如何使用 Claude Code 自動產出 SEO 週報
AI 文章延伸
選擇平台後可直接帶入閱讀脈絡,快速整理重點、補齊盲點,並延伸到同站相關文章。
經營技術部落格一段時間後,我們發現自己很少主動去看 Google Search Console。不是不想看,是每次都要登入後台、點來點去、手動比較數據,久了就懶了。但 SEO 數據其實藏著很多寶貴資訊——哪些關鍵字有人在搜、哪些頁面帶來最多流量、哪些主題值得寫更多文章。
所以我們決定:寫一個腳本,每週一早上自動從 GSC API 撈數據,產出一份 Markdown 週報,打開就能看。
我們想要的報告長什麼樣
動手之前先想清楚報告該包含什麼。我們定了四個區塊:
- 關鍵字排名 Top 20 — 哪些搜尋字詞帶來最多點擊
- 頁面導流排名 Top 15 — 哪些頁面是流量主力
- 內容機會分析 — 高曝光但低點擊的關鍵字,代表搜尋需求存在但我們的內容還沒接住
- 本週總覽 — 總點擊、總曝光、平均 CTR 等摘要數字
第三點是我認為最有價值的部分。一個關鍵字如果曝光 300 次但只被點了 1 次,要嘛排名太後面,要嘛標題不吸引人,要嘛根本沒有對應的文章。不管是哪種情況,都是可以改善的機會。
前置準備:用 gcloud 建立 API 存取
要從程式存取 GSC,需要一個 Google Cloud 的 Service Account。整個設定用 gcloud CLI 就能完成,不用進 Google Cloud Console 的網頁介面。
建立 GCP 專案
gcloud projects create codotx-gsc --name="Codotx GSC"建議為這個用途開一個獨立專案,跟其他 GCP 資源分開管理。
啟用 Search Console API
gcloud config set project codotx-gsc
gcloud services enable searchconsole.googleapis.com建立 Service Account
gcloud iam service-accounts create gsc-reader --display-name="GSC Reader"下載金鑰
gcloud iam service-accounts keys create gsc-credentials.json \
[email protected] \
--project=codotx-gsc這會在當前目錄產生一個 gsc-credentials.json,Python 腳本會用這個檔案來驗證身份。記得把它加進 .gitignore,千萬不要 commit 進版本庫。
# .gitignore
gsc-credentials.json四個指令,API 端的設定就完成了。
在 GSC 後台授權 Service Account
API 端設好了,但 GSC 那邊還不認識這個 Service Account。需要到 Google Search Console 後台手動加一次。
進入 設定 → 使用者和權限,你會看到目前的使用者清單:
點「新增使用者」,輸入 Service Account 的 email:
[email protected]權限選「限制」就夠了,我們只需要讀取數據。
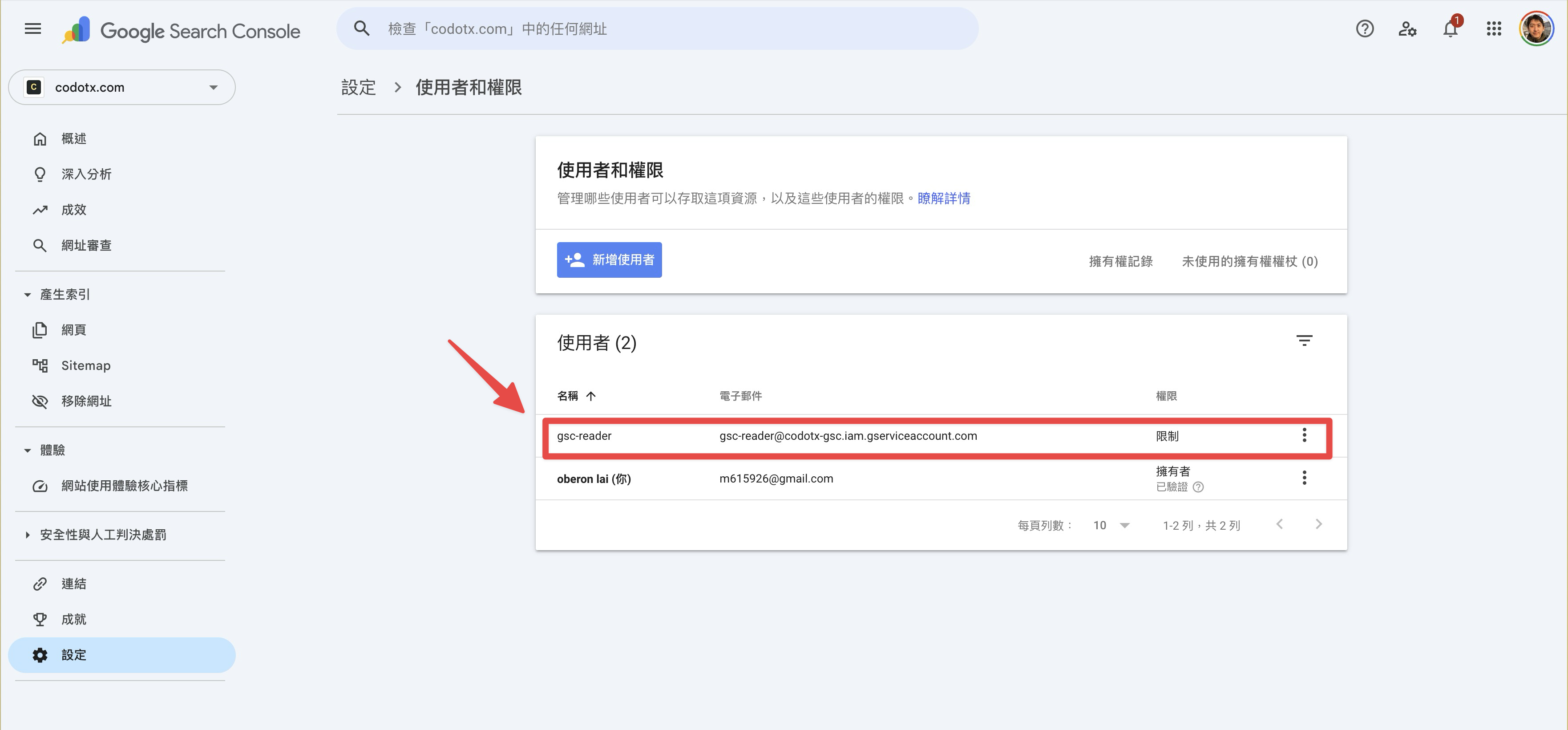
加完之後,使用者清單會多出 gsc-reader 這筆,狀態顯示為「限制」權限。到這邊,API 跟 GSC 的連線就建立好了。
撰寫查詢腳本
安裝 Python 套件:
pip3 install google-api-python-client google-auth腳本的核心是透過 searchanalytics().query() 來查詢數據。這個 API 支援多種 dimension(query、page、date、country 等),可以根據不同維度來拆分數據。
我們對同一個日期範圍發了三次查詢:
# 1. 關鍵字排名(依點擊數排序)
keywords = query_gsc(service, start_date, end_date, ['query'], 50, 'clicks')
# 2. 頁面排名(依點擊數排序)
pages = query_gsc(service, start_date, end_date, ['page'], 30, 'clicks')
# 3. 內容機會(依曝光數排序,後續再篩選)
all_keywords = query_gsc(service, start_date, end_date, ['query'], 100, 'impressions')第三個查詢拿到所有高曝光的關鍵字後,用條件篩選出「內容機會」。
一開始我們用固定門檻(曝光 >= 50 算高優先、>= 20 算中優先),但馬上發現問題:對一個新站來說,一週 50 次曝光的關鍵字可能根本沒幾個;等流量長起來後,50 次又變得不值一提。固定數字沒辦法適應不同規模的網站。
最後我們採用混合制——先設最低門檻過濾噪音,通過門檻的再用百分位數分級:
MIN_IMPRESSIONS = 20 # 週曝光低於 20 的直接忽略.
# 篩選:通過最低門檻,且 CTR 低於全站平均或排名低於全站平均.
qualified = [r for r in all_keywords if r['impressions'] >= MIN_IMPRESSIONS]
avg_ctr = sum(r['clicks'] for r in qualified) / sum(r['impressions'] for r in qualified)
avg_pos = sum(r['position'] for r in qualified) / len(qualified)
opportunities = [
r for r in qualified
if r['ctr'] < avg_ctr or r['position'] > avg_pos
]
# 用百分位數動態分級.
imp_values = sorted([r['impressions'] for r in opportunities])
p75 = percentile(imp_values, 75) # 前 25% = 高優先.
p50 = percentile(imp_values, 50) # 前 25%~50% = 中優先.這個做法的好處是門檻會隨著網站流量自動調整。報告裡也會標出本週的實際門檻值,讓你知道「高優先」這週代表的是曝光幾次以上。
分級結果:
- 高優先(曝光前 25%)— 搜尋量在你的網站中相對最大,值得專門寫一篇文章
- 中優先(曝光前 25%~50%)— 有一定搜尋量,可以優化現有內容或在相關文章中補充
- 潛力關鍵字(通過最低門檻但排名較後)— 早期訊號,持續觀察趨勢
報告日期範圍
報告自動計算「上週一到上週日」的完整七天:
days_since_monday = today.weekday()
last_monday = today - timedelta(days=days_since_monday + 7)
last_sunday = last_monday + timedelta(days=6)這樣每週一執行時,拿到的永遠是上一個完整週的數據,不會有不完整的天數。
產出格式
最後把所有數據組成 Markdown 表格,寫入 reports/gsc-weekly-YYYY-MM-DD.md。選 Markdown 而不是 CSV 或 HTML,是因為在終端機、GitHub、筆記軟體裡都能直接閱讀,不需要額外工具。
完整腳本放在 scripts/gsc-weekly-report.py,手動執行一次確認沒問題:
python3 scripts/gsc-weekly-report.py如果 API 連線正常,會看到:
Report generated: reports/gsc-weekly-2026-03-10.md設定每週自動執行
腳本能跑了,最後用 cron 排程讓它每週一早上 10 點自動執行:
crontab -e加入這行:
# codotx.com GSC 週報 - 每週一上午 10:00 執行
0 10 * * 1 /usr/local/bin/python3 /path/to/scripts/gsc-weekly-report.py >> /path/to/reports/cron.log 2>&1注意幾個細節:
- 用絕對路徑指定
python3和腳本位置,cron 的 PATH 環境跟你的 shell 不一樣 - 把 stderr 導到 log 檔,萬一執行失敗有紀錄可查
* * 1的1代表星期一(0 是星期日)
報告實際長什麼樣
產出的週報會長這樣:
關鍵字排名:
| # | 關鍵字 | 點擊 | 曝光 | CTR | 平均排名 |
|---|---|---|---|---|---|
| 1 | line flex message | 6 | 97 | 6.2% | 4.7 |
| 2 | line user id 查詢 | 6 | 12 | 50.0% | 3.3 |
| 3 | flex message | 4 | 116 | 3.4% | 6.8 |
| 4 | line login | 4 | 296 | 1.4% | 6.9 |
| 5 | line notify 替代方案 | 4 | 55 | 7.3% | 4.2 |
內容機會分析:
篩選條件:週曝光 >= 20,且 CTR 低於全站平均或排名低於全站平均 本週門檻:高優先 >= 206 曝光、中優先 >= 76 曝光
高優先(>= 206 曝光,前 25%):
| 關鍵字 | 曝光 | 點擊 | CTR | 排名 |
|---|---|---|---|---|
| line notify | 347 | 1 | 0.3% | 9.9 |
| line login | 296 | 4 | 1.4% | 6.9 |
中優先(76~205 曝光):
| 關鍵字 | 曝光 | 點擊 | CTR | 排名 |
|---|---|---|---|---|
| flex message | 116 | 4 | 3.4% | 6.8 |
| ai 圖像辨識網站 | 76 | 0 | 0.0% | 10.3 |
跟一開始用固定門檻的版本比,原本列出 18 個「機會」,混合制篩到只剩 7 個。數量少了但每個都更值得投入。例如「line notify」曝光 347 次但只被點了 1 次,排名在第 10 名左右,寫一篇完整教學搶進前 5 名,流量成長空間很大。而像「ai 圖像辨識網站」曝光 76 次、完全沒被點擊,代表有搜尋需求但我們沒有對應內容,是一個明確的內容缺口。
整體需要的工具
回顧一下,實現這個自動週報需要以下工具:
- gcloud CLI — 建立 GCP 專案、啟用 API、建立 Service Account
- Google Search Console — 在後台授權 Service Account 讀取權限
- Python + google-api-python-client — 查詢 Search Analytics API、產出 Markdown 報告
- cron — 每週一自動執行腳本
設定完成後,每週一早上報告就會自動出現在 reports/ 資料夾裡。不用登入任何後台,打開檔案就能看到上週的 SEO 表現和下一步該寫什麼文章。
對我們來說,這份報告最實用的部分是內容機會分析。它把「猜測讀者想看什麼」變成了「數據告訴你讀者在搜什麼」,寫文章的方向清楚很多。更進一步,每週一早上拿到報告後,我們會直接把內容機會丟給 AI,請它根據這些高曝光、低點擊的關鍵字來撰寫對應的文章。從數據採集到內容產出,整條流程都能在同一個早上完成。