Claude Code Skills 打造個人化 AI 學習工具|把教學理論模組化的脈絡學習設計
AI 文章延伸
選擇平台後可直接帶入閱讀脈絡,快速整理重點、補齊盲點,並延伸到同站相關文章。
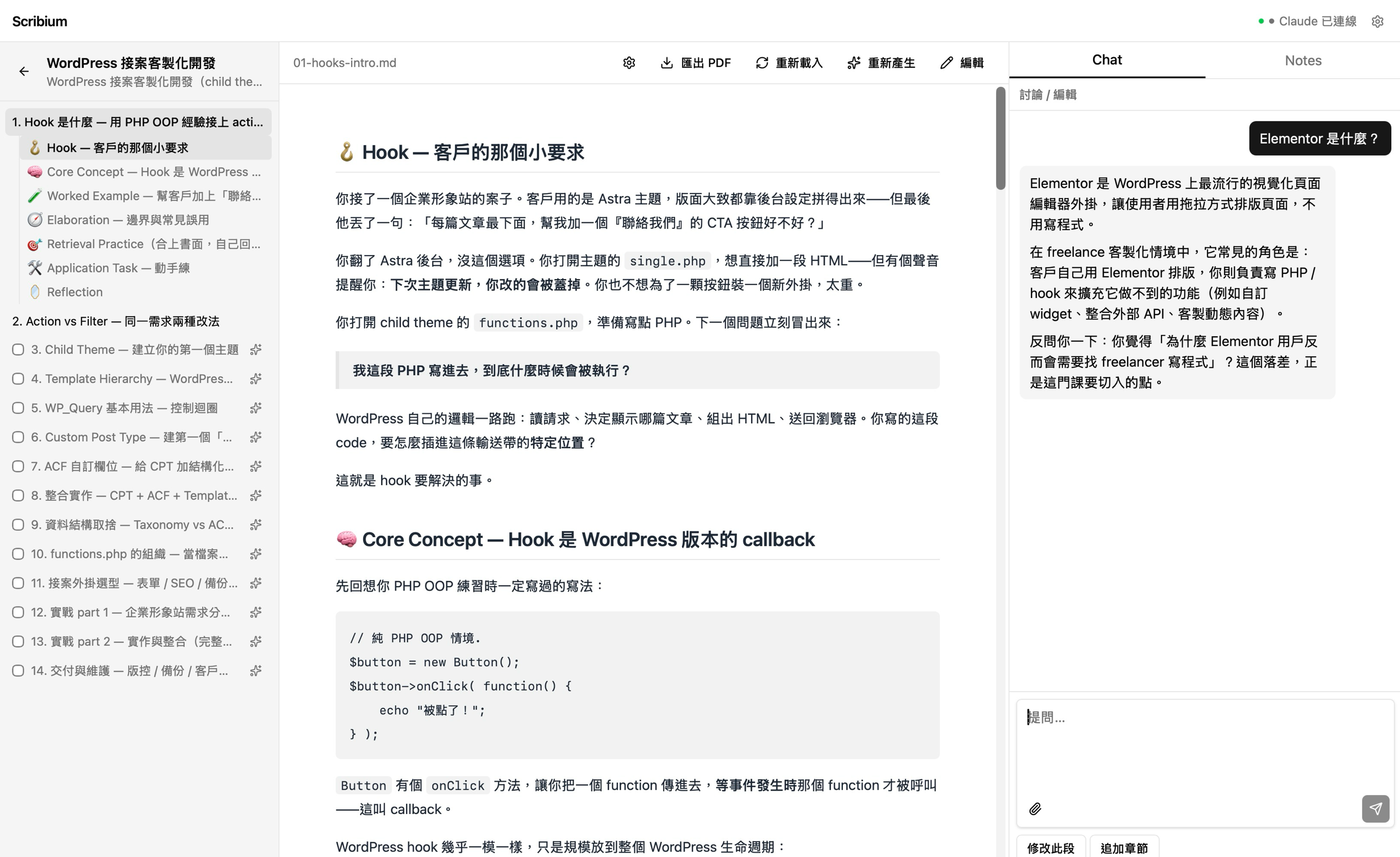
最近做了一個 AI 學習工具給自己和身邊朋友用,它跟一般線上課程最大的差別是同一個主題對兩個不同背景的人,會產出兩份完全不一樣的章節內容,我們用的不是什麼新模型,就是把 Claude Code Skills 拆成四個分工明確的學習設計階段,再用 MCP plugin 把 Claude Code 串接進 App 聊天介面,就能在 App 中直接跟 AI 對話。最大的體會是:個人化學習是讓學習者的背景脈絡從訪談、課綱到章節都被讀進去作為上下文。
一份課綱餵給所有人,是傳統課程的根本限制
市面上號稱針對每個人設計的課程都還是不夠個人化。
舉個我們最近的例子:兩個朋友都來找我們學 AI,一位是經營旅行社的老闆,想用 AI 自動產出行程文案、處理客服問答,另一位是曾在保險業界做到總經理的高階主管,退下來之後想經營個人品牌、做企業顧問,他們嘴上講的「我想學 AI」字面上是同一件事,內容完全不一樣。
旅行社朋友要的是怎麼把舊的 PDF 行程轉成多語系商品文案、怎麼讓 LINE 上的常見問題(行程細節、費用、退款)自動回覆、怎麼用 AI 處理大量客戶評價的分類整理。保險主管要的是怎麼把多年的客戶面談筆記變成可檢索的顧問知識庫、怎麼用 AI 寫深度文章建立權威感、怎麼把零散的產業洞察整理成可重複使用的提案模板。
把同一份「AI 入門課程」餵給兩個人,結果就是旅行社朋友翻到第三章還在讀「prompt 寫作的學術原理」(他只想趕快讓 LINE 自動回覆),高階主管翻到第三章已經被「圖片生成模型介紹」逼瘋(他完全不需要理解圖像模型),問題不是課程不好,是坊間課程沒辦法知道你是誰、卡在哪、要去哪。
我們之前在 AI 焦慮時代的反向學習 這篇文章談過:AI 真正的價值不是讓你「學 AI」,是讓你把零散資訊整理成貼近個人脈絡的學習路徑,我們這個 App 就是把那個論點做成產品來驗證。
個人化的關鍵是脈絡檔案貫穿學習流程
跟學習者自己去問 ChatGPT 學習不同,我們發現 AI 沒有「學習者」這個對象,它知道怎麼寫一章「AI 入門」,但它不知道是要寫給旅行社老闆還是保險業前輩,雖然可以跟它講你的背景知識,但你沒跟它講它就不會知道,因此我們把流程拆成四個階段,每個階段都讀一份共同的脈絡檔案 intake.json,這份檔案在第一次訪談時就建立,五個必填維度:
- Topic(主題與範圍):要學什麼、明確排除什麼
- Learner Profile(學習者背景):已經知道什麼、有什麼相近經驗、有什麼自己也不確定的誤解
- Target Outcome(目標成果):可驗收的具體行為、確認學習是否有效
- Time Budget(時間預算):每週幾小時、總共幾週
- Application Context(應用脈絡):為什麼學、要用在哪
這份檔案接下來會被課綱設計、章節生成、聊天陪讀時會全部作為上下文讀取。保險業前輩寫了「客戶面談筆記知識庫+深度顧問文章」,課綱會自動把圖片生成、客服 bot 整章排除、把 NotebookLM 跟長文寫作流程拉到前面;旅行社老闆同一個欄位寫的是「行程文案自動化+LINE 客服自動回覆」,就會以自動化工具的介紹為主軸。
個人化不是模型有多聰明,是脈絡有沒有從頭貫穿到尾。
怎麼把 Claude Code 串接到 App 的聊天介面
這是一個 Tauri + React 的桌面 App,但它沒自己跑模型,前端是 chat-style 的閱讀器 UI,後端是 Claude Code 透過 MCP plugin 啟動的常駐 process,每個使用者訊息都包成一個 channel block 送進 Claude Code,Claude 處理完用 reply tool 把結果送回前端。

這個架構好處有三個:
- 不用自己接 LLM API——Claude Code 處理所有模型呼叫、tool use、subagent dispatch
- Skills 自動觸發——Claude Code 看 channel 的
kind欄位(intake / syllabus / chapter / reader)載入對應 skill - 長任務丟背景——章節生成要 60-90 秒,直接 dispatch 一個 background subagent,主 channel 繼續處理閱讀器聊天
最棒的是可以沿用你既有的 Claude Code 訂閱,其他類似的服務都要額外收 Token 費用。
把教學理論模組化成四個 Skill
如果你還不熟 Skills 是什麼,我們之前寫過 Claude Code Skills 入門教學 跟 Skill Creator 打造寫作 Skill 兩篇,這裡只談我們怎麼用 Skills 對應到學習設計的四個階段。
intake — 訪談接收脈絡
對應的教學方法是 Socratic 提問。學習者第一次打開 App 說「我想學 X」,intake skill 不會直接給課綱,而是用 Claude Code 內建的 AskUserQuestion 工具丟出選項題,把模糊的「我想學 AI」一層層追問成具體的 intake.json。

這個階段最容易踩的坑是接受模糊回答。如果只放一個對話框讓人打字,使用者寫「我會用 ChatGPT」AI 也只能照收,後面章節就寫得不上不下,只會丟問題的人跟試過寫 prompt、上傳檔案的人,需要的內容差很遠。
我們的解法不是事後追問,是在問題設計時就把模糊空間消除:訪談詢問學習者「對 AI 工具的熟悉程度?」直接給四個明確層級——零接觸/偶爾問問題、寫文案/會寫 prompt 上傳檔案/玩過 GPTs、Zapier 自動化——使用者只能挑最接近的那個,也能額外自行補充更完整的答案。
syllabus — 用 UbD 倒推設計課綱
syllabus skill 跑的是教學設計裡叫 UbD(Understanding by Design) 的「倒推法」,意思是課綱不從「第一章要教什麼」開始排,而是反過來先問「學完之後要會什麼具體的事」(例如「能把一份 PDF 行程改寫成適合 LINE 的短文案」),再問「怎麼確認他真的會了」(出題目讓他答、給一個沒看過的情境讓他做做看),最後才回頭排章節。
排章節用的是另一套理論 4C/ID 的精神:每一章都同時包含概念、範例、自己動手練三個部分,不會出現「先連續三章純講理論、最後才有一章練習」這種讀到一半就想放棄的結構。章節總數也不是憑感覺抓,是直接拿使用者填的「每週幾小時 × 預計幾週」算出總時數,回推塞得下幾章,如果他列的子題太多、時間根本不夠,課綱在送出前會明確告訴他:「這幾段我建議只帶過就好,要更深入學習需要更多時間」,而不是偷偷刪掉某幾段裝沒事。
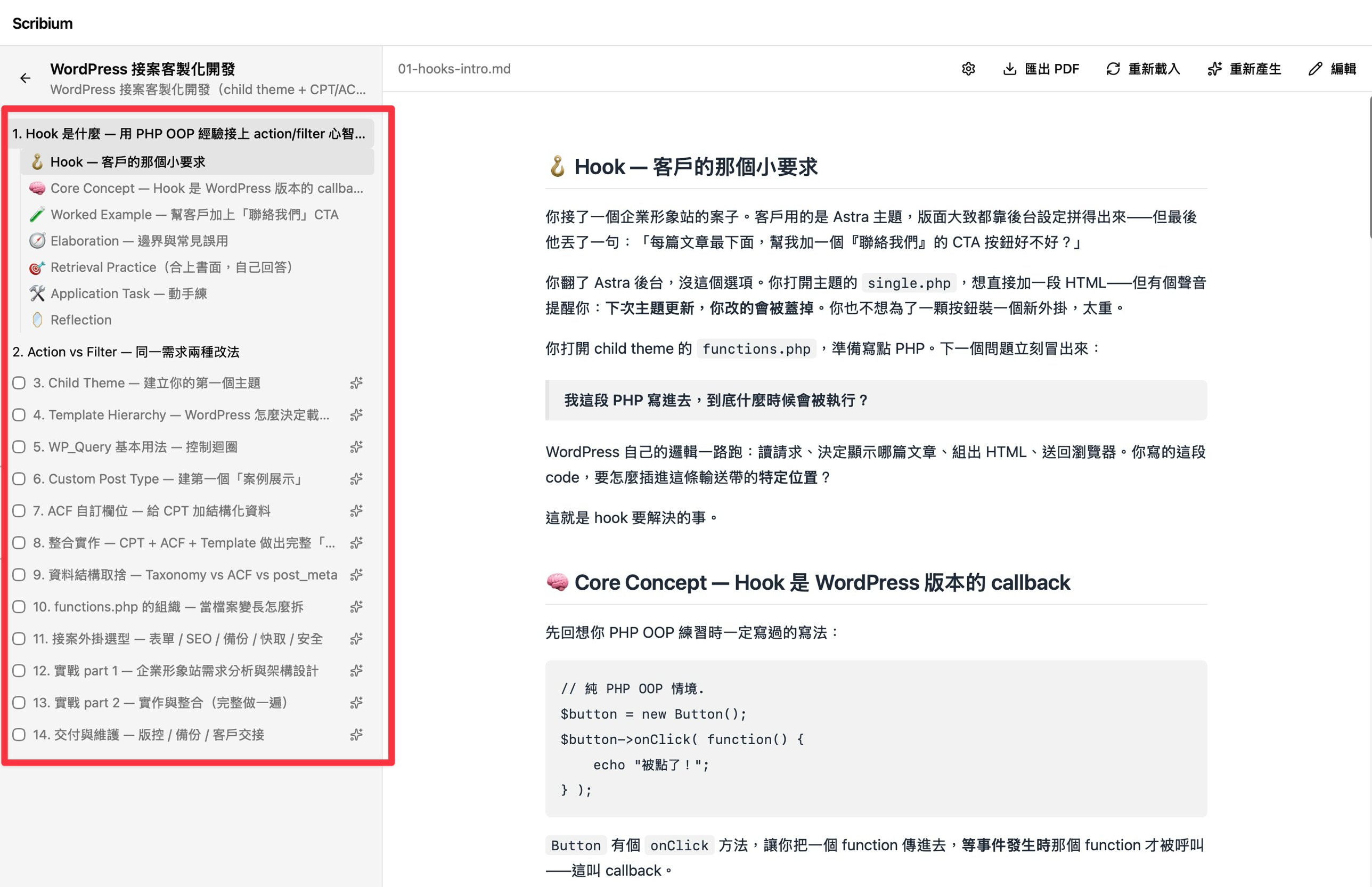
chapter — 章節生成的七段模板
實際讀的內容都是這個 skill 產出的,每章都遵循 4C/ID 的整體任務(whole-task)原則切成七段:
- 情境鉤子——用學習者實際工作會遇到的場景開場,不從定義開始
- 核心概念——簡潔定義,類比一定從學習者的相近經驗取材(intake 階段就收好了)
- 完整範例——一步一步走過一個例子,每步解釋為什麼這樣做、為什麼不那樣做
- 延伸補充——什麼時候不該用、常見的誤用、跟相近概念怎麼區分
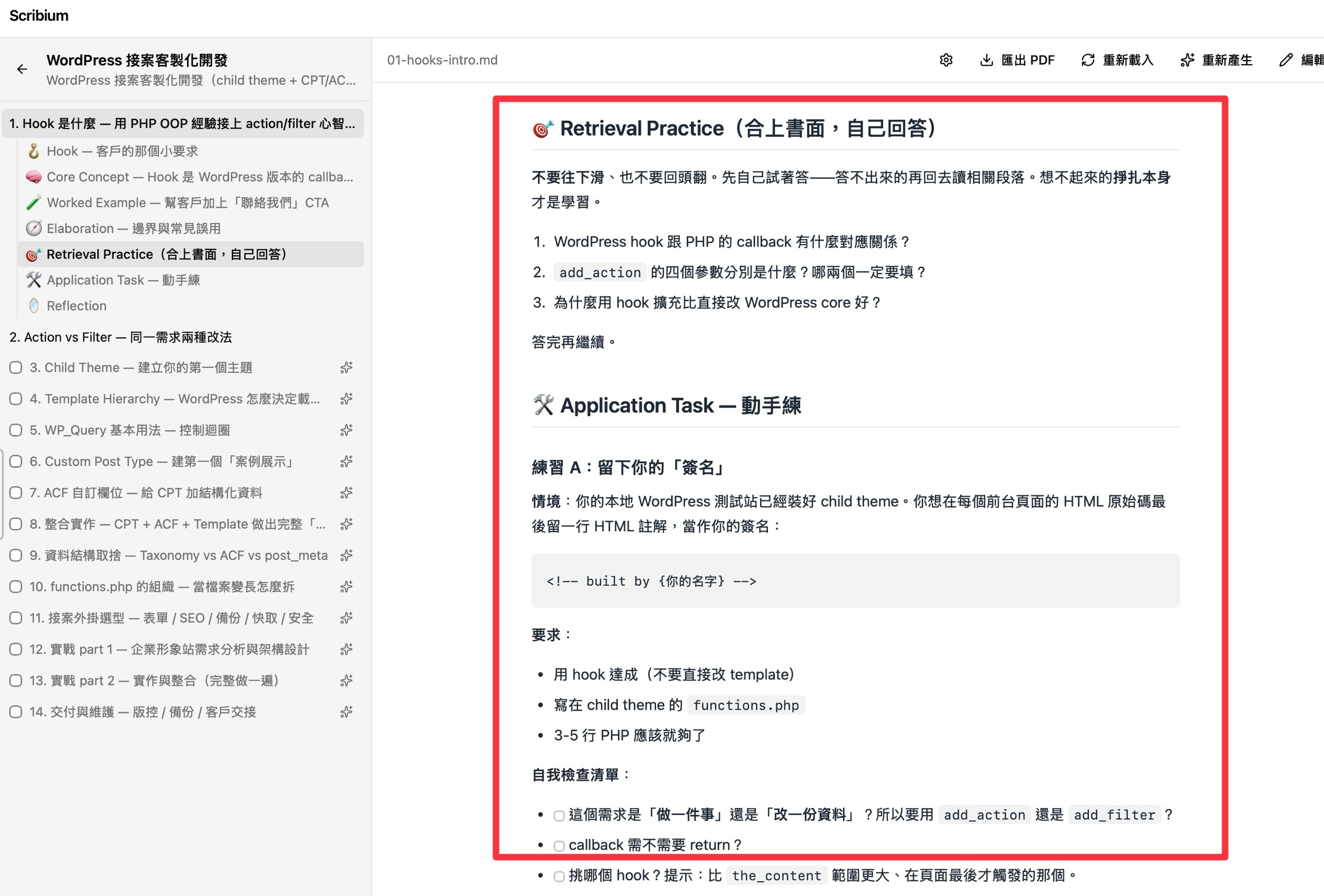
- 自我測驗——把 syllabus 階段就排好的題目逐條列出,請學習者合上書面自己回答
- 動手練習——把抽象任務擴寫成完整情境題,附自我檢查清單
- 收尾反思——用「你會怎麼用一句話跟外行解釋這章」這類問題收尾
裡面套了 Make It Stick(《超牢記憶法》)那本書講的六種記憶強化機制——自己回想、跨主題穿插、深度闡述、先試再教、間隔複習、情境變化——加上螺旋式學習:chapter skill 寫第三章之前會先讀完前兩章的完整內容,回顧已經用過的比喻跟術語,不重造新詞。
tutor — 閱讀過程的反問式陪讀
讀章節讀到一半卡住,學習者在 chat 介面提問。tutor skill 不會直接給答案,而是用三種方式回應:反問你「如果不是這樣會發生什麼事?」(蘇格拉底式)、要求你用更白話的方式重新講一次(費曼那套)、當你用了術語卻舉不出具體例子時溫和點破。
這個 skill 最關鍵的設計是把困惑寫進 progress.json——哪一章卡住、哪個概念說不清楚、自我測驗答對還是答錯。這份紀錄之後可以拿來排隔天的複習題,也可以在後面章節穿插回考前面的概念,避免學完就忘。
讀的過程也能改:chat 介面同時是編輯介面
個人化不會在訪談那一次就結束——讀章節的時候,學習者常常會發現:「這段太淺、我已經懂」、「這個例子跟我的工作對不上」、「這章沒提到的 X 我也想多學」。傳統線上課程到這裡就斷了,你只能跳過或硬讀。tutor 的 chat 介面留了兩個出口:
- 修改此段:選中章節中的某個段落,跟 tutor 說「這段太淺,請改用更進階的例子」或「請改用我們公司常見的情境」,它會把該段重寫、commit 回章節檔案,下次重新載入就是新版本。
- 追加章節:讀到一半發現課綱漏掉某個你想學的子題,直接說「我想多一章 X」,它會接住前面章節的概念脈絡,把新章節插進對的位置(先備依賴跟章節順序都自動排好),在背景產生內容。
- 餵自己的資料進去:手邊已經有的 PDF、會議筆記、原廠文件、學長學姊的整理稿——直接拖進 chat,跟 tutor 說「請把這些整理成我這套課程能讀的章節」。它會比對你的 intake 脈絡(程度、use_case、相近經驗)重寫一遍,把原本散亂的素材變成貼合你當下背景的教材,而不是叫你硬啃原文件。

這幾個動作背後其實是 tutor 跟其他 skill 的協作——對話判斷由 tutor 接收,實際的章節改寫、新增與順序重排丟給 Claude Code 的背景 subagent 處理,學習者在前端繼續讀、不用等。
讀者體驗起來只有一件事:個人化不會結束在第一次訪談,整本課程會持續貼合你當下的狀態,今天的疑惑可以變成明天章節的修訂,今天發現缺的子題可以變成明天的新章節。
想自己玩玩看?
這四個 skill(intake、syllabus、chapter、tutor)我們整理成一份 gist,你可以直接拿去你自己的 Claude Code 專案下試試看:
github.com/oberonlai/31df3e6c79f5f4ec406c7816eb8fb59c
最低可玩的設定就是把這幾份 SKILL.md 放進 .claude/skills/ 資料夾,配合一個簡單的 courses/ 目錄就能跑出第一份 intake.json 跟課綱骨架,如果你想做的不是學習工具,這份檔案也是「怎麼把方法論寫成一組分工明確的 skill」的參考實作。
延伸思考
這篇文章的結論建立在幾個前提上,值得進一步檢視:
- 使用者願意花 5-10 分鐘做訪談、且能誠實具體回答——對完全的初學者,他連自己想學什麼都說不清楚,選項題救不了 Dunning-Kruger 邊界
- 學習目標明確——對「探索式好奇心驅動」的學習(隨便逛、看看自己對什麼有興趣),脈絡檔案反而是過早收斂的限制
- 教學理論本身的有效邊界——UbD、4C/ID 建立在學科知識/認知負荷模型上,套到運動、藝術等程序性技能會卡:肌肉記憶、即時回饋這些維度它們處理不到
其他領域也有類似的設計模式:
- 軟體開發的 ADR(Architecture Decision Records)——
intake.json之於學習,等同 ADR 之於軟體:把為什麼決定做這個(不做那個)固化成檔案,後續所有產出都引用同一份文件作為對齊基準 - 醫療的 EMR + 個人化處方——五個訪談維度幾乎是病歷的同構映射,個人化醫療長年面對的挑戰(病人說不清楚症狀、跨階段資訊整合)跟個人化學習幾乎同構
- 產品設計的 user persona + JTBD——同一個產品給不同 persona 的 onboarding 不一樣,跟同一份課程對不同學習者展開不同章節是同個結構
關鍵概念:脈絡檔案貫穿設計、教學設計模組化、用 AI 反向學習
常見問題
Claude Code Skills 是什麼?跟一般的 prompt 有什麼不同?
Skills 是 Claude Code 的結構化能力擴充機制——一個資料夾加一份 SKILL.md,定義 AI 在特定任務上要遵循的規範、流程和檔案讀寫對象。跟一般 prompt 最大的差別是按需載入:Claude 看 frontmatter 的 description 判斷觸發時機,只在相關場景才讀這份 skill,不會跟其他任務的指令互相干擾。
為什麼不直接呼叫 Anthropic API,而要透過 Claude Code?
Claude Code 已經處理好我們需要的所有底層基礎:tool use 的 schema 管理、subagent 的背景任務分派、檔案讀寫權限、MCP plugin 的擴充協定。我們只要寫四個 SKILL.md 跟一個 MCP plugin,就能把整個學習流程跑起來,不用自己重做這些。
個人化學習一定要用 AI 嗎?傳統線上課程不能個人化嗎?
技術上可以,但人力成本撐不住——傳統個人化要嘛靠真人家教(一對一貴),要嘛靠自適應系統(規則寫死、彈性低),AI 把這兩個極端中間的空缺補起來,成本接近自適應系統,彈性接近真人家教,差別在你願不願意投資前期把脈絡檔案的設計做對。
用 UbD、4C/ID 這些教學理論的具體好處是什麼?
它們強迫設計者先回答兩個問題:「學會了長什麼樣?」(可展演的行為,不是「我懂 X」)、「怎麼證明學會了?」(retrieval question + application task)。這兩個問題沒答清楚,章節再花俏都會變成裝飾。把這些理論寫進 Skills 等於在 AI 產出時自動套用這個檢核流程。
這個 App 看起來很不錯,我要怎麼取得?
礙於 Anthropic 的使用者政策,目前該 App 的聊天系統可能會有所變動,等官方穩定下來並確認可以這樣串接時會再另行釋出!