LLM Wiki 實戰:我們怎麼把部落格變成一座知識庫
AI 文章延伸
選擇平台後可直接帶入閱讀脈絡,快速整理重點、補齊盲點,並延伸到同站相關文章。

我從沒想過,自己寫的文章有一天會被 AI 質疑。
上面這張截圖是我們知識庫裡的一筆編譯資料,AI 對一篇舊文章的「質疑」結果,那篇文章的結論是「WordPress 是 Vibe Coding 的最佳落地平台」,AI 讀完之後反問:如果產品是行動應用、SaaS 或資料密集型服務呢?Shopify App Store 和 Chrome Extension Store 不也提供類似的商業化基礎設施?
這些反問不是在否定原文,而是在標記它的適用邊界。我寫那篇文章時壓根沒想到這些前提假設,但知識庫裡現在清楚記錄著:這個結論成立的條件是什麼,不成立的條件又是什麼。
這就是讓 AI 「編譯」你的文章跟單純讓 AI 「整理筆記」最大的差別——它不只壓縮資訊,還會生產新的洞察。
Karpathy 的 LLM Wiki 改變了什麼
2026 年 4 月初,Andrej Karpathy(OpenAI 共同創辦人)公開了一套他自己在用的知識管理方法,叫 LLM Wiki,核心概念一句話就能講完:別在提問時才讓 AI 翻原始文件,讓它提前把所有資料「編譯」成結構化的 Wiki。
這裡的「編譯」不是寫程式的那種編譯,想像你有一箱雜亂的筆記,每次要找資料都得整箱翻,Karpathy 的做法是讓 AI 先把這箱筆記整理成一本有目錄、有索引、有交叉引用的百科全書,之後要查什麼翻百科就好。
傳統做法(包括 NotebookLM、ChatGPT 的檔案上傳)都是「即時檢索」——每次問問題,AI 現場搜、現場讀、現場拼答案,這就是為什麼同一個問題問兩次答案可能不同,因為每次搜到的段落不一樣,拼出來的理解也不一樣。
LLM Wiki 反過來:先編譯,再查詢。概念定義只有一份,矛盾在編譯時就被標記,新資料加入時做增量更新,知識變成了一個持久的資產,而不是每次對話的副產品。
看完這個概念,我決定拿我們的部落格來試。
我們加了什麼:三步編譯法
Karpathy 的原始方案主要做「摘要 + 提取概念 + 建索引」,但純摘要有一個問題——兩篇觀點相反的文章,摘要後可能看起來一樣,摘要只壓縮資訊,不生產新知識。
我們參考了餅乾哥哥 AGI 的三步編譯法,在摘要的基礎上加了質疑和對標兩個步驟:
第一步:濃縮
用剃刀法則處理每篇文章——「刪掉這條資訊,會影響理解嗎?」不會就刪,最後只留核心結論(不超過三條)和支撐每條結論的關鍵證據。
一篇 3000 字的文章濃縮後通常剩 200 字左右,那 2800 字不是廢話,但它們是脈絡和細節,不是核心知識。
第二步:質疑
這是跟 Karpathy 方案最大的差異,對每條核心結論問四個問題:
- 這個結論依賴哪些前提假設?
- 換個產業、換個規模,還成立嗎?
- 資料來源可靠嗎?
- 有沒有沒提到的反例?
舉個我們自己的例子,有一篇文章說「導入 AI 開發流程後,專案時間從 2-3 個月縮短到 3-4 週」,質疑步驟指出這個數據的前提是「團隊已經有 WordPress 開發經驗」。如果是一個對 WordPress 完全陌生的團隊,AI 加速效果會大打折扣,因為你連 AI 產出的程式碼對不對都無法判斷。
沒有質疑這一步的話,「縮短到 3-4 週」就會作為孤立事實留在知識庫裡,下次被引用時可能誤導判斷。
第三步:對標
跨領域找類似現象,這一步聽起來有點抽象,但實際跑出來的結果讓我們很驚訝。
編譯一篇講「用 Paperclip 打造 AI 虛擬公司」的文章時,對標步驟拉出了康威定律(Conway’s Law)——組織結構決定系統架構。那篇文章裡的 AI 團隊編制是 CEO、PM、設計師、工程師、QA,直接複製了人類公司的組織結構,但 AI 的協作模式可能需要完全不同的組織設計,CEO 角色的失敗可能正是因為人類的階層管理邏輯不適用於 AI 團隊。
我寫那篇文章時只在記錄「AI 虛擬公司好不好玩」,完全沒想過這跟六十年前的軟體工程定律有關。但 AI 把這兩件事放在一起,讓我重新理解了一件事:我們設計 AI 工作流時,很容易不自覺地套用人類組織的思維模式,而這可能正是效果不好的原因。
編譯完成後,我們得到了什麼
六組 AI agent 平行處理,不到一小時跑完所有文章,產出的東西超出預期:
- 上百個概念條目——從「AI 工具的累積效應」到「康威定律」到「冷啟動問題」,每個概念都有定義、關鍵數據點、前提與局限性、關聯概念
- 十多個方法論——像是「Spec Coding 方法論」「痛點量化驅動設計」「接案養產品雙軌模式」,把散落在不同文章裡的操作步驟整理成可複用的流程
- 每篇文章一份編譯摘要——都經過濃縮、質疑、對標三步處理
我們把這些編譯結果做成了一個線上知識庫,可以按概念、方法論、編譯摘要分類瀏覽,也有關聯圖譜可以看概念之間的連結:
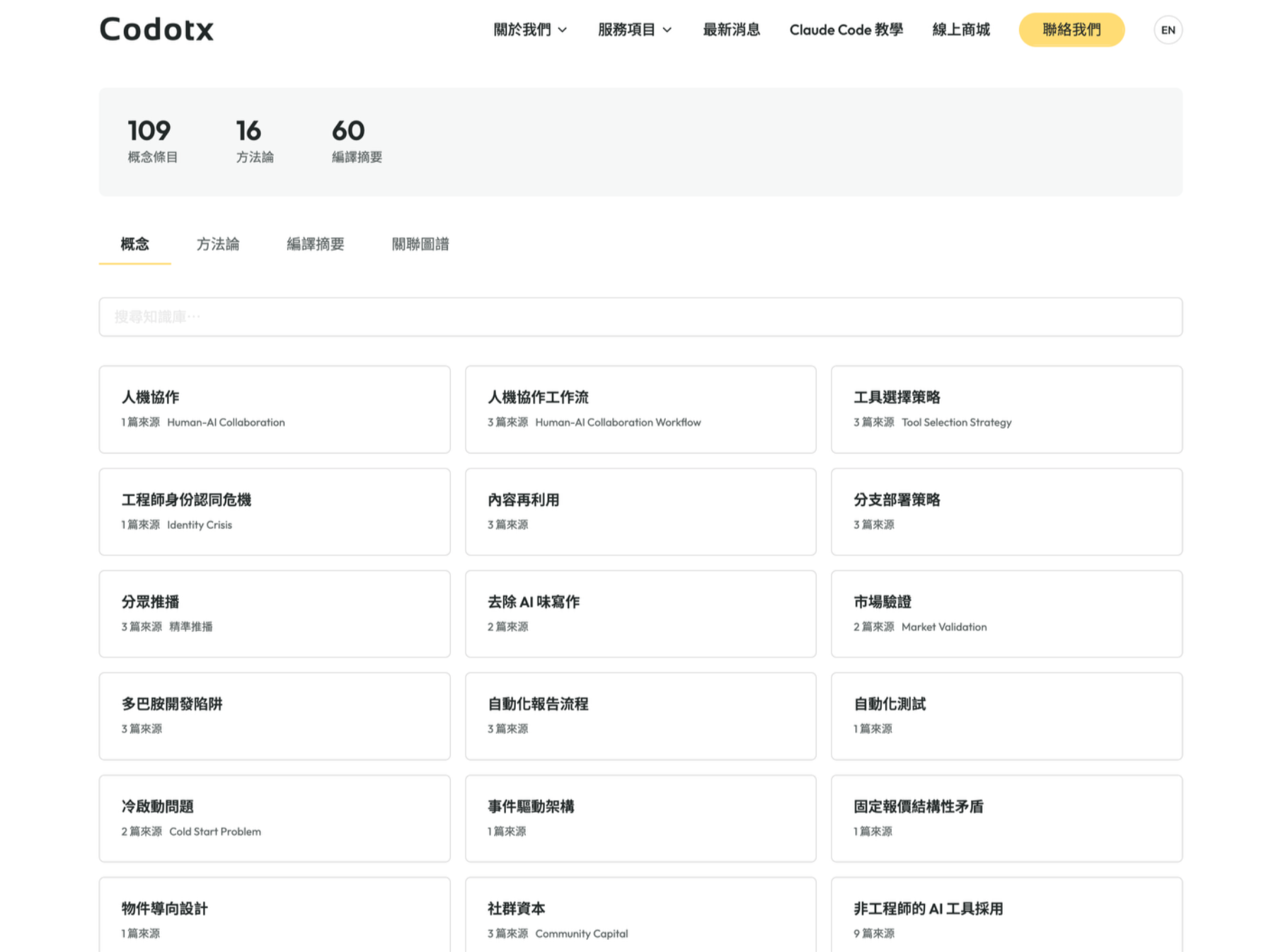
點進任何一個概念條目,可以看到定義、來源文章、跨文章觀察和關聯概念,左側是完整的階層目錄,右側是頁面內的標題導覽:
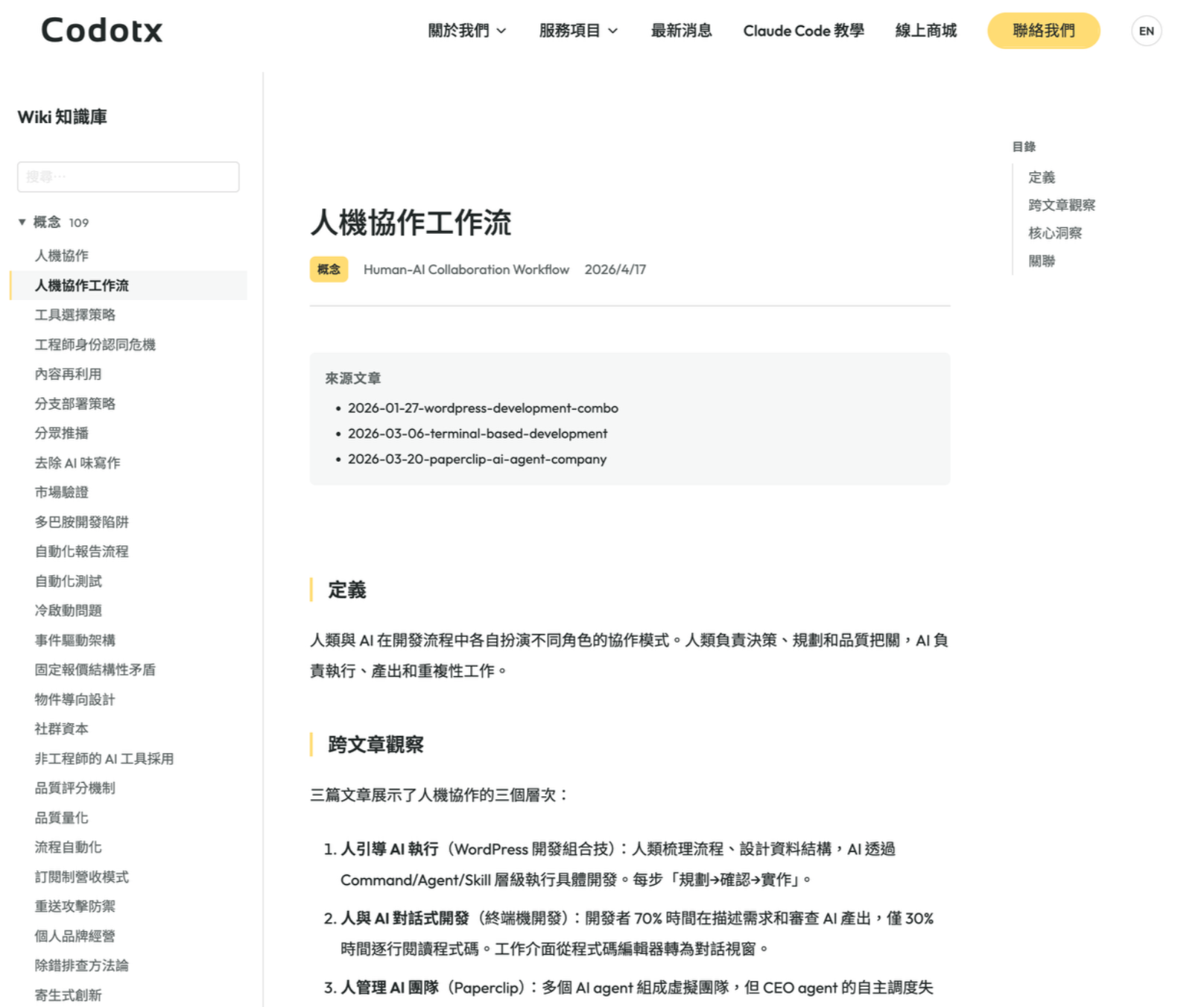
切換到「關聯圖譜」,可以看到所有概念之間的連結關係,圓點越大代表被越多文章引用,連線代表概念之間有交叉引用:
但最有價值的不是介面,是跨文章的關聯。
我們的文章橫跨多個分類:Claude Code 教學、技術分享、工具評測、產品更新、公司公告,這些分類在部落格上是獨立的,但編譯後概念之間出現了意料之外的連結。
「AI 工具的累積效應」這個概念同時被 Claude Code 記憶系統、Skill 系統、Session 管理三個不同主題的文章引用,編譯後它們匯聚成一個觀點:AI 工具的價值不在單次使用,在於持續投入後形成的複利——但這個複利同時也製造了遷移成本。我們自己的文章裡就有這個張力,一邊說「累積效應讓你領先」,一邊說「工具選擇是工程判斷,隨時可以換」,知識庫裡直接標記了這個衝突。
公告類文章(月度回顧、年度回顧、活動紀錄)看起來是最沒有「知識含量」的分類,但編譯後拉出了公司第一年的完整發展弧線:從 Vibe Coding 帶來的興奮、四款產品的連續失敗、WordCamp 的策略轉向,到最後務實選擇接案養產品。這條脈絡散落在不同時間的文章裡,從來沒有人把它們串在一起看過。
知識庫反過來幫助寫作
建完知識庫之後,我們的寫作流程多了一個步驟。現在每次寫新文章,在動筆之前會先查 Wiki:這個主題跟哪些既有概念相關?有沒有已知的衝突需要處理?有沒有跨域洞察可以作為獨特切入點?
更重要的是,Wiki 改變了我們組織文章的方式。以前寫文章是從零開始想結構,現在知識庫裡已經有現成的「概念條目」和「對標結果」可以引用——寫這篇文章之前,Wiki 告訴我「AI 工具的累積效應」跟「內容再利用」兩個概念都跟 LLM Wiki 相關,知識庫本身就是一種累積型資產,而把部落格編譯成知識庫也是一種內容再利用,這些連結不是硬想出來的,是知識庫裡現成的。
寫完新文章後跑一次「編譯」,把新文章的知識回寫到 Wiki,知識庫就這樣持續滾動,每一篇新文章都讓整個知識網絡變得更密。
你的文章值得被編譯嗎
如果你也在經營部落格或寫技術文章,可以問自己一個問題:你有多少篇文章寫完之後就再也沒被引用過?
那些文章不是沒價值。它們的價值被「散落」稀釋了。每篇文章獨立存在,像一座座孤島。讀者看完一篇就離開,不會發現你在另一篇文章裡寫過一個完全互補的觀點。
LLM Wiki 做的事情,是把這些孤島連成一片大陸。
不需要很多文章才能開始。10 篇就夠了。重點不是量,是讓 AI 去發現那些你自己沒注意到的連結——「原來這兩篇在講同一件事」「原來這篇的前提假設已經被另一篇推翻了」。
那些連結,就是新文章的靈感來源。
延伸思考
這篇文章的觀點建立在幾個前提上,值得進一步思考:
- 文章之間需要有主題交叉——如果你的內容都集中在同一個狹窄領域,對標步驟能產出的跨域洞察有限,濃縮反而是最有價值的步驟
- AI 的質疑品質取決於它的知識廣度——對於非常利基的產業知識,AI 可能只能提出表面的問題,無法指出真正關鍵的前提假設
其他領域也有類似的現象:
- 開源複利效應——知識庫的累積模式跟開源專案一樣,早期投入看不到回報,但隨著概念條目增加,每篇新文章的編譯都能觸發更多連結,價值加速成長
- SSOT(Single Source of Truth)——把文章編譯成概念條目,本質上是把「來源」和「衍生物」分離,文章是來源,概念是衍生物,兩者保持連結但各自演化
關鍵概念:LLM Wiki 知識編譯、AI 輔助寫作流程、Claude Code Skill 系統、康威定律
常見問題
LLM Wiki 跟 NotebookLM 有什麼不同?
NotebookLM 是「即時檢索」——每次提問時 AI 現場搜尋你上傳的文件。LLM Wiki 是「預先編譯」——AI 先把所有資料整理成結構化的概念條目和交叉引用。兩者最大的差別在一致性:LLM Wiki 裡同一個概念只有一個定義,NotebookLM 則可能每次給你不同的整理結果。
不會寫程式也能建 LLM Wiki 嗎?
LLM Wiki 的核心是 Markdown 檔案和資料夾結構,不需要寫任何程式碼。你需要的是一個能跑 AI agent 的工具(像 Claude Code)和一個文字編輯器。編譯的過程完全由 AI 執行,你只負責把原始資料放進指定資料夾,然後下一句指令。
多少篇文章才值得建知識庫?
10 篇以上就有意義了。關鍵不是數量,而是主題有沒有交叉。如果你的文章都在談同一個狹窄的主題,編譯後的概念條目會比較少。但如果你像我們一樣橫跨技術、商業、工具評測等不同領域,概念之間的跨域連結會是最有價值的產出。
Google 偏好來源
喜歡我們的內容嗎?一鍵將我們設為偏好來源,未來在 Google 焦點新聞與 AI 概覽中就能優先看到我們的文章。