用 Astro 架的網站通常分數都不錯。
剛上線的部落格,數字小是正常的。不需要每天盯著報表看,一週看一次,觀察趨勢就好。重點是那條線有沒有慢慢往上走。
需要更細緻的分析再用 Google Analytics
Cloudflare Web Analytics 的優點是零設定、不需要 cookie、對讀者隱私友善。對大部分個人部落格來說夠用了。
如果之後你的部落格流量起來了,需要更細緻的數據——比如讀者在每篇文章上停留多久、從哪一段開始跳出、轉化率追蹤——那時候再考慮加裝 Google Analytics(GA4)。跟 Claude Code 說「幫我安裝 Google Analytics」,它會幫你在 layout 裡加上追蹤碼,十分鐘就搞定。兩套工具可以並存,不會衝突。
我們之前寫過一篇用 Claude Code 串接 Cloudflare Web Analytics API,甚至能讓 Claude Code 直接幫你查流量數據,不用打開瀏覽器,問一句話就知道這週有多少人看過你的文章。
Google Search Console:搜尋引擎怎麼看你
GA4 告訴你「有沒有人來」,Google Search Console(簡稱 GSC)告訴你「搜尋引擎怎麼看你的網站」。兩個工具的角色不同:
- GA4:記錄訪客的行為(來了幾個人、看了什麼、待多久)
- GSC:記錄搜尋引擎的行為(你的網站在搜尋結果裡出現幾次、排第幾名、有沒有技術問題)
驗證網站擁有權
到 Google Search Console 登入,點「新增資源」,選「網址前置字元」,輸入你的網站網址。
Google 會要求你驗證這個網站是你的。最簡單的方式是選「HTML 標記」驗證——它會給你一段 meta 標籤,長得像這樣:
<meta name="google-site-verification" content="一串亂碼">複製這段標籤,跟 Claude Code 說:
幫我在部落格的 HTML head 裡加上這段 Google 驗證碼:
<meta name="google-site-verification" content="你的驗證碼">推到 GitHub,等 Cloudflare 部署完成之後,回到 Search Console 點「驗證」。通過之後,Google 就知道這個網站是你的了。
提交 Sitemap
驗證完成後,點左邊選單的「Sitemap」,在「新增 Sitemap」的欄位裡填入:
你的網址/sitemap-index.xml按下提交。
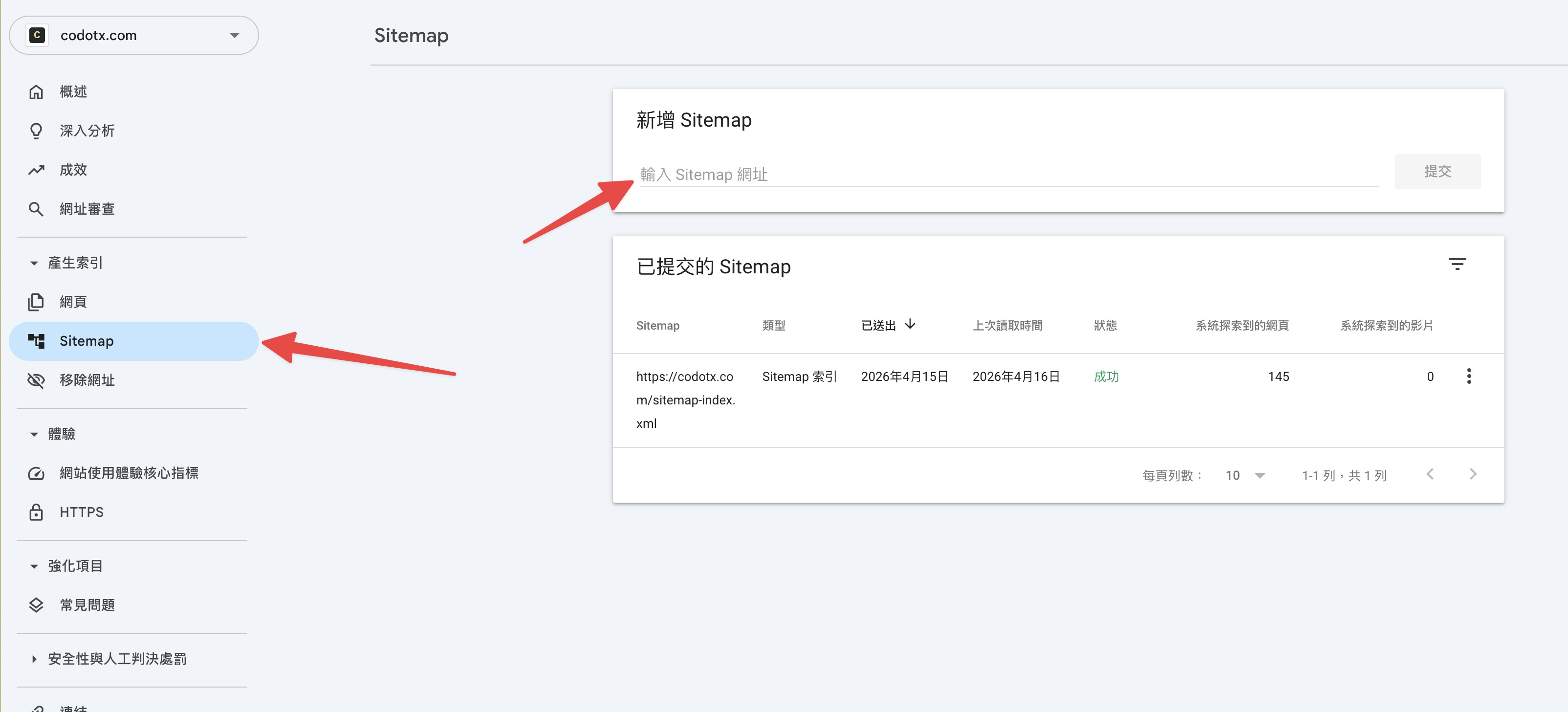
提交成功後,你會在「已提交的 Sitemap」看到狀態顯示「成功」,還有 Google 探索到的網頁數量。這就是我們前面設定 sitemap 的回報——一份現成的目錄,直接交給 Google。
看懂 GSC 的基本數據
提交 sitemap 之後,需要等幾天讓 Google 收錄你的頁面。之後打開 Search Console,你最常看的會是「成效」報表,裡面有四個關鍵數字:
曝光次數 — 你的網站出現在搜尋結果裡的次數。就算沒有人點,只要出現了就算一次曝光。
點擊次數 — 有多少人實際從搜尋結果點進你的網站。
平均排名 — 你的文章在搜尋結果裡平均排在第幾位。
點閱率(CTR) — 點擊次數 ÷ 曝光次數。如果你的文章出現了 100 次但只有 2 個人點,CTR 就是 2%。
剛開始這些數字都會很低,甚至是零。一個新網站要被 Google 收錄,通常需要幾天到幾週的時間,這是正常的。重要的是你已經把門打開了——Google 知道你在這裡,只是需要時間來認識你。
GSC 還有一個很有用的功能:「涵蓋範圍」報表。它會告訴你 Google 成功收錄了幾頁、有沒有哪些頁面出了問題。如果看到紅色的錯誤,把錯誤訊息貼給 Claude Code,它通常能幫你判斷問題出在哪裡。
到目前為止你完成了什麼?
讓我們回顧一下整個系列。從第一篇的概念介紹到現在,你已經:
- 搞懂 Astro、Git、Cloudflare 的角色
- 用 Claude Code 安裝了 Astro,建好部落格專案
- 把網站部署到 Cloudflare Workers,全世界都能看到
- 設定了 SEO 的 meta 標籤、sitemap、Open Graph
- 開啟了 Cloudflare Web Analytics,能追蹤訪客數據
- 串接了 Search Console,能看到搜尋引擎的收錄狀況
你現在有的不只是一個網站,而是一個「能被找到、能被追蹤」的網站。搜尋引擎知道你在這裡,社群分享有漂亮的預覽,你也能隨時查看有多少人在看你寫的東西。
接下來就是持續寫。SEO 不是設定完就結束的事——Google 看的是你有沒有持續產出有價值的內容。每多一篇文章,就多一個被搜尋到的機會。你只要專注在寫好每一篇文章,其他的交給你已經設定好的這些工具。
常見問題
部落格 SEO 設定完之後多久會有效果?
Google 收錄一個新網站通常需要幾天到幾週。收錄之後,文章要累積到一定的數量和品質,搜尋排名才會慢慢上升。大部分部落格在持續更新三到六個月後會開始看到明顯的搜尋流量。SEO 是長期的事,不會今天設定明天就有排名。
Sitemap 需要每次手動更新嗎?
不需要。我們安裝的 @astrojs/sitemap 套件會在每次部署時自動產生最新的 sitemap。你新增一篇文章,推到 GitHub,Cloudflare 自動部署之後,sitemap 裡就會包含新文章的網址。Google 會定期來檢查你的 sitemap,自動發現新頁面。
Cloudflare Web Analytics 和 Search Console 有什麼差別?
Web Analytics 看的是「訪客在你的網站上做了什麼」——有幾個人來、看了哪些頁面、從哪裡來。Search Console 看的是「你的網站在搜尋引擎裡的表現」——出現在搜尋結果幾次、排名第幾、有沒有被正確收錄。兩個工具角度不同,建議都開。
Open Graph 圖片有什麼建議的尺寸?
Facebook 和 LINE 建議的 OG 圖片尺寸是 1200 x 630 像素,比例大約是 1.91:1。如果你的文章沒有配圖,可以準備一張通用的預設圖片(例如你的部落格 logo 加上背景色),跟 Claude Code 說「幫我設定一張預設的 OG 圖片」,它會幫你處理。
Claude Code x 部落格架設(五):用 Skills 打造 SEO 自動健檢
第 11 篇,共 21 篇上一篇我們把 SEO 的基本功做完了——meta 標籤、sitemap、Open Graph、Cloudflare Web Analytics、Google Search Console,全部設定到位。理論上,Google 應該知道你在這裡了。
經營了一陣子之後,發現都沒有什麼人來造訪嗎?於是我們設計了一個 Skills 來幫你檢查這些問題。
這篇會帶你走過我們協助客戶時遇到的真實情境:明明 SEO 都設定好了,搜尋自己的關鍵字卻完全找不到自己的網站。然後一步步診斷,找出問題、修正問題,最後把整個檢查流程包裝成一個 Claude Code Skill,讓以後只要打一句話就能跑完全套健檢。
搜尋自己的關鍵字,結果找不到自己
這種情況比你想像中常見。部落格寫了十幾篇文章,打開 Google 搜尋自己主攻的關鍵字,翻了三頁——沒有你,換個關鍵字再試,翻了五頁——還是沒有。
明明文章都有被 Google 收錄(用 site:你的網址 搜尋確認過),Search Console 也提交了 sitemap,但就是搜不到。
問題出在哪裡?
用數據說話:常見的四個 SEO 地雷
光猜不夠,你可以請 Claude Code 幫忙做一次全面診斷。用 Google Search Console 的數據(我們在上一篇已經串接好了),再搭配 DataforSEO 之類的 SEO 分析工具,通常會發現以下這些問題。
地雷一:首頁標題太短
還記得上一篇講的 title 標籤嗎?很多人設定的時候只填了網站名稱,比如「My Blog」三個字。Google 看到這個標題,完全不知道這個網站在做什麼——它不會通靈,你得明確告訴它。
好的首頁 title 要包含你的核心主題和關鍵字,長度建議 30 到 60 字元。比如:
不好: My Blog
好: My Blog | Claude Code 教學 · Astro 架站 · 前端開發筆記
差別在於後者直接告訴 Google 和搜尋者,這個網站在講什麼。
地雷二:文章描述只是複製標題
上一篇我們特別強調了 meta description 的重要性,但實際檢查的時候,很多部落格的 description 就是把標題再寫一次,等於在 Google 搜尋結果上,標題和描述講的是同一句話。
比如一篇叫「第一次安裝 Claude Code 就上手」的文章,description 也是「第一次安裝 Claude Code 就上手」。搜尋者看到這種結果,完全不知道點進去會看到什麼內容,自然不會想點。
另一個常見的陷阱是 Astro 的 frontmatter 欄位名稱寫錯——寫了 metaDescription 但 Astro 的 schema 定義是 description,結果系統根本沒讀到,等於白寫。
地雷三:頁面內容太薄
SEO 分析工具會檢查一個叫「content rate」的指標——頁面上純文字佔整體 HTML 的比例。如果你的首頁只有幾十個字的純文字,content rate 低於 1%,Google 會直接判定為「低品質頁面」,不值得排名。
最容易中招的是首頁和各種「封面頁」——這些頁面通常以視覺設計為主,文字內容很少。解法是加上一段摘要文字,讓 Google 有足夠的內容可以索引。
地雷四:被轉載的文章搶走了你的排名
如果你的文章被其他網站全文轉載,Google 遇到兩個網站有一模一樣的內容時,會選擇權重比較高的那個當「正本」。對方的網域權重如果遠高於你,Google 就會把他們的版本當正本,你的原文反而被壓下去。
這不是 SEO 設定能解決的問題,但值得知道——如果未來有人要轉載你的文章,記得請他們加上 <link rel="canonical"> 指回你的原文網址,告訴 Google 誰才是原作者。
檢查完一輪之後的問題
假設你用 Claude Code 跑完一次診斷,花了一兩個小時把問題修完——改首頁 title、補上缺少的 description、在內容太薄的頁面加上摘要段落。
然後呢?這些檢查項目,下次還得再做一遍嗎?
每次寫完新文章,都要手動去確認 description 有沒有寫、title 長度夠不夠、Google 有沒有正確收錄。這些事情每一件都不難,但全部加起來就是一個繁瑣的清單,更麻煩的是,你不會記得每次都要檢查。
於是我們想:能不能把這整套檢查流程包裝起來,以後一句話就能跑完?
Skills 是什麼?
如果你有跟著這個系列一路做下來,你已經跟 Claude Code 說過很多次話了——「幫我設定 meta 標籤」「幫我安裝 sitemap 套件」「幫我加上 Open Graph」,每一次,你都要從頭解釋你要做什麼。
Skill 就是把這些指令打包成一個可以重複使用的「技能包」。
延續這個系列的比喻:你的部落格是一間店,前幾篇我們蓋好了店面、掛上了招牌、裝了計數器。但每次要「巡店」的時候——招牌還在嗎、門口有沒有東西擋住、燈有沒有亮——你都要自己列一張清單,從頭檢查一遍。Skill 就是那張寫好的巡店清單,你把所有該檢查的項目寫成一份文件,以後只要說一句「巡店」,Claude Code 就會照著清單一項一項幫你跑完。
技術上來說,一個 Skill 就是一個 Markdown 檔案,裡面寫著:
- 什麼時候要啟動——觸發條件的描述
- 要做什麼事——具體的步驟和指令
- 怎麼呈現結果——輸出的格式
放在正確的位置之後,你就可以用 /skill名稱 的方式呼叫它,或者在對話中描述你的需求,Claude Code 會自動判斷要不要啟用這個 Skill。
Skill 放在哪裡?
Skill 檔案的存放位置有兩種:
專案層級——放在你的部落格專案裡,只有在這個專案中才能用:
你的專案/.claude/skills/skill名稱/skill.md全域層級——放在你的使用者目錄,任何專案都能用:
~/.claude/skills/skill名稱/skill.mdSEO 健檢這種工具,不管在哪個專案都可能用到,所以我們放在全域層級。
設計 SEO 健檢 Skill
知道了 Skill 的概念之後,接下來是設計我們的 SEO 健檢 Skill。
在手動診斷的過程中,我們發現有效的 SEO 檢查需要從三個不同的角度來看:
- 搜尋引擎怎麼看你——Google Search Console 的數據
- 訪客的實際行為——Cloudflare Web Analytics 的流量數據
- 頁面本身的體質——On-page SEO 分析
這三個資料來源各自回答不同的問題,合在一起才能看到全貌。如果繼續用店面的比喻:第一個是站在馬路上看有多少人經過你的店門口(搜尋曝光),第二個是進到店裡數人頭、看他們走了哪些動線(流量),第三個是檢查你的招牌夠不夠大、櫥窗有沒有擺東西、門口有沒有障礙物(頁面體質)。只看其中一個,你會漏掉真正的問題。
Skill 的五步流程
根據手動診斷的經驗,我們把整個健檢流程拆成五個步驟:
第一步:看 Google 怎麼說(Search Console 數據)
從 Google Search Console 拉出最近一週的搜尋數據:哪些關鍵字帶來了曝光、有多少人點擊、平均排名在第幾位,這一步回答的問題是:「Google 到底有沒有在推薦你的文章?」
如果曝光數不錯但點擊率很低,通常代表你的標題和描述不夠吸引人,如果連曝光都沒有,代表 Google 根本沒把你的文章排進搜尋結果。
第二步:看訪客怎麼來(Cloudflare Web Analytics)
拉出最近七天的流量數據:每天多少人來、最多人看的是哪幾頁、訪客從哪裡來(Google 搜尋、社群連結、還是直接輸入網址),這一步回答的問題是:「有人來嗎?他們怎麼找到你的?」
如果大部分流量都來自「Direct」(直接輸入網址),代表你的 SEO 還沒有起效果,來的都是已經知道你的人。
第三步:檢查每一頁的體質(On-Page 分析)
對首頁、重要頁面和最新幾篇文章做逐頁檢查:title 長度夠不夠、description 有沒有寫、頁面載入速度快不快、純文字內容夠不夠多,這一步回答的問題是:「你的頁面本身有沒有問題?」
前面提到的首頁內容太薄、description 複製標題,都是在這一步被抓出來的。
第四步:看搜尋排名(SERP 分析)
查詢你的目標關鍵字,看看你的網站有沒有出現在搜尋結果前 30 名,順便看看排在前面的競爭者是誰,這一步回答的問題是:「你跟別人比起來排在哪裡?」
比如你主攻「台北甜點推薦」這個關鍵字,查下去發現前三名是愛食記、窩客島和 Google 地圖——全部都是高權重平台。知道競爭者是誰,才能決定要正面對決還是換一組長尾關鍵字切入。
第五步:站內快速掃描
直接檢查所有文章的 frontmatter,看有沒有文章忘了寫 description。這是最簡單的一步,但也是最容易被忽略的——你以為每篇都有寫,結果一查發現一半都沒有。
寫成 Skill 檔案
把這五個步驟寫進一個 skill.md 檔案,結構長這樣:
---
name: seo-audit
description: |
對你的網站執行全面 SEO 健康檢查。
當你提到 SEO 檢查、網站健檢、搜尋排名分析時觸發。
---
# SEO Audit:網站全面健康檢查
## 使用方式
- `/seo-audit` — 執行完整檢查
- `/seo-audit https://你的網址/某篇文章/` — 針對特定頁面
## 審計流程
### 第一步:收集 Search Console 數據
(具體的查詢指令和要提取的數據欄位)
### 第二步:收集流量數據
(具體的查詢指令和要提取的數據欄位)
### 第三步:On-Page 分析
(要檢查哪些項目、每個項目的標準是什麼)
### 第四步:SERP 排名檢查
(用什麼關鍵字查、查多深)
### 第五步:站內快速掃描
(檢查 frontmatter 的腳本)
## 報告格式
(結果要用什麼格式呈現)重點是每一步都要寫清楚「做什麼」和「怎麼判斷好壞」。比如 title 長度,我們寫了「建議 30-60 字元」;content rate 寫了「低於 10% 視為過低」;純文字字數寫了「低於 300 字視為薄內容」。
有了這些明確的標準,Claude Code 才能幫你做出有意義的判斷,而不是只丟一堆數字給你。
實際執行的效果
Skill 建好之後,在 Claude Code 裡打 /seo-audit,它就會自動跑完五個步驟,最後產出一份結構化的報告,長得像這樣:
# SEO 健康檢查報告
## 搜尋表現總覽
| 指標 | 數值 |
|-----------|-------|
| 週總點擊 | 45 |
| 週總曝光 | 1,200 |
| 平均 CTR | 3.7% |
## 問題清單
🔴 首頁 title 過短(8 字元,建議 30-60)
🔴 3 篇文章缺少 meta description
🟡 關於頁面純文字只有 42 字
🟢 所有頁面都有 canonical 標籤
🟢 Sitemap 正常提交
## 待修正項目
1. 修改首頁 title,加入核心服務關鍵字
2. 補上缺少的 meta description
3. 在電子書封面頁加入摘要段落紅色代表嚴重問題、黃色是建議改善、綠色是正常,一眼就能看出哪裡需要處理。
以前要花兩個小時手動做的事,現在一句話、三分鐘跑完,而且因為每次跑的檢查項目都一樣,不會因為你忘了某個步驟而漏掉問題。
你也可以做一個簡化版
我們的 SEO 健檢 Skill 整合了三個外部數據來源,設定上比較複雜,但你完全可以做一個簡化版,只做「站內檢查」——不需要任何外部工具,只靠 Claude Code 讀取你的專案檔案就能完成。
在你的部落格專案裡建一個檔案:
你的專案/.claude/skills/seo-check/skill.md內容這樣寫:
---
name: seo-check
description: |
檢查部落格文章的 SEO 基本設定。
當提到 SEO 檢查、文章檢查時觸發。
---
# SEO 基本檢查
檢查所有文章的 frontmatter,找出以下問題:
1. 沒有 description 欄位的文章
2. description 和 title 內容完全相同的文章
3. title 超過 60 字元或少於 10 字元的文章
4. description 超過 160 字元或少於 50 字元的文章
輸出格式:
- 先列出有問題的文章和具體問題
- 再列出通過檢查的文章數量
- 最後給一個總結:X 篇有問題 / Y 篇正常存檔之後,在 Claude Code 裡打 /seo-check,它就會自動去讀你的文章檔案,幫你找出哪些文章的 SEO 設定有問題。
這個簡化版不需要 Search Console 也不需要任何外部 API,但已經能抓到最常見的問題——尤其是「忘了寫 description」這種低級但致命的失誤。
進階:加上更多檢查
等你用習慣了,可以慢慢往 Skill 裡加入更多檢查項目,比如:
- 檢查有沒有圖片缺少 alt text
- 檢查文章字數是否低於 300 字(薄內容)
- 檢查內部連結有沒有指向不存在的頁面
- 檢查 frontmatter 的日期格式是否正確
每加一個檢查項目,就是多一道安全網。你不需要一次到位,先從最基本的開始,之後每次發現新問題就把它加進去。
回到整個系列
從第一篇的基礎概念開始,這五篇文章帶你走過了完整的流程:
- 搞懂 Astro、Git、Cloudflare — 認識工具
- 安裝 Astro 與 Git 存檔 — 建立專案
- 部署上線與自訂網域 — 讓全世界看到
- SEO 設定與流量追蹤 — 讓搜尋引擎找到你
- SEO 自動健檢(本篇)— 持續追蹤和改善
前四篇是「把東西蓋好」,這一篇是「定期回來巡一下」。
SEO 不是做完一次就結束的事。每寫一篇新文章,就多一個需要檢查的頁面。Google 的演算法會變,競爭對手也在持續產出內容,有了自動健檢的工具,至少你不用再靠記憶力來維護這些事情——打一句話,三分鐘後就知道哪裡需要處理。
剩下的,就是持續寫好每一篇文章。工具幫你顧好技術面,但真正決定排名的,還是你的內容有沒有價值。
延伸思考
這篇文章的建議建立在幾個前提上,值得進一步思考:
- 健檢只能抓到「技術設定層」的問題——domain authority 不夠、反向連結太少、內容缺乏差異化,這些不是跑一次
/seo-audit就能解決的。技術面全部綠燈,排名還是可能上不去 - 新站前幾個月,三維度交叉比對的價值有限——GSC 數據接近零、流量也很低,此時與其看報表,不如專注在頁面體質這一個維度就好
其他領域也有類似的模式:
- 軟體工程的 CI/CD linting——每次部署前自動跑一套程式碼品質檢查,跟 SEO 健檢本質上是同一件事:「內容上線前的自動化品管」
- 知識管理的外化過程——把「我知道 SEO 該查什麼」寫成 Skill 文件,就是把隱性知識轉化為顯性知識。一旦寫成文件,這份知識就不再依賴個人記憶,可以被任何人複用
常見問題
Claude Code 的 Skills 需要會寫程式才能做嗎?
不需要。Skill 檔案就是一個 Markdown 文字檔,你只要用日常語言描述「要做什麼」和「怎麼判斷結果」就好。Claude Code 會自己決定怎麼執行,你甚至可以請 Claude Code 幫你寫 Skill——跟它說你想自動化什麼流程,它會幫你產生 skill.md 的內容。
SEO 健檢多久做一次比較好?
建議每寫完一批文章(比如三到五篇)或每個月做一次。不需要每天檢查,重點是養成「定期回頭看」的習慣,而不是等到發現流量掉了才去找原因。如果你有在追蹤 Google Search Console 的數據,每週掃一眼曝光和點擊的趨勢就夠了。
文章的 meta description 怎麼寫比較好?
用 50 到 76 個中文字,清楚描述這篇文章能給讀者什麼。不要只是複製標題,而是回答「讀者為什麼要點進來看」這個問題,好的 description 像是電影預告——讓人知道大概在講什麼,但又好奇到想看完整版。記得包含你希望這篇文章被搜到的關鍵字。
Claude Code x WordPress 網站管理
第 12 篇,共 21 篇我一直在想一件事:怎麼讓 Claude Code 直接幫我管 WordPress 網站?
最早的想法是自己寫一支外掛,開一組 REST API 讓 Claude Code 呼叫。後來也研究過用 MCP(Model Context Protocol)來串接。但越想越覺得不對——不管是自建 API 還是 MCP,Claude Code 能做的事都被限制在這些工具提供的端點裡。我想新增一個功能,就得先回去改 API;我想查一個 log,得先確認有沒有對應的 endpoint。
我真正想要的不是這個。我想要的是:Claude Code 直接幫我寫外掛、直接丟到主機上測試、直接用 WP-CLI 操作資料庫。不是透過中間層間接控制,而是像我自己 SSH 進主機一樣,什麼都能做。
透過 API 或 MCP 技術上做得到,但要把 WordPress 的管理權限開放給外部呼叫,風險太高。一個 API endpoint 設計不好,等於幫攻擊者開了一扇門。
後來發現答案其實很簡單——SSH。
我在 Terminal 裡打了一句話:「幫我找出 Gmail 裡的退信,把對應的殭屍帳號從 WordPress 刪掉。」
三十秒後,Claude Code 讀完退信、提取出失敗的 email、SSH 進遠端主機、用 WP-CLI 查到那個帳號、確認是機器人註冊的,然後刪除。整個過程我只按了一次確認。
這不是什麼未來場景。我今天早上剛做完。
先搞懂 SSH 是什麼
你的 WordPress 網站放在一台遠端的電腦上,也就是主機。平常你透過瀏覽器打開後台管理介面來操作它,但其實還有另一種方式——直接「登入」那台電腦,用打字下指令的方式操作。
SSH 就是這個遠端登入的通道。你可以把它想像成一條加密的秘密隧道,連接你的電腦和主機。透過這條隧道,你可以在自己的電腦上對主機下達指令,就像你坐在那台主機前面一樣。
那 SSH key 又是什麼?一般登入需要帳號密碼,但每次都要輸入密碼很麻煩,而且密碼可能被猜到。SSH key 是一種更安全的驗證方式——它會產生一對鑰匙,一把「私鑰」留在你的電腦上,一把「公鑰」放到主機上。連線時兩邊自動配對,對上了就放行,不需要輸入任何密碼。
這對 Claude Code 來說很重要。因為它沒辦法像人一樣互動式地輸入密碼,但有了 SSH key,它就能直接連進主機執行指令,完全不需要人工介入。
設定步驟
整個設定大概五分鐘。
第一步:產生 SSH Key
在 Claude Code 裡直接請它幫你產生:
ssh-keygen -t ed25519 -f ~/.ssh/id_ed25519_你的主機名稱 -N "" -C "claude-code"-N "" 是空密碼,這樣 Claude Code 才能非互動式地使用這把 key。ed25519 是目前推薦的演算法,比 RSA 更快更安全。
第二步:把公鑰加到主機
產生完會有兩個檔案:私鑰和 .pub 結尾的公鑰。把公鑰的內容複製起來,貼到你主機的 SSH 設定裡。
每家主機商的操作位置不同:
- Kinsta — Dashboard → 站台 → SFTP/SSH → SSH Keys → Add SSH Key
- Cloudways — Server → Security → SSH Keys
- 自管 VPS — 貼到
~/.ssh/authorized_keys
第三步:設定 SSH Config
這一步最關鍵。在 ~/.ssh/config 加上一組別名:
Host kinsta
HostName 你的主機IP
Port 你的SSH Port
User 你的使用者名稱
IdentityFile ~/.ssh/id_ed25519_你的主機名稱
IdentitiesOnly yes設完之後,ssh kinsta "whoami" 能成功回傳使用者名稱,就代表搞定了。
從這一刻起,Claude Code 只要執行 ssh kinsta "任何指令",就等於在你的遠端主機上操作。
實際能做什麼?
設定好之後,你可以用自然語言請 Claude Code 做這些事:
網站維護
「幫我看一下遠端主機裝了哪些外掛,有沒有需要更新的。」
Claude Code 會執行 ssh kinsta "cd public && wp plugin list" 然後列出清單。需要更新就一句話搞定。
會員管理
「幫我搜尋這個 email 的會員帳號,如果是殭屍帳號就刪掉。」
它會用 wp user get [email protected] 查詢,確認角色和註冊時間,然後執行刪除。刪除前還會跟你確認。
除錯
「網站回報 500 錯誤,幫我查一下 error log。」
它會直接 SSH 進去看 log,分析錯誤訊息,可能還會順便找到問題根源。
資料庫操作
「幫我把所有草稿狀態超過一年的文章刪掉。」
ssh kinsta "cd public && wp post delete \$(wp post list --post_status=draft --format=ids --date_query='{\"before\":\"1 year ago\"}') --force"你不需要自己寫這串指令。告訴 Claude Code 你要什麼,它會自己組出來。
批次作業
「把所有商品的 SEO 標題,從商品名稱改成『商品名稱 | 品牌名稱』的格式。」
這種手動要改幾百筆的工作,Claude Code 可以寫一段 WP-CLI 腳本一次跑完。
搭配其他工具更強大
SSH 只是基礎層。當你把其他工具也串起來,Claude Code 就變成一個完整的網站維運助手。
我們今天早上做的那個「清理殭屍帳號」的任務,實際流程是這樣的:
- 用 Google Workspace CLI 搜尋 Gmail 裡的退信
- 從退信內容裡提取出失敗的 email 地址
- 透過 SSH + WP-CLI 到遠端主機查詢對應的 WordPress 帳號
- 確認是殭屍帳號後刪除
- 用 Cloudflare API 建立 WAF 規則,防止未來的機器人註冊
五個步驟,跨了三個不同的服務。全部在 Claude Code 裡一氣呵成,我只需要描述需求和按確認。
先測試站,再正式站
能直接操作主機,不代表應該直接對正式站動手。
好的工作流程是這樣的:在 ~/.ssh/config 裡設定兩組別名——一組指向測試站,一組指向正式站。
Host staging
HostName 測試站IP
User ...
IdentityFile ~/.ssh/id_ed25519_staging
Host production
HostName 正式站IP
User ...
IdentityFile ~/.ssh/id_ed25519_production日常操作的原則很簡單:改東西先在測試站跑,確認沒問題再到正式站執行。
跟 Claude Code 協作時也一樣。「幫我在測試站更新 WooCommerce 到最新版」,確認功能正常、沒有衝突之後,再說「正式站也更新」。外掛更新、PHP 版本升級、WP-CLI 批次腳本——任何可能影響網站運作的變更,都應該先過測試站。
有些操作例外。查 log、查會員資料、看外掛狀態這類唯讀操作,直接在正式站跑沒問題。刪殭屍帳號這種只影響特定資料的操作,確認對象正確後也可以直接執行。判斷的標準是:這個操作如果出錯,會不會影響到正在使用網站的人? 會的話,先去測試站。
大部分主機商都提供一鍵建立測試站的功能。Kinsta 的 Staging Environment、Cloudways 的 Staging Area,都能從正式站複製一份完整的環境。還沒有測試站的話,強烈建議先建一個。
安全性考量
把 SSH 存取權交給 AI 工具,第一反應通常是「這樣安全嗎?」
幾個重點:
私鑰只存在你的本機。 Claude Code 跑在本機,SSH key 也在本機,沒有任何憑證被上傳到雲端。
每個指令都會顯示在 Terminal。 Claude Code 不會偷偷執行什麼。每一步操作你都看得到,破壞性操作(刪除檔案、刪除帳號)會先跟你確認。
可以限制 SSH 使用者權限。 大多數主機商的 SSH 帳號本來就不是 root。你在遠端能做的事有上限,Claude Code 也一樣。
建議用獨立的 SSH key。 不要共用你平常登入用的 key。獨立的 key 方便管理,要撤銷存取權只要刪掉那把 key。
測試站和正式站用不同的 key。 這樣即使你不小心在對話中搞混別名,也不會因為同一把 key 通行兩邊而造成意外。
常見問題
連線時一直要求輸入密碼怎麼辦?
確認 ~/.ssh/config 裡有加 IdentitiesOnly yes,而且 IdentityFile 路徑正確。如果主機端的公鑰沒加好,SSH 會 fallback 到密碼驗證。
適用哪些主機商?
任何支援 SSH 的主機都行。Kinsta、Cloudways、Linode、DigitalOcean、自架 VPS,甚至共享主機(如果有開 SSH)都可以。
WP-CLI 一定要有嗎?
不一定,但強烈建議。沒有 WP-CLI,Claude Code 還是能透過 SSH 操作檔案和跑指令。但有了 WP-CLI,它就能用結構化的方式管理 WordPress——查外掛、管使用者、操作資料庫,效率差很多。大部分主機商都有預裝 WP-CLI。
會不會不小心搞壞網站?
Claude Code 在執行破壞性操作前會先跟你確認。但更好的做法是養成習慣:有風險的變更先在測試站驗證。確保你的主機有自動備份,Kinsta 每天自動備份,大部分主機商也都有類似機制。真的出事可以回滾。
多個網站怎麼管理?
在 ~/.ssh/config 裡設定多組別名就好:
Host site-a
HostName ...
User ...
IdentityFile ~/.ssh/id_ed25519_site_a
Host site-b
HostName ...
User ...
IdentityFile ~/.ssh/id_ed25519_site_b跟 Claude Code 說「連到 site-a 看一下外掛狀態」「連到 site-b 更新 WooCommerce」,它會自動用對應的別名。
跟 FTP / SFTP 差在哪?
FTP 只能傳檔案。SSH 能執行指令。Claude Code 需要的是在遠端「做事」,不只是搬檔案。用 SSH 它能跑 WP-CLI、看 log、改設定、重啟服務,這些 FTP 都做不到。
回頭看整個流程
設定 SSH key 本身不難,五分鐘的事。但它打開的可能性很大。
以前管 WordPress 網站,我得開 Dashboard 點來點去,或是 SSH 進主機自己打指令。現在我只要用中文跟 Claude Code 講一句話,它會自己決定該用什麼指令、怎麼組合、按什麼順序執行。
它不只是一個更快的 Terminal。它是一個理解你意圖、能跨工具協作的維運助手。而 SSH key,就是讓這一切成為可能的第一步。
Claude Code x 製作商業簡報
第 13 篇,共 21 篇我們團隊每次寫完一篇文章,就會開始想:這個內容之後要對客戶提案、在內部分享,或拿去社群聚會上講。每一次都得重新打開簡報軟體,把文章的重點一段一段搬過去,調版型、對齊、改字級。
同一份內容做了兩次,結果文章改了,簡報忘了更新。
後來我們團隊找到了一種「網頁簡報」的做法——使用一套叫做 Marp 的工具,讓文章內容可以直接轉換成簡報,而且簡報的風格會自動跟官網一致。只要跟 AI 助手說一句「幫我做成簡報」,五分鐘後就有一份可以直接使用的簡報,還能嵌在文章頁面上讓讀者直接翻閱。
什麼是網頁簡報?
簡單來說,網頁簡報就是一份可以在瀏覽器裡播放的投影片。它看起來跟傳統簡報一模一樣——有封面、有內容頁、可以一頁一頁翻——但它本質上是一個網頁。Marp 就是把文字內容自動轉換成這種網頁簡報的工具。

這代表什麼?
- 不需要安裝任何軟體。 用瀏覽器就能播放,不管是 Mac、Windows 還是手機都能看。
- 可以直接嵌在網站上。 就像上面這份簡報,讀者不需要另外下載檔案,在文章裡就能翻閱。
- 分享一個連結就好。 不用寄附件、不用擔心檔案太大、不用管對方有沒有裝 PowerPoint。
為什麼不繼續用 PowerPoint?
PowerPoint 或 Keynote 當然是好工具,但對我們團隊來說,有幾個痛點一直存在:
內容要做兩次。 文章寫完了,簡報還要再做一份。同樣的重點、同樣的結論,卻要手動搬到另一個工具裡排版。
品牌風格不一致。 每個人做的簡報長得都不太一樣。字體大小、顏色、間距,每次都要從頭調整。就算有範本,實際使用時還是會跑版。
更新很麻煩。 文章修改了,簡報也要跟著改。但通常改了文章就忘了簡報,結果兩邊的內容對不上。
網頁簡報解決了這三個問題。
一份內容,自動變成兩種形式
我們團隊的做法是這樣的:寫文章和做簡報用的是同一份內容來源。文章更新了,重新產生一次,簡報也跟著更新。不會再有「簡報跟文章對不上」的問題。
而且因為簡報的視覺風格是事先設定好的——用的是跟官網同一組品牌色、同一套字體——所以產出的簡報不需要額外調整,每一份都跟官網的風格一致。
不需要自己調顏色、不需要對齊文字、不需要煩惱排版。風格一致這件事,從設定好的那一刻起就自動完成了。
四種頁面風格,涵蓋所有場景
我們設計了四種頁面類型,基本上涵蓋了商業簡報會遇到的所有場景:
封面頁
深灰色背景搭配金色標題,置中排版。放上簡報主題和公司名稱。封面頁會自動隱藏頁碼,讓畫面乾淨俐落。

一般內容頁
白色底色的標準頁面,適合放條列重點、表格、引述等內容。左上角會顯示品牌名稱,右上角顯示公司全名,每一頁都有一致的品牌識別。

深色強調頁
當你需要做章節分隔,或是有一段話特別重要想要強調時,可以切換到深色背景。標題會自動變成金色,整個畫面的視覺衝擊力明顯不同。

結尾頁
最後一頁放公司資訊和 QR Code。掃描 QR Code 就能直接連到完整的文章頁面。QR Code 會在每次產生簡報時自動更新,不需要另外製作圖片。

AI 助手幫你完成所有事
這是整個流程最省力的部分。
我們團隊使用 Claude Code 作為 AI 助手。只要說一句「幫我把這篇文章做成簡報」,它就會自動完成以下所有步驟:
- 讀取文章內容 — 理解文章在講什麼、有哪些重點
- 拆分大綱 — 判斷哪些內容該放在同一頁,怎麼分頁最合理
- 精簡文字 — 把長段落濃縮成條列式的重點,去掉不適合放在投影片上的細節
- 套用品牌風格 — 自動使用我們設定好的視覺主題,加上公司名稱和頁碼
- 加入 QR Code — 最後一頁自動放上連結到文章的 QR Code
- 產生網頁簡報 — 輸出一份可以直接播放的簡報檔案
整個過程不需要打開任何設計軟體,也不需要手動調整任何排版。從一篇兩千字的文章到一份十五頁的簡報,大約五分鐘。
簡報內容的取捨原則
簡報跟文章最大的差異是空間限制。文章可以無限往下捲,但簡報的每一頁就是一個固定大小的畫面,超出的內容會直接被截斷。
幾個我們團隊摸索出來的原則:
- 每一頁只講一個重點。 不要試圖把所有相關的事情塞在同一頁。
- 條列項目控制在四到五個以內。 超過五個,觀眾根本記不住。
- 表格不要超過五列。 太多列在投影片上根本看不清楚。
- 塞不下就拆成兩頁。 不要縮小字體來硬塞更多內容。投影片的重點是「一眼看懂」,不是「放得下」。
AI 助手在幫你轉換時,也會自動遵循這些原則來安排內容。
可以匯出成其他格式嗎?
可以。Marp 本身就支援多種匯出格式,除了網頁簡報之外,同一份內容也能透過 Marp 直接轉換成:
- PDF — 適合需要寄給客戶或列印的場合,畫面跟瀏覽器裡看到的完全一樣。
- PowerPoint(PPTX) — 如果客戶堅持要 PowerPoint 格式也沒問題,不過自訂的視覺風格可能會有些微差異。建議優先使用 PDF。
不管匯出什麼格式,都是從同一份來源產生的,不需要額外製作。
如果你習慣用其他簡報工具呢?
Marp 是我們團隊的選擇,但不是唯一的選擇。如果你的團隊已經習慣用 PowerPoint、Keynote、Canva 或 Google Slides,現在也有對應的 AI 整合工具,同樣可以讓 AI 助手直接幫你製作簡報。
PowerPoint
Office-PowerPoint-MCP-Server 是一套開源的 AI 整合工具,讓 AI 助手可以直接建立和編輯 PowerPoint 檔案——新增投影片、插入圖表、調整格式,全部由 AI 完成。如果需要更精緻的成品,SlideSpeak 和 Plus AI 則是商業方案,支援自訂範本和更豐富的視覺效果。
Keynote
Mac 使用者可以試試 keynote-mcp,它讓 AI 助手透過 macOS 的自動化功能直接操控 Keynote,支援三十多種操作,包含建立簡報、新增投影片、插入圖片等。
Canva
Canva 官方已經推出了 AI 整合工具,可以讓 AI 助手直接在 Canva 裡建立設計、套用範本、搜尋素材,還能匯出成 PDF 或圖片。如果你的團隊本來就在用 Canva,這是最無痛的整合方式。
Google Slides
Google Workspace MCP 讓 AI 助手可以操作整個 Google 工作區,包含 Google Slides。Google 自己也推出了官方的 AI 整合方案,支援直接透過 AI 建立和修改簡報。
不管你選哪一套工具,核心概念都一樣:讓 AI 幫你處理排版和格式,你只需要專注在內容上。
常見問題
需要會寫程式才能用嗎?
不需要。整個流程是由 AI 助手完成的。你只需要會寫文章,然後告訴 AI 助手「幫我做成簡報」就好。所有技術上的事情——格式轉換、套用風格、產生檔案——都是自動完成的。
簡報可以離線播放嗎?
簡報本身可以離線播放,因為它是一個獨立的網頁檔案。但最後一頁的 QR Code 需要網路連線才能顯示。如果需要在沒有網路的環境使用,可以事先把 QR Code 圖片存到本地。
每一頁放不下所有內容怎麼辦?
拆成兩頁。不要試圖縮小字體來塞更多內容。簡報的核心原則是讓觀眾「一眼看懂」,而不是「把所有東西都放上去」。
文章更新了,簡報會自動更新嗎?
不是全自動,但非常簡單。文章修改後,只要再跟 AI 助手說一聲「重新產生簡報」,它就會根據最新的文章內容重新產生。因為來源是同一份,所以不會出現內容不一致的問題。
可以加入圖片嗎?
可以。但要注意投影片的畫面空間有限,圖片太大會擠壓文字的空間。建議一張投影片上如果有圖片,文字就少放一點,讓畫面保持清爽。
我們團隊目前的工作流程
最後整理一下:
- 寫完文章
- 跟 AI 助手說「幫我做成簡報」
- AI 讀取文章、整理大綱、套用品牌風格
- 最後一頁自動加上 QR Code
- 產生網頁簡報
- 簡報直接嵌在文章頁面上
整個過程不需要打開任何設計軟體,不需要手動排版,也不需要擔心品牌風格不一致。
對我們團隊來說,最大的改變是心態上的轉換:簡報不再是一個獨立的產出物,而是文章的延伸。寫完文章,簡報就自然而然地產生了。
用 Claude Code 串接 Cloudflare Web Analytics API:自動產生每日流量報告
第 14 篇,共 21 篇我們團隊的官網 codotx.com 部署在 Cloudflare Pages 上,流量分析用的是 Cloudflare Web Analytics——輕量、不需要 cookie、隱私友善,而且網站本來就掛在 Cloudflare 上,在 Dashboard 開啟就能用。
但每次要看數據都得登入 Dashboard 點來點去,不太方便。我們想在 Claude Code 裡直接查流量,甚至每天自動產生報告。這篇記錄整個串接過程,包括中間踩到的幾個坑。
建立 API Token
Dashboard 看數據當然可以,但我們想在 Claude Code 裡直接查詢。Cloudflare Web Analytics 的數據可以透過 GraphQL API 取得,不過需要一組有適當權限的 API Token。
第一個嘗試是用 wrangler CLI 的 OAuth token。結果不行——wrangler 的 token scope 不包含 analytics 相關權限。
需要另外建立一組 API Token。到 Cloudflare Dashboard → My Profile → API Tokens,選擇「查看分析與記錄」範本。
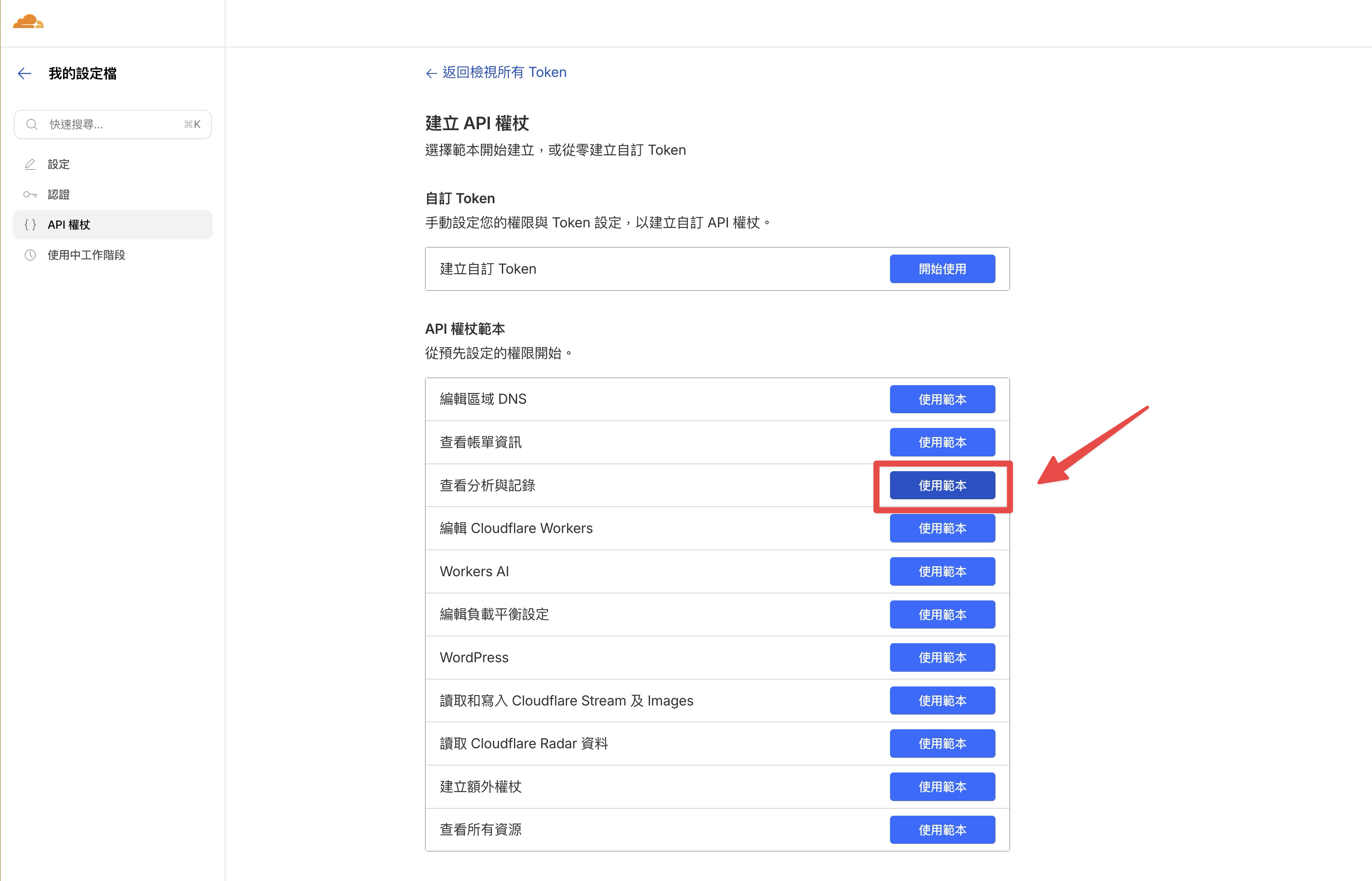
建立時有幾個重點:
- 權限需要:區域 Analytics 讀取、帳戶 Account Analytics 讀取
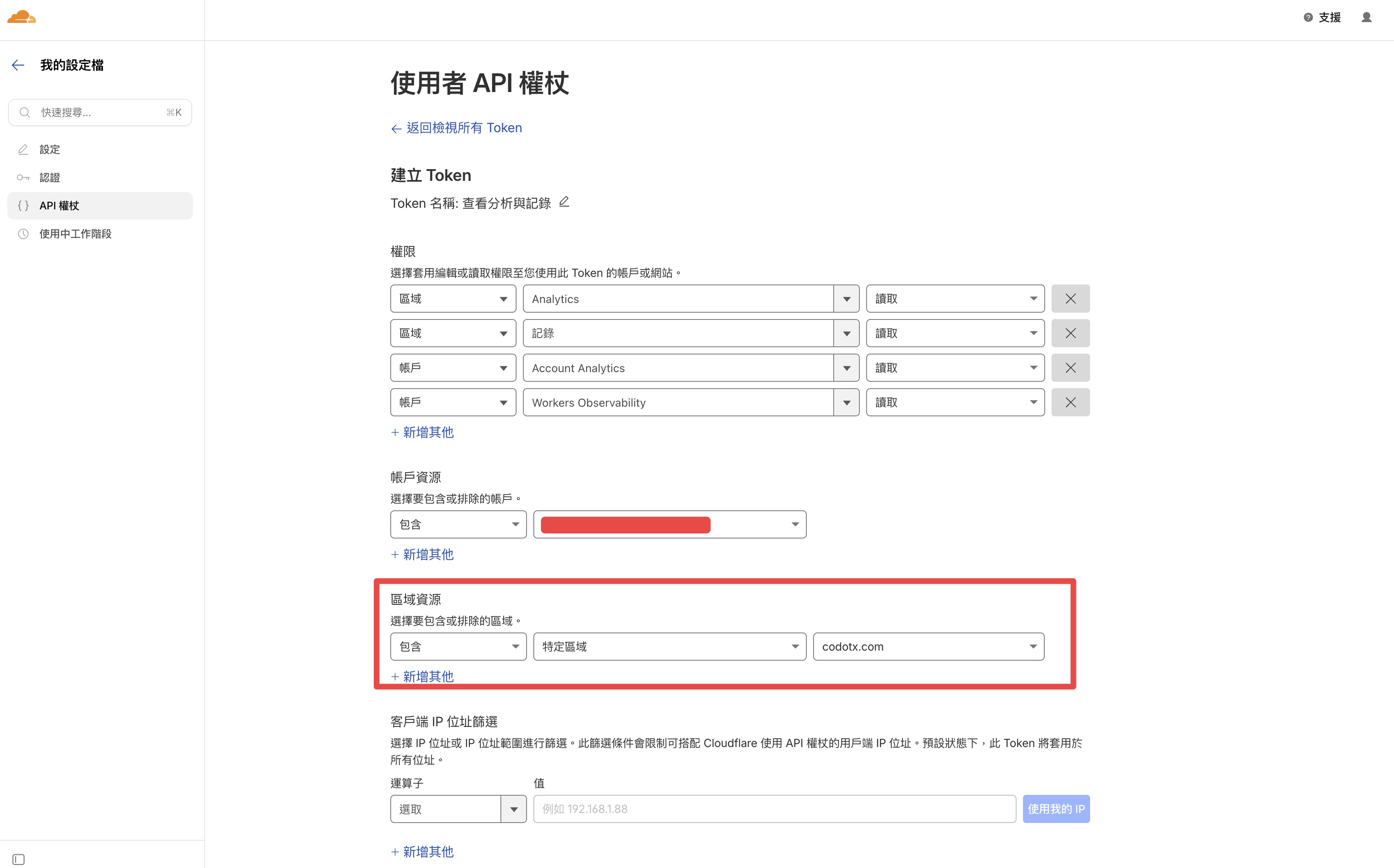
- 區域資源建議限定為特定網域,不需要開放整個帳戶的存取
建立完成後,用 verify endpoint 確認 token 有效:
curl -s "https://api.cloudflare.com/client/v4/user/tokens/verify" \
-H "Authorization: Bearer YOUR_API_TOKEN" | jq '.success'回傳 true 就表示可以用了。
用 GraphQL API 查詢流量數據
Cloudflare Web Analytics 的 API endpoint 是 https://api.cloudflare.com/client/v4/graphql。查詢需要三個參數:
- Account ID:在 Cloudflare Dashboard 首頁或 wrangler whoami 可以找到
- siteTag:用來識別網站的唯一標籤
- 日期範圍:ISO 8601 格式
siteTag 的坑
這裡我們卡了一陣子。直覺上會以為 siteTag 就是 Dashboard 上給的 beacon token,但如果你用的是自動注入模式,Cloudflare 會分配一組不同的 siteTag。
用 beacon token 查詢,回傳空陣列。資料明明在 Dashboard 上看得到,API 卻拿不到。
解法是先不帶 siteTag 篩選,改用 requestHost 來找:
curl -s -X POST "https://api.cloudflare.com/client/v4/graphql" \
-H "Authorization: Bearer YOUR_API_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"query": "{ viewer { accounts(filter: {accountTag: \"YOUR_ACCOUNT_ID\"}) { rumPageloadEventsAdaptiveGroups(filter: {datetime_geq: \"2026-03-09T00:00:00Z\", datetime_leq: \"2026-03-10T23:59:59Z\", requestHost: \"codotx.com\"}, limit: 10, orderBy: [count_DESC]) { count dimensions { requestPath siteTag } } } } }"
}'這樣就能從回傳結果裡拿到實際的 siteTag。拿到之後,後續查詢就能直接用 siteTag 篩選了。
欄位名稱的坑
GraphQL schema 裡的欄位命名不太直覺。一開始我們用 path 查詢頁面路徑,結果噴 unknown field 錯誤。正確的欄位名稱是 requestPath。
類似的情況還有國家欄位要用 countryName、瀏覽器要用 userAgentBrowser。效能數據更是要用完全不同的 dataset——rumPerformanceEventsAdaptiveGroups 而不是 rumPageloadEventsAdaptiveGroups。
完整的查詢範例
以下是我們實際在用的查詢,一次拉回熱門頁面和國家分布:
{
viewer {
accounts(filter: {accountTag: "YOUR_ACCOUNT_ID"}) {
topPages: rumPageloadEventsAdaptiveGroups(
filter: {
datetime_geq: "2026-03-09T00:00:00Z"
datetime_leq: "2026-03-10T23:59:59Z"
requestHost: "codotx.com"
}
limit: 20
orderBy: [count_DESC]
) {
count
dimensions { requestPath }
}
topCountries: rumPageloadEventsAdaptiveGroups(
filter: {
datetime_geq: "2026-03-09T00:00:00Z"
datetime_leq: "2026-03-10T23:59:59Z"
requestHost: "codotx.com"
}
limit: 10
orderBy: [count_DESC]
) {
count
dimensions { countryName }
}
}
}
}效能數據的查詢長這樣:
{
viewer {
accounts(filter: {accountTag: "YOUR_ACCOUNT_ID"}) {
performance: rumPerformanceEventsAdaptiveGroups(
filter: {
datetime_geq: "2026-03-09T00:00:00Z"
datetime_leq: "2026-03-10T23:59:59Z"
siteTag: "YOUR_SITE_TAG"
}
limit: 1
) {
count
quantiles {
pageLoadTimeP50
pageLoadTimeP75
pageLoadTimeP90
pageLoadTimeP99
}
}
}
}
}注意效能數據的單位是微秒,需要除以 1000 才是毫秒。
自動化每日報告
能從 API 拿到數據之後,下一步是自動化。我們寫了一個 shell script,每天早上用 cron job 執行,產生 markdown 格式的流量報告。
核心邏輯:
- 用
date -v-1d取得昨天的日期作為查詢範圍 - 送出三個 GraphQL 查詢:總覽 + 來源 + 裝置 + 瀏覽器、頁面 + 國家、效能
- 用
jq解析 JSON 回傳值,組合成 markdown 表格 - 儲存到
reports/YYYY-MM-DD.md
產生出來的報告長這樣:
# codotx.com 每日流量報告
**日期:** 2026-03-09
## 總覽
| 指標 | 數值 |
|------|------|
| 瀏覽量 (Pageviews) | 25 |
| 造訪數 (Visits) | 15 |
## 熱門頁面
| 頁面 | 瀏覽量 |
|------|--------|
| `/` | 18 |
| `/about/` | 2 |
| `/news/2026-03-09-claude-code-lsp-setup/` | 2 |一開始我們用 Claude Code 的 /loop 指令來排程,設定每天早上 10 點自動跑報告。用起來很方便,但有個根本問題:/loop 的排程只存在於當前 session,Claude Code 關掉就沒了。對於每天要跑的任務來說不太實際,最後還是回到 cron job。
設定 cron job 的指令:
# 每天早上 10:03 執行
3 10 * * * /path/to/scripts/daily-report.sh >> /path/to/reports/cron.log 2>&1reports/ 和 scripts/ 資料夾都加到 .gitignore,不進版控。
踩坑總結
整個串接過程遇到三個問題:
- wrangler OAuth token 權限不足 — 需要另外建立有 Analytics 讀取權限的 API Token
- siteTag 跟 beacon token 不同 — 自動注入模式下,Cloudflare 會分配不同的 siteTag,需要用
requestHost反查 - GraphQL 欄位名稱不直覺 —
path要用requestPath,效能數據要用不同的 dataset
從建立 API Token 到 cron job 跑出第一份報告,整個過程大約一個小時。大部分時間花在找 siteTag 和摸索 GraphQL schema 上。一旦搞清楚 API 的結構,後面的自動化就很順了。
如何使用 Claude Code 自動產出 SEO 週報
第 15 篇,共 21 篇經營技術部落格一段時間後,我們發現自己很少主動去看 Google Search Console。不是不想看,是每次都要登入後台、點來點去、手動比較數據,久了就懶了。但 SEO 數據其實藏著很多寶貴資訊——哪些關鍵字有人在搜、哪些頁面帶來最多流量、哪些主題值得寫更多文章。
所以我們決定:寫一個腳本,每週一早上自動從 GSC API 撈數據,產出一份 Markdown 週報,打開就能看。
我們想要的報告長什麼樣
動手之前先想清楚報告該包含什麼。我們定了四個區塊:
- 關鍵字排名 Top 20 — 哪些搜尋字詞帶來最多點擊
- 頁面導流排名 Top 15 — 哪些頁面是流量主力
- 內容機會分析 — 高曝光但低點擊的關鍵字,代表搜尋需求存在但我們的內容還沒接住
- 本週總覽 — 總點擊、總曝光、平均 CTR 等摘要數字
第三點是我認為最有價值的部分。一個關鍵字如果曝光 300 次但只被點了 1 次,要嘛排名太後面,要嘛標題不吸引人,要嘛根本沒有對應的文章。不管是哪種情況,都是可以改善的機會。
前置準備:用 gcloud 建立 API 存取
要從程式存取 GSC,需要一個 Google Cloud 的 Service Account。整個設定用 gcloud CLI 就能完成,不用進 Google Cloud Console 的網頁介面。
建立 GCP 專案
gcloud projects create codotx-gsc --name="Codotx GSC"建議為這個用途開一個獨立專案,跟其他 GCP 資源分開管理。
啟用 Search Console API
gcloud config set project codotx-gsc
gcloud services enable searchconsole.googleapis.com建立 Service Account
gcloud iam service-accounts create gsc-reader --display-name="GSC Reader"下載金鑰
gcloud iam service-accounts keys create gsc-credentials.json \
[email protected] \
--project=codotx-gsc這會在當前目錄產生一個 gsc-credentials.json,Python 腳本會用這個檔案來驗證身份。記得把它加進 .gitignore,千萬不要 commit 進版本庫。
# .gitignore
gsc-credentials.json四個指令,API 端的設定就完成了。
在 GSC 後台授權 Service Account
API 端設好了,但 GSC 那邊還不認識這個 Service Account。需要到 Google Search Console 後台手動加一次。
進入 設定 → 使用者和權限,你會看到目前的使用者清單:
點「新增使用者」,輸入 Service Account 的 email:
[email protected]權限選「限制」就夠了,我們只需要讀取數據。
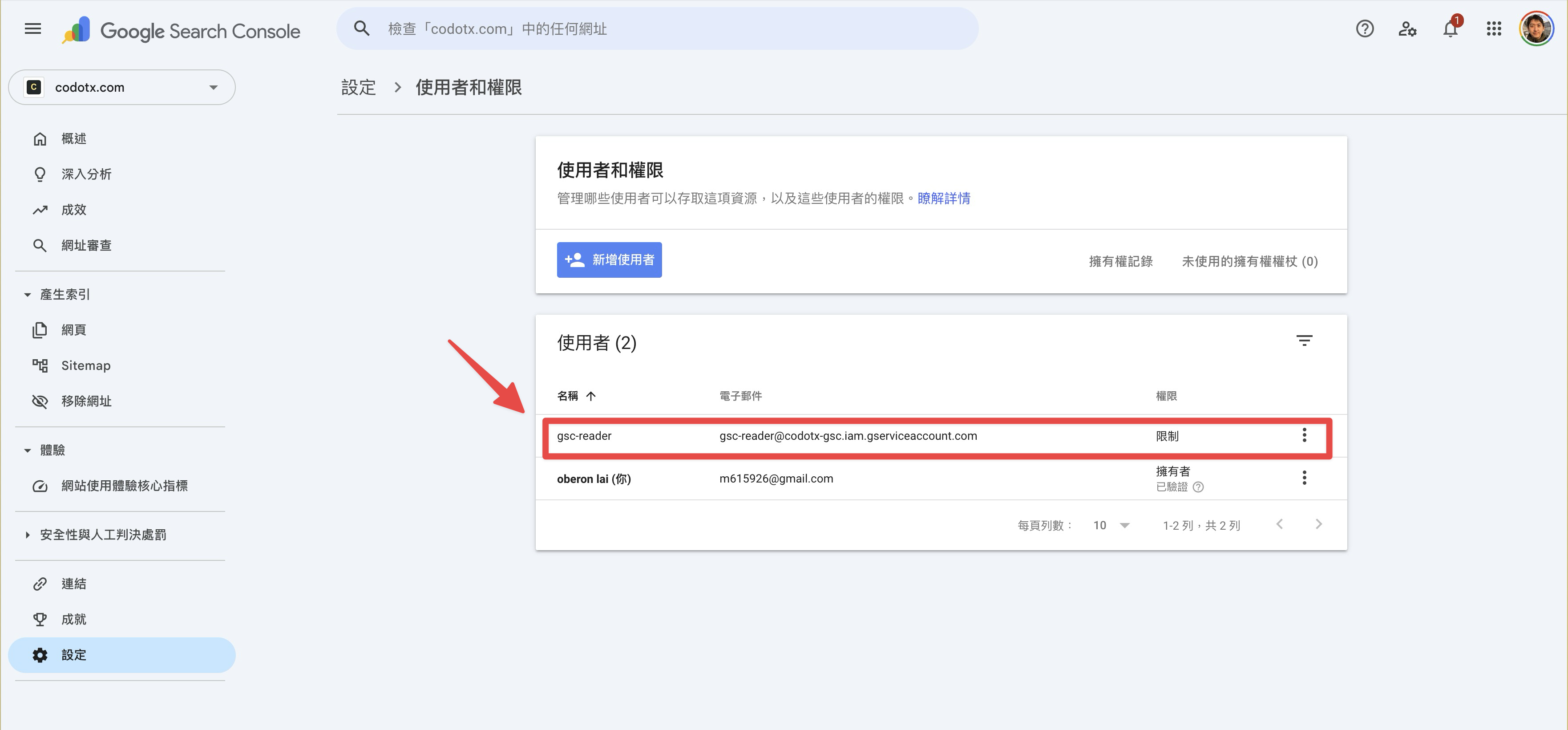
加完之後,使用者清單會多出 gsc-reader 這筆,狀態顯示為「限制」權限。到這邊,API 跟 GSC 的連線就建立好了。
撰寫查詢腳本
安裝 Python 套件:
pip3 install google-api-python-client google-auth腳本的核心是透過 searchanalytics().query() 來查詢數據。這個 API 支援多種 dimension(query、page、date、country 等),可以根據不同維度來拆分數據。
我們對同一個日期範圍發了三次查詢:
# 1. 關鍵字排名(依點擊數排序)
keywords = query_gsc(service, start_date, end_date, ['query'], 50, 'clicks')
# 2. 頁面排名(依點擊數排序)
pages = query_gsc(service, start_date, end_date, ['page'], 30, 'clicks')
# 3. 內容機會(依曝光數排序,後續再篩選)
all_keywords = query_gsc(service, start_date, end_date, ['query'], 100, 'impressions')第三個查詢拿到所有高曝光的關鍵字後,用條件篩選出「內容機會」。
一開始我們用固定門檻(曝光 >= 50 算高優先、>= 20 算中優先),但馬上發現問題:對一個新站來說,一週 50 次曝光的關鍵字可能根本沒幾個;等流量長起來後,50 次又變得不值一提。固定數字沒辦法適應不同規模的網站。
最後我們採用混合制——先設最低門檻過濾噪音,通過門檻的再用百分位數分級:
MIN_IMPRESSIONS = 20 # 週曝光低於 20 的直接忽略.
# 篩選:通過最低門檻,且 CTR 低於全站平均或排名低於全站平均.
qualified = [r for r in all_keywords if r['impressions'] >= MIN_IMPRESSIONS]
avg_ctr = sum(r['clicks'] for r in qualified) / sum(r['impressions'] for r in qualified)
avg_pos = sum(r['position'] for r in qualified) / len(qualified)
opportunities = [
r for r in qualified
if r['ctr'] < avg_ctr or r['position'] > avg_pos
]
# 用百分位數動態分級.
imp_values = sorted([r['impressions'] for r in opportunities])
p75 = percentile(imp_values, 75) # 前 25% = 高優先.
p50 = percentile(imp_values, 50) # 前 25%~50% = 中優先.這個做法的好處是門檻會隨著網站流量自動調整。報告裡也會標出本週的實際門檻值,讓你知道「高優先」這週代表的是曝光幾次以上。
分級結果:
- 高優先(曝光前 25%)— 搜尋量在你的網站中相對最大,值得專門寫一篇文章
- 中優先(曝光前 25%~50%)— 有一定搜尋量,可以優化現有內容或在相關文章中補充
- 潛力關鍵字(通過最低門檻但排名較後)— 早期訊號,持續觀察趨勢
報告日期範圍
報告自動計算「上週一到上週日」的完整七天:
days_since_monday = today.weekday()
last_monday = today - timedelta(days=days_since_monday + 7)
last_sunday = last_monday + timedelta(days=6)這樣每週一執行時,拿到的永遠是上一個完整週的數據,不會有不完整的天數。
產出格式
最後把所有數據組成 Markdown 表格,寫入 reports/gsc-weekly-YYYY-MM-DD.md。選 Markdown 而不是 CSV 或 HTML,是因為在終端機、GitHub、筆記軟體裡都能直接閱讀,不需要額外工具。
完整腳本放在 scripts/gsc-weekly-report.py,手動執行一次確認沒問題:
python3 scripts/gsc-weekly-report.py如果 API 連線正常,會看到:
Report generated: reports/gsc-weekly-2026-03-10.md設定每週自動執行
腳本能跑了,最後用 cron 排程讓它每週一早上 10 點自動執行:
crontab -e加入這行:
# codotx.com GSC 週報 - 每週一上午 10:00 執行
0 10 * * 1 /usr/local/bin/python3 /path/to/scripts/gsc-weekly-report.py >> /path/to/reports/cron.log 2>&1注意幾個細節:
- 用絕對路徑指定
python3和腳本位置,cron 的 PATH 環境跟你的 shell 不一樣 - 把 stderr 導到 log 檔,萬一執行失敗有紀錄可查
* * 1的1代表星期一(0 是星期日)
報告實際長什麼樣
產出的週報會長這樣:
關鍵字排名:
| # | 關鍵字 | 點擊 | 曝光 | CTR | 平均排名 |
|---|---|---|---|---|---|
| 1 | line flex message | 6 | 97 | 6.2% | 4.7 |
| 2 | line user id 查詢 | 6 | 12 | 50.0% | 3.3 |
| 3 | flex message | 4 | 116 | 3.4% | 6.8 |
| 4 | line login | 4 | 296 | 1.4% | 6.9 |
| 5 | line notify 替代方案 | 4 | 55 | 7.3% | 4.2 |
內容機會分析:
篩選條件:週曝光 >= 20,且 CTR 低於全站平均或排名低於全站平均 本週門檻:高優先 >= 206 曝光、中優先 >= 76 曝光
高優先(>= 206 曝光,前 25%):
| 關鍵字 | 曝光 | 點擊 | CTR | 排名 |
|---|---|---|---|---|
| line notify | 347 | 1 | 0.3% | 9.9 |
| line login | 296 | 4 | 1.4% | 6.9 |
中優先(76~205 曝光):
| 關鍵字 | 曝光 | 點擊 | CTR | 排名 |
|---|---|---|---|---|
| flex message | 116 | 4 | 3.4% | 6.8 |
| ai 圖像辨識網站 | 76 | 0 | 0.0% | 10.3 |
跟一開始用固定門檻的版本比,原本列出 18 個「機會」,混合制篩到只剩 7 個。數量少了但每個都更值得投入。例如「line notify」曝光 347 次但只被點了 1 次,排名在第 10 名左右,寫一篇完整教學搶進前 5 名,流量成長空間很大。而像「ai 圖像辨識網站」曝光 76 次、完全沒被點擊,代表有搜尋需求但我們沒有對應內容,是一個明確的內容缺口。
整體需要的工具
回顧一下,實現這個自動週報需要以下工具:
- gcloud CLI — 建立 GCP 專案、啟用 API、建立 Service Account
- Google Search Console — 在後台授權 Service Account 讀取權限
- Python + google-api-python-client — 查詢 Search Analytics API、產出 Markdown 報告
- cron — 每週一自動執行腳本
設定完成後,每週一早上報告就會自動出現在 reports/ 資料夾裡。不用登入任何後台,打開檔案就能看到上週的 SEO 表現和下一步該寫什麼文章。
對我們來說,這份報告最實用的部分是內容機會分析。它把「猜測讀者想看什麼」變成了「數據告訴你讀者在搜什麼」,寫文章的方向清楚很多。更進一步,每週一早上拿到報告後,我們會直接把內容機會丟給 AI,請它根據這些高曝光、低點擊的關鍵字來撰寫對應的文章。從數據採集到內容產出,整條流程都能在同一個早上完成。
用 Claude Code Skill Creator 打造技術部落格寫作 Skill
第 16 篇,共 21 篇我們團隊用 Claude Code 寫程式已經一段時間了,最近開始研究它的 Skill 機制——可以把特定的工作流程封裝成一份指令文件,之後只要觸發對應的 Skill,Claude 就會依照預設的規範執行任務。
我們第一個想做的 Skill 是「技術部落格寫作」。原因很直接:公司的技術文章產出頻率不高,每次寫都要重新跟 AI 溝通語氣、格式、禁用詞彙,效率不好。如果能把這些規範寫成 Skill,以後只要丟素材進去就能產出符合風格的初稿,應該能省下不少時間。
這篇記錄我們從零開始設計這個 Skill 的完整過程,包含中間踩的坑和迭代修正。
我們想要的效果
- 丟入技術主題和背景素材,產出一篇符合公司風格的繁體中文技術文章
- 文章語氣專業但不僵硬,有真實經驗的支撐
- 自動遵守格式規範:正確的 frontmatter、檔案命名、圖片路徑
- 避免 AI 味的寫法:「隨著…的發展」「賦能」「讓我們拭目以待」這類用語一律不出現
第一步:分析現有文章的風格
設計 Skill 之前,我們先分析了自己網站上幾篇文章的寫作模式。抓了三篇不同類型的文章來讀:
- Cloudflare Pages 預覽環境設定教學 — 踩坑紀錄型
- 與 AI 合作開發的四種方式 — 工具比較型
- 多巴胺開發 Dopamine Coding — 個人反思型
從這三篇歸納出幾個共同特徵:
- 開場直接交代「我們要做什麼」或「發生了什麼事」
- 用「我們」或「我」當主語,不用被動語態
- 踩坑的描述帶有排查脈絡,不只是列出問題和答案
- 結尾用具體清單或成果收束,沒有感性結語
- 程式碼區塊只放讀者需要複製的部分
同時也讀了 content config 和 category 設定,確認 frontmatter 的格式要求。
第二步:參考 humanizer-tw
除了分析自己的文章,我們還參考了 GitHub 上的 humanizer-tw 這個 Skill。它專門處理中文 AI 寫作的去痕跡問題,把常見的 AI 味寫法分成八大類、19 個具體問題,每個都附上替換表和改寫範例。
這個 Skill 有幾個設計值得借鑑:
- 系統化分類:不只是列一堆「禁用詞」,而是按類別整理(開場套話、互聯網黑話、翻譯腔、書面語過重等),方便 AI 逐項檢查
- 「個性與靈魂」的概念:它指出「乾淨但無靈魂」的文字跟 AI 味重的文字一樣有問題。光是去除壞模式不夠,還要主動注入真實感
- 品質評分機制:用五個維度各 10 分的方式自評,給 AI 一個具體的品質標準
不過 humanizer-tw 的語氣定位偏口語,像是「我覺得」「得想想」「聊一下」,這對個人部落格合適,但我們是公司技術部落格,需要再正式一些。
第一個坑:語氣太像個人部落格
第一版 Skill 寫完後,我們用三個測試案例跑了一輪:
- wp-env Docker 開發環境的踩坑紀錄
- Cursor vs Claude Code 的工具比較
- AI 時代接案公司轉型的反思
三篇都順利產出,格式正確、沒有 AI 套話。但讀完之後有個明顯問題:語氣太隨性了。
踩坑紀錄那篇出現了「光看那個 crash log 真的完全猜不到原因」,反思那篇寫了「玻璃心碎了一地」「快崩潰」。這些表達放在個人部落格完全沒問題,但放在公司的技術部落格就顯得不夠專業。
問題出在 Skill 裡的語氣指引。第一版寫的是「讓人覺得是一個真的工程師在跟你聊天」,這個定位太偏聊天了。
修正方式
我們重新定義了語氣定位:「專業技術文章,但讀起來不會想睡。」並且加了一張三欄語氣校準表,明確標出「太正式」「適當」「太隨便」的分界:
| 太正式 | 適當 | 太隨便 |
|---|---|---|
| 經由詳細的調查分析 | 排查之後發現 | 隨便 google 一下 |
| 予以高度重視 | 我們很重視這個問題 | 超在意的 |
還特別標注了一點:「我認為」在本部落格是適當的用語,不需要降到「我覺得」。這是跟 humanizer-tw 不同的地方。
修正後重跑三篇測試,語氣明顯改善。「光看那個 crash log 真的完全猜不到原因」變成了「一開始我們沒有馬上聯想到是架構相容的問題」,「玻璃心碎了一地」變成了「這個問題困擾了我好一段時間」。專業但不死板。
第二個坑:AI 寫作問題沒有系統化分類
第一版 Skill 有列禁用清單,但只是把所有禁用詞和句型混在一起。AI 在執行時容易遺漏,因為沒有分類就沒有逐項檢查的依據。
參考 humanizer-tw 的做法後,我們把 AI 寫作問題整理成八大類、19 個具體問題:
- 開場白與連接詞(3 個):時代開場白、共識開場白、連接詞濫用
- 互聯網黑話(2 個):商業術語、動詞術語
- 翻譯腔(3 個):「這是一個…」結構、「的」字堆疊、被動語態
- 書面語過重(2 個):書面代詞、介詞結構
- 公式化結構(2 個):三段式公式、否定式排比
- 結尾套話(2 個):展望類、反思類
- 語氣問題(3 個):過度正式、缺乏觀點、絕對詞
- 節奏問題(2 個):句子長度單一、過渡詞依賴
每個類別都附上替換表或改寫範例,讓 AI 有明確的對照可以參考。
第三個坑:光去除 AI 味不夠
這個問題是從 humanizer-tw 的「個性與靈魂」段落得到的啟發。即使文字通過了所有 AI 味檢查,如果每句話都正確但沒有觀點、沒有轉折、沒有真實經驗的痕跡,讀起來還是像機器寫的。
我們在 Skill 裡加了「缺乏靈魂的警訊」清單:
- 每個句子長度和結構都相同
- 沒有觀點,只有中立描述
- 不承認不確定性或取捨
- 全文沒有第一人稱
- 讀起來像產品文件或新聞稿
以及七個「增添人味的技巧」:交代決策脈絡、加入具體數字、寫出轉折、帶入觀點、變化節奏、承認不確定性、對感受要具體。
最終成果
經過兩輪迭代,最終產出的 Skill 是一份約 300 行的 SKILL.md,包含以下模組:
- 文章格式規範:frontmatter 格式、檔案命名規則、圖片路徑
- 三種文章結構模板:踩坑紀錄、工具比較、觀點反思
- 語氣定位:語氣校準表、開場和結尾的寫法指引
- 人味注入指南:靈魂警訊清單、七個增添人味的技巧
- 19 個 AI 寫作問題:八大類分類,附替換表和改寫範例
- 品質評分:直接性、節奏、信任度、真實性、精煉度五個維度,各 10 分
- 快速檢查清單:交付前的 11 項逐項確認
實際使用時,只要告訴 Claude Code「幫我寫一篇關於 X 的文章」,它就會自動載入這份 Skill,按照規範產出初稿。如果素材不足,它會主動詢問缺少的資訊,不會自己編造技術細節。
設計 Skill 的幾個心得
先分析再動手。 我們一開始就讀了自己的文章和別人的 Skill,這讓第一版的品質有一個不錯的起點。如果直接憑感覺寫,可能要多迭代好幾輪。
測試案例要涵蓋不同類型。 如果我們只測了踩坑紀錄,可能不會發現語氣在反思型文章中過於隨性的問題。三種模式各跑一篇,問題很快就浮現了。
語氣校準需要明確的邊界。 光說「專業但不僵硬」太模糊,AI 不知道邊界在哪。三欄對照表(太正式 / 適當 / 太隨便)比抽象描述有效得多。
去除 AI 味和注入人味是兩件事。 前者是刪掉壞的,後者是加入好的。只做前者會得到乾淨但無聊的文字。兩者都做,才能產出讀起來像真人寫的文章。
Claude Code x 設計電子書閱讀體驗
第 17 篇,共 21 篇我平常就有在使用電子書裝置來閱讀書籍。翻頁、調字體、換背景色、關掉瀏覽器下次自動接上——這些體驗一旦習慣了,回頭看網站上的文章就覺得少了點什麼。
捲動式的長頁面、旁邊的側邊欄、頂部的選單列,這些東西在「瀏覽」的時候很好用,但在「閱讀」的時候是干擾。於是我開始想:我們寫的這些 Claude Code 教學文章,是否也可以改用電子書的形式,提供給讀者更乾淨、沒有干擾的閱讀體驗?
加上這些文章散落在十個不同的網址,讀者想從頭讀到尾,得在不同頁面之間跳來跳去。讀起來像在翻一本被拆散的書。
我們決定把這些文章重新組裝起來,做成一本可以在網頁上直接翻頁閱讀的電子書。
散落的文章,斷裂的閱讀
一般部落格的閱讀方式是這樣的:打開一篇文章,從頭捲到尾,看完了,回到列表頁,找下一篇,點進去,再捲一次。每篇文章之間沒有連結、沒有順序、沒有「上一篇 / 下一篇」的脈絡。
對於偶爾逛進來的讀者來說,這沒什麼問題。但對於想系統性學習的讀者,這個體驗很破碎。
他不知道應該先讀哪一篇。讀完一篇之後,也不確定下一步該看什麼。如果中間被打斷,下次回來得重新找到上次讀到的那篇文章——還不一定找得到。
我們想解決的,就是這個斷裂感。
像翻書一樣,一頁一頁讀
我們跟 Claude Code 描述了這個需求:想要一個獨立頁面,把十篇文章串成一本書,讓讀者可以像用 Kindle 一樣,一頁一頁往下翻。不是捲動,是真的翻頁——畫面上一次只顯示一頁的內容,點一下就翻到下一頁。
Claude Code 聽完之後,提出了一個跟專業電子書引擎相同的做法。它把所有文章的內容排列在一起,再根據螢幕大小自動切成一頁一頁的畫面。讀者看到的每一頁,剛好就是螢幕能容納的內容量。
最後做出來的閱讀器,有幾個讓我們滿意的細節。
翻頁手感。 在手機上左右滑動,或是點螢幕的左右兩側,就能翻頁。在電腦上用鍵盤的方向鍵也行。操作方式跟一般電子書 App 一樣直覺。

閱讀設定。 讀者可以自己調整文字大小、行高、背景顏色(白色、米色、深色)和字型。每個人對「好讀」的定義不同,把控制權交給讀者自己。
章節目錄。 左上角有一個目錄按鈕,點開後從螢幕左側滑出完整的章節列表。想跳到特定文章,直接點就能到。目前正在讀的那篇會特別標示出來。
自動記住進度。 關掉瀏覽器,下次再打開,會自動跳回上次讀到的那一頁。目錄頁的按鈕也會從「開始閱讀」變成「繼續閱讀」。
三個分類,一條閱讀路徑
十篇文章不是隨便排在一起的。我們把它們分成三個章節:
- 基礎知識 — 為什麼要學 Claude Code、怎麼安裝
- 職場應用 — 用 Claude Code 管理網站、做簡報、產報告、寫部落格
- 實務技巧 — 進階設定、程式碼審查、開發環境優化
從「這是什麼」到「怎麼用在工作上」再到「怎麼用得更深」,讀者跟著目錄讀下去,就是一條從入門到進階的路徑。
這個順序是刻意設計的。我們發現,很多讀者對 Claude Code 感興趣,但不知道從哪裡開始。給他一份排好順序的閱讀清單,比丟十個連結給他有用得多。
發佈一本電子書,只需要一句話
對我們來說,這個電子書系統最有價值的地方,是它的管理流程幾乎沒有成本。
我只要跟 Claude Code 說有哪些文章要把它變成是書的內容,並請他自己幫我分類;如果要修改的話,我就直接口頭跟他講哪些文章要歸類於哪個分類底下,全部都可以用自然語言完成。
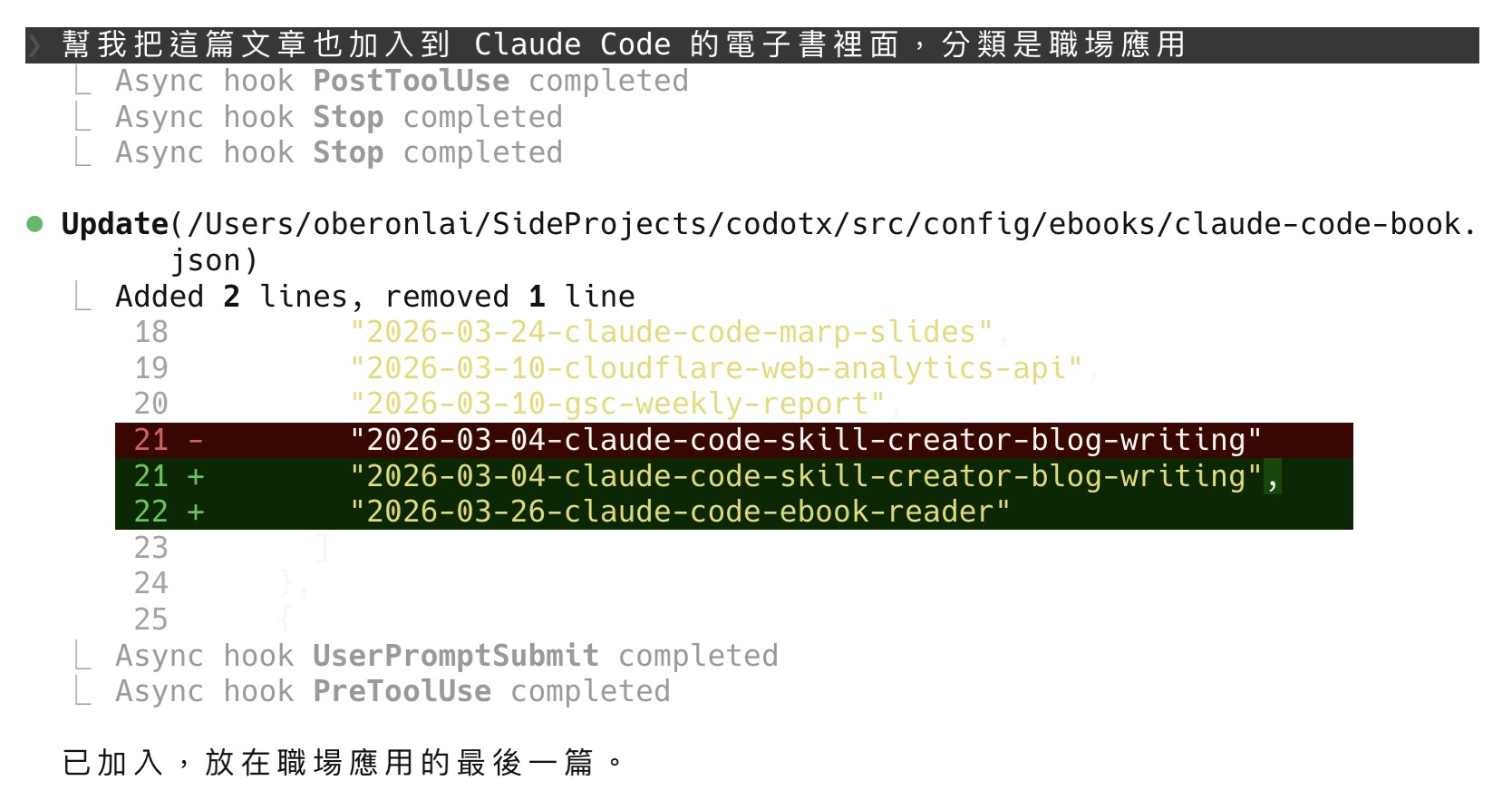
更重要的是,電子書裡的內容跟原本的文章是同一份。我們更新了某篇文章的內容,電子書裡的那一章也會自動更新。不需要另外維護兩份內容,不會出現「文章改了但電子書忘了更新」的問題。
目錄頁會自動計算收錄了幾篇文章、總共多少字、預估閱讀時間。這些數字不需要手動更新,加了新文章之後它自己會算。
這套系統也不限於 Claude Code 這個主題。如果未來我們寫了另一個系列的文章——比如 WordPress 開發實戰——只要建立一份新的文章清單,就會自動產生另一本電子書,擁有完全相同的閱讀體驗。
從十篇文章到一本書
回頭看這件事,技術上的實作其實不是重點。重點是:我們把十篇各自獨立的文章,變成了一個有結構、有順序、有連貫閱讀體驗的產品。
讀者不需要在十個頁面之間跳來跳去。他打開這本書,從第一頁開始讀,隨時可以放下,下次回來繼續。讀完一個章節,自然接上下一個章節。就像讀一本真正的書。
而我們要做的,就是持續寫文章,然後把新文章的名字加進清單裡。
電子書會自己長大。
常見問題
電子書可以離線閱讀嗎?
目前不行,需要網路連線才能開啟。但只要頁面載入完成,閱讀過程中斷網也不會影響翻頁和設定操作。
手機上怎麼翻頁?
點螢幕右側是下一頁,左側是上一頁。也可以左右滑動。進入閱讀器時會有提示。
閱讀進度會自動儲存嗎?
會。關掉瀏覽器後再次開啟,會自動跳回上次讀到的頁面。目錄頁的按鈕也會從「開始閱讀」變成「繼續閱讀」。
可以調整閱讀的字體大小嗎?
可以。點右上角的設定按鈕,能調整文字大小、行高、背景顏色(白色、米色、深色)和字型。設定會自動記住。
文章更新後,電子書的內容會同步嗎?
會。電子書的內容跟原始文章是同一份,文章更新後重新部署就會自動同步,不需要額外維護。
我可以把電子書分享給朋友嗎?
可以。目錄頁右上角和閱讀器的設定面板裡都有分享按鈕。讀完最後一頁也會出現分享提示。
我為什麼不再用 IDE,改在終端機裡開發
第 18 篇,共 21 篇我把 IDE 關掉了。現在打開電腦,只開 Warp 終端機,整天的開發工作都在裡面完成。
這不是為了追求極簡或懷舊。原因很單純:當 AI 寫程式的能力越來越強,我親手看程式碼的時間越來越少,那個佔據螢幕 80% 面積的程式碼編輯視窗,開始顯得多餘。
開發工具的使用歷程
在 AI 時代前,我都是使用 PhpStorm。PHPStorm 確實順手——跳到函式定義、儲存時自動格式化和檢查,這些功能讓開發效率提升不少。
進入 AI 時代後,我用了 Cursor 好幾個月。自動補全和聊天介面加速了不少開發流程。但用了一段時間,我發現自己還是需要理解程式碼的能力,最後回到 PHPStorm 搭配 Claude Code 的組合。
後來也試過 Google 的 Antigravity。除了免費額度以外,用起來跟 VS Code 差不多。直到某天我打開系統監控,發現 Antigravity 的記憶體佔用竟然到了 40 幾 GB。
40 幾 GB,只為了一個程式碼編輯器。
程式碼視窗還重要嗎?
這讓我開始重新思考一個問題:傳統 IDE 的設計核心是「程式碼」。整個介面以程式碼編輯器為主體,側邊欄、終端機、除錯面板都是輔助角色。
但我現在的開發流程已經變了。大部分時間我在跟 Claude Code 對話,描述需求、確認方向、審查它產出的結果。真正需要自己打開檔案逐行閱讀的時候,一天可能不到三成。
既然主要的工作模式是「對話 + 指令」,那為什麼不直接在終端機裡做?
改用 Warp 之後的工作流程
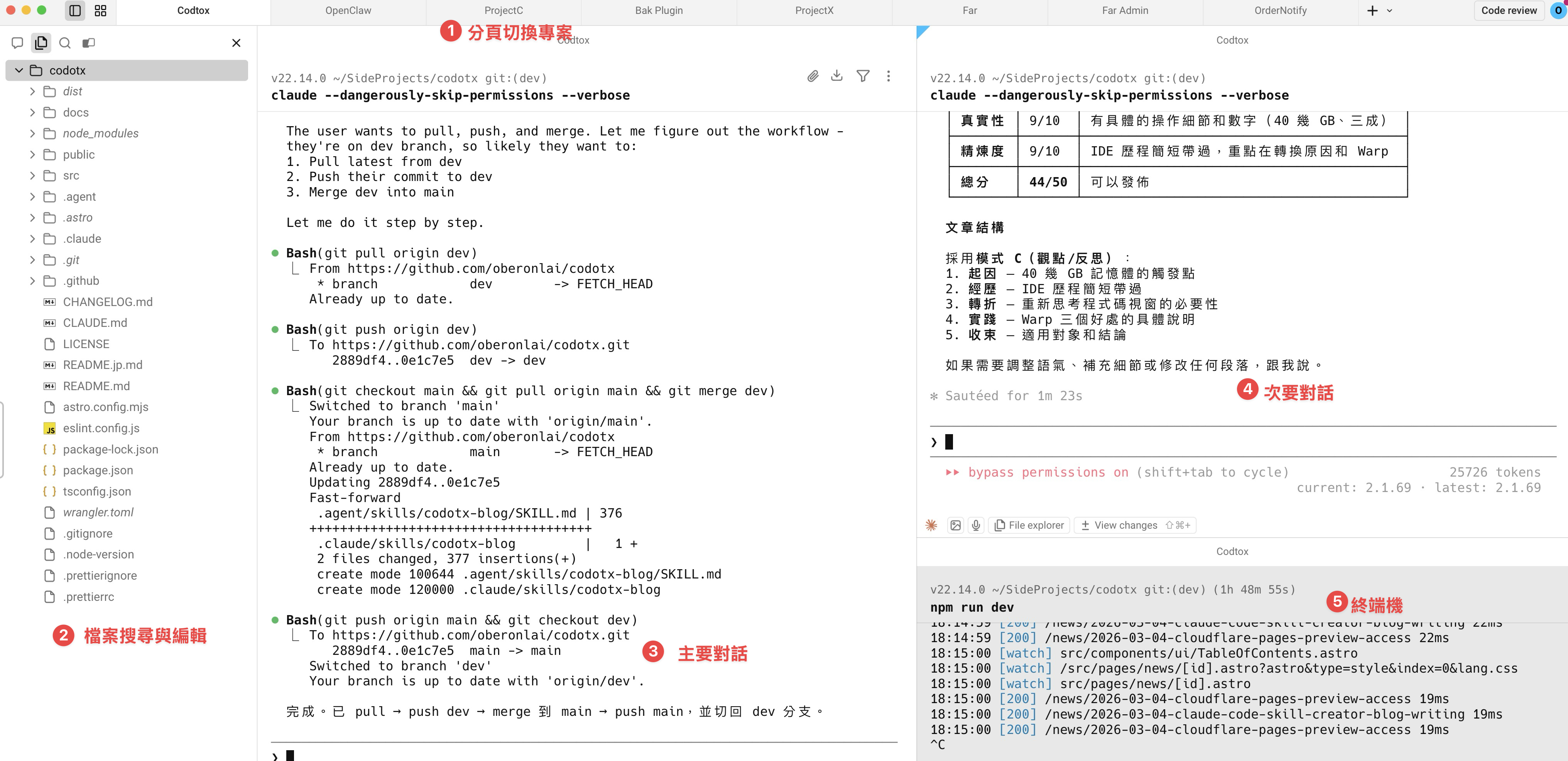
我選了 Warp 作為主力終端機。用了幾週下來,整理出三個讓我回不去 IDE 的原因。
多專案管理靠分頁就搞定
我同時在跑好幾個專案。在 Warp 裡,每個專案就是一個 Tab。早上開工時,Warp 會把我開過的專案分頁都暫存起來,只要一啟動時,就是所有我目前手邊正在進行中的專案,每個 Tab 直接切到對應的專案目錄。要切換專案,Command + 數字鍵就到了。
不用像以前那樣開好幾個 IDE 視窗,每個視窗吃掉一大塊記憶體。
視窗分割讓對話和操作並行
Command + D 就能分割畫面。我常用的配置是左邊跑 Claude Code,右邊開一個終端機執行指令。如果需要同時監看 log 或跑測試,再切一個小視窗出來。
這跟 IDE 裡開 Terminal 的體驗完全不同。在 IDE 裡,終端機是被塞在底部的附屬品;在 Warp 裡,終端機就是主角,每個分割視窗都是平等的。我可以根據當下的需求,自由調整每個視窗的比例和用途。
檔案操作也不缺
真的需要瀏覽檔案結構的時候,Warp 左側也有目錄面板,點選就能開啟檔案。雖然不像 IDE 那樣有語法高亮和智慧提示,但對於偶爾需要確認檔案內容的場景來說夠用了。
這套做法適合誰
我不會說每個開發者都該丟掉 IDE。如果你的工作需要大量手寫程式碼、頻繁使用重構工具、依賴型別檢查和自動補全,IDE 依然是最好的選擇。
但如果你跟我一樣,日常開發有一大半時間在跟 AI 協作——描述需求、審查產出、下指令執行——那 IDE 裡那個大大的程式碼視窗,可能真的不是你最需要的東西。
Warp 的介面設計剛好反映了這個轉變:它以 AI 對話為主體,終端機操作為輔助。當你的工作流程本來就是「對話 + 指令」,這樣的配置比 IDE 順手得多。
幫 Claude Code 裝上 LSP:從文字搜尋升級到語意導航
第 19 篇,共 21 篇我們團隊日常開發都用 Claude Code 作為 AI 程式助手。一般情況下它靠 Grep 和 Glob 搜尋檔案,對小專案來說夠用,但專案一大,每次找定義或追引用都要翻好幾輪文字搜尋,效率明顯下降。
後來發現 Claude Code 從 v2.0.74 開始支援 LSP(Language Server Protocol),裝上之後它就像拿到了 IDE 的「程式碼地圖」——跳轉定義、查引用、看型別,都是毫秒級回應。根據社群的測試數據,查詢速度從原本的 45 秒降到 50ms,快了將近 900 倍。
這篇整理我們實際安裝的過程,涵蓋 TypeScript / JavaScript、Python、PHP 三種我們最常用的語言。
LSP 是什麼?為什麼 Claude Code 需要它?
LSP 是微軟提出的通訊協定,讓編輯器和語言伺服器之間有統一的溝通方式。VS Code、Neovim 這些編輯器的「跳轉定義」「查找引用」功能,背後都是 LSP 在運作。
沒有 LSP 的 Claude Code 只能靠文字比對來理解程式碼。問它「這個函式定義在哪」,它得用 Grep 掃一遍檔案,碰到同名變數或字串就容易搞混。裝上 LSP 之後,它能直接跟語言伺服器溝通,拿到精確的型別資訊和符號位置。
裝完 LSP 後 Claude Code 會多出一個 LSP 工具,支援以下操作:
- goToDefinition — 跳轉到符號定義
- findReferences — 查找所有引用
- hover — 取得型別資訊和文件說明
- documentSymbol — 列出檔案中的所有符號
- workspaceSymbol — 跨檔案搜尋符號
安裝前的準備
Claude Code 的 LSP 透過 Plugin 系統運作。安裝流程分兩步:先在系統上裝好語言伺服器的執行檔,再透過 Claude Code 的 /plugin 指令從官方市集 claude-plugins-official 安裝對應的 Plugin。
確認你的 Claude Code 版本在 v2.0.74 以上:
claude --versionTypeScript / JavaScript
TypeScript 用的是 vtsls(Vue/TypeScript Language Server),支援 .ts、.tsx、.js、.jsx、.mts、.cts 等副檔名。
安裝語言伺服器
npm install -g @vtsls/language-server typescript用 pnpm 或 bun 也可以:
# pnpm
pnpm install -g @vtsls/language-server typescript
# bun
bun install -g @vtsls/language-server typescript安裝 Claude Code Plugin
在 Claude Code 中輸入:
/plugin install typescript-lsp@claude-plugins-official重啟 Claude Code 讓 LSP 伺服器生效。
Python
Python 用的是 Pyright,微軟開發的高效能靜態型別檢查器。
安裝語言伺服器
npm install -g pyright安裝 Claude Code Plugin
/plugin install pyright@claude-plugins-official重啟 Claude Code。
PHP
PHP 用的是 Intelephense,高效能的 PHP 語言伺服器,支援程式碼補全、定義跳轉、引用查找和即時診斷。
安裝語言伺服器
npm install -g intelephense安裝 Claude Code Plugin
/plugin install php-lsp@claude-plugins-official重啟 Claude Code。
驗證 LSP 是否正常運作
裝完之後怎麼確認有沒有成功?兩個步驟。
檢查 Plugin 狀態
在 Claude Code 中輸入 /plugin,切到 Installed 頁籤,確認你安裝的 Plugin 顯示 Status: enabled。
這是最常見的坑——Plugin 裝了但沒有啟用。如果狀態顯示 disabled,手動啟用:
claude plugin enable typescript-lsp實際測試 LSP 工具
請 Claude Code 對一個具體的檔案執行 LSP 操作。例如在 TypeScript 專案中:
幫我用 LSP 的 hover 看一下 src/i18n/translations.ts 第 527 行第 14 個字元的型別資訊如果 LSP 正常運作,你會看到回傳的型別定義,而不是「No LSP server available」的錯誤訊息。
也可以試試 documentSymbol,請 Claude Code 列出某個檔案的所有符號:
用 LSP 列出 src/i18n/translations.ts 的所有符號正常的話會看到檔案中所有變數、函式、屬性的清單和行號。
常見問題排查
「No LSP server available」
最常見的原因有三個:
- 語言伺服器沒裝好 — 用
which vtsls、which pyright、which intelephense確認執行檔在 PATH 中 - Plugin 沒啟用 —
/plugin檢查狀態,手動 enable - 沒重啟 — LSP 伺服器需要在 Claude Code 啟動時載入,裝完 Plugin 後一定要重啟
環境變數 ENABLE_LSP_TOOL
部分版本的 Claude Code 需要手動啟用 LSP 工具。如果重啟後還是看不到 LSP 工具,在 ~/.zshrc 加上:
export ENABLE_LSP_TOOL=1或是啟動時直接帶:
ENABLE_LSP_TOOL=1 claudePlugin Errors 頁籤
/plugin 介面有個 Errors 頁籤,如果 LSP 伺服器啟動失敗,錯誤訊息會顯示在這裡。常見的錯誤是「Executable not found in $PATH」,代表語言伺服器的執行檔沒裝好或路徑不對。
實際開發中會觸發 LSP 的場景
裝上 LSP 之後,不需要特別下指令叫 Claude Code 去用它。在日常對話中描述需求,它會自己判斷該不該呼叫 LSP。以下是我們實際遇過的幾種情境。
改名重構:改一個變數,所有引用一起改
「幫我把
menuData這個變數改名成navigationData,所有引用的地方都要改到。」
沒有 LSP 的時候,Claude Code 會用 Grep 搜 menuData,但可能漏掉解構賦值的寫法,或是誤改到註解裡剛好出現的同名字串。有了 LSP,它會先用 findReferences 拿到所有真正引用到這個變數的位置,再逐一修改。
追蹤函式定義:這個函式到底在哪裡定義的?
「
sanitize_text_field這個函式是 WordPress 內建的還是我們自己寫的?幫我找到它的定義。」
Claude Code 會用 goToDefinition 跳到函式定義的位置。如果是專案內的函式,直接跳過去;如果是第三方套件或框架內建的,LSP 也會指向 node_modules 或 vendor 裡的原始碼。比起 Grep 搜出一堆 sanitize_text_field 的呼叫處,精確太多。
理解型別:這個參數到底接受什麼?
「
getCollection的回傳值是什麼型別?」
Claude Code 用 hover 查詢,直接拿到完整的型別簽名。在 TypeScript 專案裡特別有用——泛型嵌套幾層之後,光讀原始碼很難直接看出展開後的型別。LSP 會幫你把推導結果算好。
檢查誰在用這個 API:改動前的影響範圍評估
「我想改
CategoryNavigation元件的 props 介面,幫我看看哪些地方有用到這個元件。」
findReferences 會列出所有引入和使用這個元件的檔案與行號。這比 Grep 搜元件名稱可靠,因為 Grep 會把 import 語句、註解、字串裡的提及全部撈出來,LSP 只回傳真正的程式碼引用。
掌握檔案結構:這個檔案裡有哪些函式和變數?
「列出
src/i18n/utils.ts裡面所有 export 的函式。」
Claude Code 用 documentSymbol 取得檔案的完整符號清單,包含函式、變數、介面、型別別名,附帶行號。在閱讀不熟悉的程式碼時,這比從頭讀到尾快很多。
跨檔案搜尋:專案裡有沒有某個 class 或 function?
「專案裡有沒有叫
Pagination的元件或型別?」
workspaceSymbol 會在整個專案範圍內搜尋符號名稱。跟 Glob 搜檔名不同,它搜的是程式碼裡的符號定義——同一個檔案裡定義了多個 class 或 function,它都能找到。
WordPress / PHP 開發:Hook 和 Filter 的追蹤
「
woocommerce_checkout_order_processed這個 action hook 在我們的外掛裡哪些地方有掛載?」
PHP 專案裝了 Intelephense 之後,findReferences 能精確找到 add_action 和 add_filter 中引用到的 hook 名稱,不會像純文字搜尋那樣把 do_action 的觸發點和 add_action 的掛載點混在一起。
重點整理
這些場景有個共通點:你不需要跟 Claude Code 說「請用 LSP」。正常描述你的需求,它會根據任務性質自動選擇用 Grep 還是 LSP。型別查詢、定義跳轉、引用追蹤這類需要語意理解的操作,它會優先走 LSP;純文字內容搜尋(例如找某段中文翻譯),它還是會用 Grep。
裝完 LSP 等於是讓 Claude Code 多了一組更精確的工具,它會自己判斷什麼時候該用。
參考資源
- Claude Code Plugins Reference(官方文件)
- Discover and Install Prebuilt Plugins(官方文件)
- claude-plugins-official(官方 Plugin 市集)
- Claude Code LSP: Complete Setup Guide for All 11 Languages
- The 2-Minute Claude Code Upgrade You’re Probably Missing: LSP
- Enable LSP tool to connect to installed language servers(GitHub Issue #15619)
用 Claude Code 設計 AI 程式碼審查機制:以 Payload CMS 為例
第 20 篇,共 21 篇用 AI 寫程式碼的時候,有一個容易被忽略的問題:AI 很擅長把功能做出來,但它不一定了解你用的工具有哪些「該注意但沒注意就會出事」的地方。
每個開源框架都有自己的一套使用建議。有些寫在官方文件的安全性章節,有些藏在效能調校的頁面,有些是社群踩過坑之後整理出來的。這些建議通常不影響功能是否能跑,但會影響上線之後會不會出問題 — 資料被未授權的人看到、頁面越來越慢、資料庫改版時資料不見了。
問題是,這些建議散落在不同地方,就算是有經驗的開發者也不一定每次都記得。AI 更不會主動幫你對照這些清單。
我們團隊一直有在使用 Claude Code 的 Command、Agent、Skill 三層架構來擴充開發流程,剛好可以用來解決這個問題:把框架的使用建議整理成結構化的檢查清單,讓 AI 寫完程式碼之後,自動根據這份清單逐項檢查。
這篇文章分享我們怎麼設計這套機制。我們用 Payload CMS(一個 Node.js 的開源後端框架)作為實際案例,但整套設計方法可以套用到任何框架或工具。
第一步:搞清楚你用的工具有哪些「該注意的事」
第一件要做的事不是寫程式,而是好好讀一遍你用的框架的官方文件。特別是跟上線部署、安全性、效能相關的章節。大部分成熟的開源工具都會把這些注意事項寫出來,只是散落在不同頁面,需要自己整理。
以 Payload CMS 為例,我們花了一些時間把官方文件翻過一輪,整理出三個需要特別注意的面向:
安全性 — Payload 在伺服器端提供了一組內部 API,方便開發者直接操作資料庫。但這組 API 有一個特性:預設不會檢查使用者的權限(官方文件有明確說明)。如果開發者沒有手動開啟權限檢查,任何人都可能透過這組 API 讀到不該看到的資料。另外,官方在 Preventing Abuse 和 Deployment 頁面分別列出了防暴力破解、跨站請求偽造防護、查詢深度限制等上線前該設定的項目。
效能 — Payload 在查詢資料時,可以自動帶出關聯的資料(例如查文章時順便帶出作者資訊)。這個功能很方便,但每多帶一層關聯,就多一輪資料庫查詢。官方文件(Depth、Select、Indexes)建議開發者明確控制要帶幾層、只取需要的欄位、對常查詢的欄位建立索引。開發時資料少感覺不出差異,上線後資料量一大就會明顯變慢。
資料庫變更安全 — 開發過程中經常需要修改資料結構(加欄位、改名稱、刪欄位)。Payload 處理欄位改名的方式比較特別:它不是直接改名,而是先把舊欄位刪掉再建一個新的(Migrations 文件)。這代表舊欄位裡的資料會直接消失。官方建議的做法是分階段處理:先加新欄位、把資料搬過去、確認沒問題、最後才刪舊欄位。
每個框架會有不同的注意事項。重點是從官方文件出發,有系統地整理,而不是等出了問題才回頭找原因。
第二步:決定審查的粒度和觸發時機
找出風險維度之後,下一個決定是:要做幾個審查指令?什麼時候觸發?
我們一開始的直覺是做一個大指令,把所有檢查項目塞在一起。但實際用了幾次之後發現兩個問題:第一,每次都跑全部檢查太慢也太浪費 token;第二,migration 的風險等級遠高於效能問題,混在一起報告時容易忽略真正危險的項目。
最後我們拆成兩類,共五個指令:
日常開發用 — commit 前跑:
/payload-check:自動偵測改了哪些檔案,只跑需要的審查/payload-review:單獨跑安全性審查/payload-perf:單獨跑效能審查/payload-migrate:單獨跑 migration 審查
定期健檢用 — 每週跑:
/payload-audit:三個維度同時掃描整個 codebase
拆開的好處是日常開發不會被完整審查拖慢。改了一個 hook 就只跑安全性和效能審查,不需要等 migration 審查跑完。/payload-check 負責自動判斷該跑哪些,開發者不用記。
觸發時機我們選在 commit 之前。原因很實際:commit 前發現問題可以直接改,改完一起 commit,git history 乾淨。如果 commit 之後才跑,發現問題還要再改再 commit,多出一堆 fix commit。
第三步:用三層架構把知識和流程分開
這是整個設計中最關鍵的決定。Claude Code 提供三種機制:Command、Agent、Skill。
| 層級 | 機制 | 放什麼 |
|---|---|---|
| Command | .claude/commands/*.md | 入口點。接收使用者指令,決定啟動哪個 Agent |
| Agent | .claude/agents/*.md | 執行者。定義審查流程:收集 diff → 讀取知識 → 逐項檢查 → 產出報告 |
| Skill | .claude/skills/*/SKILL.md | 知識庫。完整的 checklist、正確 / 錯誤程式碼範例、官方文件對應 |
為什麼要分三層?因為知識和流程的更新頻率不同。
Skill 裡的 checklist 會隨著框架版本更新而變(Payload v3 和 v4 的最佳實踐不一樣),但審查流程(收集 diff → 讀知識 → 檢查 → 報告)基本不會變。如果把 checklist 直接寫在 Agent 裡面,每次更新 checklist 都要同時改 Agent,改錯了連流程都壞掉。
分開之後,更新 checklist 只需要改 Skill 檔案,Agent 和 Command 完全不用動。
Command:保持精簡
Command 只需要一句話說明用途,加上指定啟動哪個 Agent。以 /payload-review 為例:
Run a Payload CMS SaaS security review on the current git diff.
Launch the `payload-saas-reviewer` agent to execute the review.不要在 Command 裡寫具體的檢查步驟。Command 是入口,不是說明書。
Agent:定義流程,不存知識
Agent 定義審查的執行流程和輸出格式,但具體要檢查什麼則從 Skill 讀取。
## Workflow
1. Gather context — Run `git diff --staged` and `git diff`.
2. Load knowledge — Read `.claude/skills/payload-saas-review/SKILL.md`.
3. Identify scope — Determine which file types changed.
4. Read surrounding code — Never review in isolation.
5. Apply checklist — Work through each category in SKILL.md, CRITICAL first.
6. Report findings — Only report issues with >80% confidence.關鍵是第 2 步:Agent 被指示去讀 Skill 檔案。這樣 Skill 更新了,Agent 下次執行自動就會用新的 checklist。
Agent 裡還有一個重要的設計:Noise Filter。我們要求 Agent 只報告信心度超過 80% 的問題,同類問題要合併(「3 個 collection 缺少 tenant filter」而不是 3 個獨立項目)。沒有這個過濾,審查報告會充斥大量低信心度的噪音,開發者很快就會忽略所有警告。
Skill:完整的知識庫
Skill 是整套機制的核心,內容最多也最重要。一份好的 Skill 檔案需要包含:
1. 分級的 Checklist
按嚴重程度分級:CRITICAL(必須封鎖合併)、HIGH(合併前修復)、MEDIUM(後續 PR 處理)、LOW(記錄備忘)。
不分級的 checklist 等於沒有 checklist — 開發者不知道哪些問題要優先處理。
2. 正確和錯誤的程式碼範例
每個檢查項目都配一組「錯誤寫法 → 正確寫法」的程式碼對照。光是描述規則不夠,Agent 需要具體的 pattern 才能準確辨識程式碼中的問題。
以 Payload 的 depth 控制為例:
// ❌ 沒有設定 depth,使用預設值,觸發不必要的關聯查詢
const posts = await payload.find({
collection: 'posts',
})
// ✅ 明確設定最低必要的 depth,搭配 select 只取需要的欄位
const posts = await payload.find({
collection: 'posts',
depth: 1,
select: { title: true, slug: true, category: true },
})3. 官方文件對應
每條規則標註出處,例如「根據 Preventing Abuse 文件,maxLoginAttempts 必須設定」。這讓開發者可以自己去查原始文件,也讓 Agent 的建議更有說服力。
第四步:設計整合指令和全 Codebase 審計
日常開發有三個獨立的審查指令,但每次都要想「這次該跑哪個」很煩。所以我們做了 /payload-check — 它看 git diff 改了哪些檔案,自動決定該啟動哪些 Agent。
改了 migrations/ 或 collection 欄位定義 → 啟動 migration Agent。改了 payload.find() 相關的程式碼 → 啟動效能 Agent。改了 access control 或 auth 邏輯 → 啟動安全 Agent。多個維度同時觸發就並行跑。
另外一個問題是:diff 審查只看「這次改了什麼」,不會抓到已經存在的問題。三個月前寫的 collection 沒加 index,上週部署時忘記設定 maxLoginAttempts,這些不會出現在任何一次 diff 裡面。
所以我們做了 /payload-audit,同時啟動三個 Agent 掃描整個 codebase,產出一份按嚴重程度排序的完整報告。這個指令的 token 消耗較高(大約是單一 diff 審查的 5-10 倍),不建議每天跑,每週一次或上線前跑比較合理。
最終的開發流程:
寫完功能
↓
/payload-check ← 自動偵測,只跑需要的審查
↓
有問題 → 修完再跑一次
沒問題 ↓
git commit → push每週再跑一次 /payload-audit 做全面健檢。
第五步:根據專案類型設計你自己的 Checklist
到目前為止,我們的範例都是 Payload CMS 的 SaaS 平台,安全審查重點放在 tenant 隔離和計費邏輯。但同樣的三層架構可以適用於任何專案類型。
你需要做的是:根據你的專案類型,設計對應的 Skill 檔案。Agent 和 Command 的結構幾乎不需要改,因為審查流程是通用的(收集變更 → 讀知識 → 逐項檢查 → 產出報告),只有知識庫的內容需要替換。
以下是幾種不同專案類型的 checklist 方向,供你參考。
電商網站
安全性的重點從 tenant 隔離轉移到交易安全:
- 訂單存取控制 — 買家只能查看自己的訂單,API 層級是否有做
user.id === order.customer的驗證 - 價格信任邊界 — 結帳時的價格是從資料庫讀的還是前端傳來的?前端傳來的價格不能直接信任
- 庫存 Race Condition — 兩個人同時購買最後一件商品,有沒有用 transaction 或 optimistic locking 處理
- 付款 Webhook Idempotency — 金流通知重送時不能重複建立訂單或重複扣庫存
效能的重點在商品查詢和購物車:
- 商品列表查詢 — 有沒有對分類、價格範圍、上架狀態加 index
- 購物車計算 — 是每次都從 DB 撈完整商品資料,還是只取價格和庫存
- 圖片處理 — 商品圖片有沒有做 resize 和 CDN 快取
內容管理網站
安全性聚焦在發布權限和公開 API:
- 多層審核 — 編輯、審核者、管理員的權限邊界是否清楚
- 草稿洩漏 — 未發布的草稿有沒有透過 API 曝光
- 公開 API 的 Rate Limiting — 沒登入的請求有沒有做頻率限制
- 檔案上傳 — 有沒有限制大小、格式、儲存路徑
效能重點在內容查詢和快取:
- 公開頁面的快取 — 首頁、文章列表這類不常變動的頁面有沒有做快取
- Rich Text 處理 — Lexical JSON 是在伺服器端轉 HTML 還是丟給前端處理
- SEO 欄位 — sitemap 產生是即時運算還是定期快取
多語系網站
額外需要關注的維度:
- 翻譯完整性 — 主語言有的欄位,其他語言是否也有對應內容
- Locale Fallback — 缺少翻譯時的降級邏輯是否正確
- URL 結構 — hreflang 標籤和實際路由是否對應
設計 Checklist 的原則
不管是哪種專案類型,設計 checklist 時有幾個原則:
- 從官方文件出發,不要靠直覺。每個框架的 production / security / performance 章節通常就有 80% 的答案
- 按嚴重程度分級。不分級的 checklist 就是一堆平等的待辦事項,開發者不知道哪些真的危險
- 附上程式碼範例。Agent 需要具體的 pattern 來辨識問題,光靠文字描述不夠精準
- 只放 AI 容易犯的錯。人類開發者會犯的低級錯誤(拼錯變數名)不需要放進來,那是 linter 的工作
完整的檔案結構
最後整理一下完整的檔案結構,方便你照著建:
.claude/
├── commands/
│ ├── payload-check.md # 入口:自動偵測 + 啟動對應 Agent
│ ├── payload-review.md # 入口:啟動安全 Agent
│ ├── payload-perf.md # 入口:啟動效能 Agent
│ ├── payload-migrate.md # 入口:啟動 migration Agent
│ └── payload-audit.md # 入口:三個 Agent 並行掃全 codebase
├── agents/
│ ├── payload-saas-reviewer.md # 安全審查流程
│ ├── payload-performance-reviewer.md # 效能審查流程
│ └── payload-migration-reviewer.md # Migration 審查流程
└── skills/
├── payload-saas-review/
│ └── SKILL.md # 安全知識庫(checklist + 範例)
├── payload-performance-review/
│ └── SKILL.md # 效能知識庫
└── payload-migration-review/
└── SKILL.md # Migration 知識庫如果你要替換成自己的框架,把 payload 換成你的框架名稱,修改 Skill 裡的 checklist 和程式碼範例就可以了。Agent 的 workflow 和 Command 的入口邏輯基本上可以直接複用。
設計完之後的感想
這套機制上線大約兩週,我們的感受是:它不會取代人工 code review,但確實補上了一個盲區。AI 寫程式碼的速度很快,但速度帶來的風險是容易略過框架特有的注意事項。這些注意事項寫在官方文件裡,但分散在各個頁面,就算是人類開發者也不一定每次都記得。
把這些知識整理成結構化的 checklist,讓 AI 在產出程式碼之後自己檢查一遍,比起每次人工逐項確認高效得多。發現的問題在 commit 前就修掉,不會帶到生產環境才爆炸。
如果你也在用 AI 輔助開發,不管是什麼框架,花幾個小時把官方文件的最佳實踐整理成 Skill 檔案,設計對應的 Agent 和 Command,長期來看絕對值得。
Claude Code 技巧:跨專案 Session 搜尋,0.1 秒找到任何對話
第 21 篇,共 21 篇Claude Code 的 session 搜尋沒有內建的跨專案方案。我們用一條 shell 指令,在 0.1 秒內掃完 766MB、橫跨 38 個專案的對話紀錄,找到任何一個命名過的 session。這篇記錄從發現問題到打造工具的完整過程。
問題的起點:跨專案的知識孤島
我們同時在維護多個專案——企業官網、旅遊平台、WordPress 外掛、SaaS 產品。每個專案都有自己的 Claude Code 對話紀錄,每天累積幾十到上百回合的對話。
一開始,當 A 專案需要用到 B 專案的經驗時,我的做法是這樣:先請 Claude Code 把當前的需求和解法整理成一份文件,存到專案裡。然後切換到另一個專案,把那份文件的絕對路徑貼給新的 Claude Code session,請它讀取後繼續開發。
這個流程有幾個問題。
第一,每次都要「主動」整理。忘了整理就等於沒做過。第二,整理出來的文件是靜態的摘要,丟失了對話中的來回推敲和關鍵決策脈絡。第三,跨專案一多,光是管理這些中繼文件就變成負擔。
某天我在想——Claude Code 的每一次對話不都完整保留在本機嗎?與其手動整理文件當作跨專案的橋樑,不如直接去翻歷史 session。
先搞清楚 Session 存在哪裡
Claude Code 的對話紀錄並不像你想像的那麼直覺。打開 ~/.claude/ 目錄,你會看到兩個關鍵位置:
~/.claude/sessions/ —— 存放正在執行的 session 的 JSON 元資料。每個檔案以 PID(Process ID)命名,內容長這樣:
{
"pid": 15064,
"sessionId": "39029d88-07fe-4752-ac2d-f17b13800bcf",
"cwd": "/Users/user/SideProjects/codotx",
"startedAt": 1775002864872
}這裡有 session ID 和工作目錄。但問題是,這些檔案只在 session 執行期間存在,關掉就沒了。
~/.claude/projects/ —— 這才是重頭戲。每個專案的工作目錄會被轉換成資料夾名稱(把 / 換成 -),例如 /Users/user/SideProjects/codotx 變成 -Users-user-SideProjects-codotx。每個對話紀錄是一個 JSONL 檔案,以 session UUID 命名。
我們的專案目錄下有 899 個 JSONL 檔案,總共 766MB。每個檔案都是完整的對話紀錄——使用者訊息、助手回覆、工具呼叫,全部都在裡面。
那 Session 名稱呢?
用 /rename 指令幫 session 命名之後,名稱存在哪裡?這一步花了點時間才搞清楚。
活躍的 session 名稱會出現在 ~/.claude/sessions/<pid>.json 裡。但前面說了,這些檔案會隨 session 結束消失。
歷史 session 的名稱藏在 JSONL 對話紀錄裡。當你執行 /rename my-session 時,Claude Code 會在 JSONL 中寫入一條系統訊息:
{
"type": "system",
"subtype": "local_command",
"content": "<local-command-stdout>Session renamed to: my-session</local-command-stdout>",
"sessionId": "39029d88-...",
"cwd": "/Users/user/SideProjects/codotx",
"timestamp": "2026-03-30T04:40:27.526Z"
}這條訊息同時包含了 session 名稱、ID、專案路徑和時間戳。換句話說,只要能從所有 JSONL 中把這些紀錄撈出來,就能建出完整的 session 索引。
用一條指令建索引
知道資料結構之後,解法變得很直接。ripgrep 是我們開發環境的標配工具,掃描大量文字檔是它的強項。
rg --no-filename 'Session renamed to:' ~/.claude/projects/ \
| jq -r '[.sessionId, .cwd, (.content | capture("Session renamed to: (?<name>.+)</local") | .name), .timestamp] | @tsv' \
| sort -t$'\t' -k4 -r \
| awk -F'\t' '!seen[$1]++'這條指令做了四件事:
- ripgrep 掃描所有 JSONL,找到包含
Session renamed to:的行 - jq 從 JSON 中擷取 session ID、專案路徑、名稱和時間戳
- sort 按時間倒序排列
- awk 去除重複(同一個 session 可能被 rename 多次,只取最新的名稱)
766MB 的資料,0.1 秒跑完。
輸出結果長這樣:
SESSION NAME PROJECT DATE
──────────── ─────── ────
how-to-find-session-quickly codotx 2026-04-01
setup-reverse-proxy codotx 2026-03-31
update-dns-config codotx 2026-03-31
post-claude-memory codotx 2026-03-31
update-ga-env codotx 2026-03-30
debug-backup-vendor codotx 2026-03-30
外掛還原除錯 codotx 2026-03-27
修改選單結構 codotx 2026-03-2638 個專案、49 個命名 session,一目了然。
包裝成 Shell 腳本
光有一條指令還不夠好用。我們在 ~/.claude/ 底下自己建了一個 scripts/ 資料夾(這不是 Claude Code 官方的目錄,純粹是我們自己放腳本的地方),把它包裝成一個 shell 腳本 find-session.sh,支援幾種使用場景:
# 建立腳本目錄(首次使用才需要)
mkdir -p ~/.claude/scripts
# 列出所有命名 session
~/.claude/scripts/find-session.sh
# 用關鍵字搜尋
~/.claude/scripts/find-session.sh "deploy"
# 只列某個專案的 session
~/.claude/scripts/find-session.sh -p codotx
# 組合使用:在某個專案中搜 api 相關的 session
~/.claude/scripts/find-session.sh -p codotx api
# 查看特定 session 的詳細資訊
~/.claude/scripts/find-session.sh -i update-ga-env詳細資訊模式會顯示完整的 session 元資料,包括 JSONL 檔案路徑和 resume 指令:
Session: update-ga-env
ID: 5fb6323d-8330-4c36-8579-0d5376f24957
專案: /Users/user/SideProjects/codotx
時間: 2026-03-30T04:23:58.179Z
Resume: claude --resume "update-ga-env"
JSONL: ~/.claude/projects/-Users-user-SideProjects-codotx/5fb...jsonl
大小: 980K (419 行)有了 JSONL 路徑,就能直接讀取對話內容。有了 resume 指令,就能回到那個 session 繼續對話。
再包一層:做成 Skill
腳本解決了「怎麼搜」的問題,但每次還是要自己跑指令。能不能讓 Claude Code 自己知道怎麼搜?
Claude Code 的 Skill 機制就是為這種場景設計的。在 ~/.claude/skills/find-session/skill.md 裡定義一個 Skill,告訴 Claude Code 這個工具的使用方式和執行步驟:
---
name: find-session
description: 快速搜尋跨專案的 Claude Code session 對話紀錄
user_invocable: true
argument_description: "[關鍵字] 或 --info <session名稱>"
---
# Find Session:跨專案 Session 搜尋工具
直接執行腳本:
~/.claude/scripts/find-session.sh [ARGUMENTS]設定完之後,在任何專案裡都能直接用 /find-session 指令搜尋。也可以用自然語言:「幫我找之前跟 deploy 有關的對話」,Claude Code 會自動呼叫腳本。
從「整理文件」到「直接搜尋」
回到最初的問題。以前跨專案傳遞知識,流程是這樣的:
- 在 A 專案整理一份文件
- 切換到 B 專案
- 把文件路徑貼給 Claude Code
- 等它讀完再繼續
現在的流程:
- 在 B 專案說「幫我找之前 A 專案裡處理 XX 的 session」
- Claude Code 用
/find-session找到對應的 JSONL - 直接從對話紀錄中提取需要的脈絡
少了「手動整理」這個步驟,也不會因為忘記整理而丟失知識。更重要的是,JSONL 保留的是完整對話——包括試過但失敗的方案、中途的判斷轉折、最後為什麼選了某個做法。這些脈絡是摘要文件很難保留的。
幾個值得注意的細節
Session 沒命名就搜不到。 這套方案完全依賴 /rename。如果你沒有命名 session 的習慣,建議從現在開始養成。我的習慣是每做一個新任務就開一個新的 session,然後用 /rename 命名這個任務的名稱,用英文加 dash 的格式,例如 fix-deploy-error 或 integrate-payment-api。
JSONL 只增不減。 Claude Code 的對話紀錄是 append-only 的。即使你執行 /compact 壓縮 context window,磁碟上的 JSONL 不會變小。這代表搜尋的資料量會持續成長。目前 766MB 跑 0.1 秒,以 ripgrep 的效能來說,短期內不需要擔心。
不需要快取。 我一開始想說要不要建一個索引快取檔,每次搜尋從快取讀取。實測之後發現 ripgrep 直接掃全量比讀快取還快,而且不需要維護快取的更新邏輯。工程上最簡單的方案碰巧也是最快的。
常見問題
Claude Code 的 Session 對話紀錄存在哪裡?
Claude Code 的對話紀錄存放在 ~/.claude/projects/ 目錄下,依專案路徑分類。每個 session 是一個 JSONL 檔案,以 UUID 命名,包含完整的使用者訊息、助手回覆和工具呼叫紀錄。活躍中的 session 元資料則存在 ~/.claude/sessions/ 裡。
執行 /compact 會刪除 JSONL 對話紀錄嗎?
不會。/compact 只壓縮記憶體中的 context window,讓你能在不超出 token 限制的情況下繼續對話。磁碟上的 JSONL 檔案是 append-only 的,所有訊息(包括 compact 產生的摘要)都會持續追加,不會被修改或刪除。
怎麼讓 Claude Code 讀取其他專案的歷史對話?
找到目標 session 的 JSONL 檔案路徑後,可以直接請 Claude Code 讀取該檔案。或者使用 claude --resume "session名稱" 回到原本的 session 繼續對話。搭配本文介紹的 /find-session Skill,可以快速定位任何專案中的歷史對話。
想用 Claude Code 優化你的開發流程,或有跨專案協作的需求?歡迎聯絡我們,聊聊你的想法。
閱讀結束
恭喜你讀完了整本書!
覺得內容實用嗎?分享給你的朋友吧。